本帖最后由 hahhahah 于 2023-08-26 20:20 编辑
Whisper 模型是由 Alec Radford、Jong Wook Kim、Tao Xu、Greg Brockman、Christine McLeavey、Ilya Sutskever在《通过大规模弱监督实现的鲁棒语音识别》中提出的。
论文摘要如下:
我们研究了经过简单训练来预测互联网上大量音频转录的语音处理系统的能力。当扩展到 680,000 小时的多语言和多任务监督时,生成的模型可以很好地推广到标准基准,并且通常可以与之前的完全监督结果竞争,但在零样本迁移设置中无需任何微调。与人类相比,模型的准确性和稳健性接近人类。我们正在发布模型和推理代码,作为进一步开展鲁棒语音处理工作的基础。
尖端:
该模型通常表现良好,无需任何微调。
该架构遵循经典的编码器-解码器架构,这意味着它依赖于generate()函数进行推理。
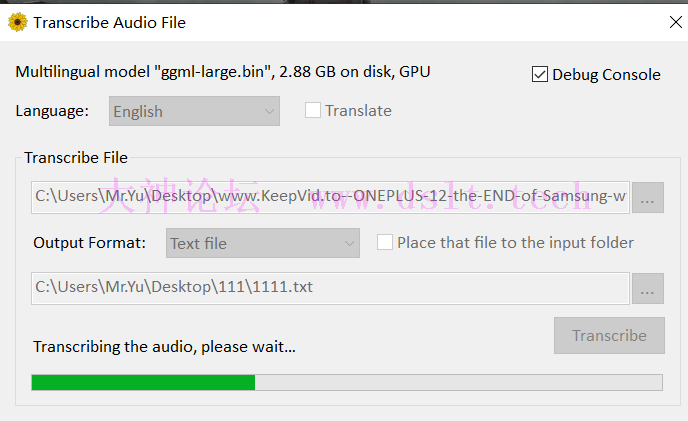
目前仅针对短格式实现推理,即音频被预先分割成 <= 30 秒的片段。长格式(包括时间戳)将在未来版本中实现。
人们可以使用WhisperProcessor为模型准备音频,并将预测的 ID 解码回文本。

下方隐藏内容为本帖所有文件或源码下载链接:
游客你好,如果您要查看本帖隐藏链接需要登录才能查看,
请先登录
|
 发表于 2023-08-26 20:20
发表于 2023-08-26 20:20
 发表于 2024-01-23 15:54:59.0
发表于 2024-01-23 15:54:59.0





 评分
评分 顶
顶 踩
踩 扫码赞助
扫码赞助