本帖最后由 vlricchen 于 2023-11-25 11:16 编辑
花指令本文重点标题: - 原理—反编译器的线性反编译(理解花指令的重点)※
- 原理—对于出题人
- 栈指针平衡(引子)
- 花指令分类—进阶花指令(自定义花指令)
- 花指令分析实操
- 花指令练习※
- 编写脚本自动化去除花指令
前言:因为备课的时间比较短,笔者之前又没有系统学习整理过花指令,所以该篇略微混乱。但对于初学者来说仍是很好的阅读资料,笔者下次讲课时会再仔细整理的有条理一些。 对初学者说的话:时间比较紧的初学者建议阅读完原理直接转到文中较为偏后的花指令分类及花指令练习阅读,当然还是建议完整阅读完本文,你会有很大的收获。 对出题人说的话:对于像我一样只会做题不会出题的师傅,建议直接阅读文中较为偏后的花指令练习部分,里面重点阐述了如何由编写含有花指令的程序到反汇编分析花指令程序,并且该部分含有些我自己的一些出题的理解和思路及一些对疑问的解答,阅读完该部分后你也可以完成独立出题的工作。 为了使目录稍微完整,笔者在花指令练习里已经出现过的IDC脚本自动去花又加在了后面的目录中,意图是使脚本自动去花更为醒目一些防止读者学习时的遗漏。
关于指令类型推荐阅读如下两篇 https://blog.csdn.net/abel_big_xu/article/details/117927674 https://blog.csdn.net/m0_46296905/article/details/117336574 概念花指令是企图隐藏掉不想被逆向工程的代码块(或其它功能)的一种方法, 在真实代码中插入一些垃圾代码的同时还保证原有程序的正确执行, 而程序无法很好地反编译, 难以理解程序内容, 达到混淆视听的效果。 花指令通常用于加大静态分析的难度。 原理反编译器的线性反编译(理解花指令的重点)反编译器的工作原理是,从exe的入口AddressOfEntryPoint处开始,依序扫描字节码,并转换为汇编,比如第一个16进制字节码是0xE8,一般0xE8代表汇编里的CALL指令,且后面跟着的4个字节数据跟地址有关,那么反编译器就读取这一共5个字节,反编译为CALL 0x地址 。 对应的,有些字节码只需要一个字节就可以反编译为一条指令,例如0x55对应的是push ebp,这条语句每个函数开始都会有。同样,有些字节码又需要两个、三个、四个字节来反编译为一条指令。 也就是说,如果中间只要一个地方反编译出错,例如两条汇编指令中间突然多了一个字节0xE8,那反编译器就会将其跟着的4个字节处理为CALL指令地址相关数据给反编译成一条CALL 0x地址指令。但实际上0xE8后面的四个字节是单独的字节码指令。这大概就是线性反编译。 线性扫描和递归下降线性扫描:
线性扫描的特点:从入口开始,一次解析每一条指令,遇到分支指令不会递归进入分支。 递归下降:
当使用线性扫描时,比如遇到call或者jmp的时候,不会跳转到对应地址进行反汇编,而是反汇编call指令的下一条指令,这就会导致出现很多问题。
递归下降分析当遇到分支指令时,会递归进入分支进行反汇编。 使反汇编引擎解析错误X86指令集的长度是不固定的,有一些指令很短,只有1个字节,有些指令比较长,可以达到5字节,指令长度不是固定的。如果通过巧妙的构造,引导反汇编引擎解析一条错误的指令,扰乱指令的长度,就能使反汇编引擎无法按照正常的指令长度一次解析邻接未解析的指令,最终使反汇编引擎输出错误的反汇编结果。 机器码0xE8 CALL 后面的四个字节是地址 0xE9 JMP 后面的四个字节是偏移 0xEB JMP 后面的二个字节是偏移 0xFF15 CALL 后面的四个字节是存放地址的地址 0xFF25 JMP 后面的四个字节是存放地址的地址 0x68 PUSH 后面的四个字节入栈 0x6A PUSH 后面的一个字节入栈 对于出题人从出题人的角度来看,构造有效花指令的关键思路就是构造使源程序逻辑不受影响的内联汇编代码,同时在内联汇编代码中嵌入jmp call+ret之类的对应机器码指令,使反汇编软件在反汇编时错误地识别这些机器码为汇编指令,从而影响反汇编出来的程序的正常流程。 写花指令的原则保持堆栈的平衡 常用指令含义push ebp ----把基址指针寄存器压入堆栈
pop ebp ----把基址指针寄存器弹出堆栈
push eax ----把数据寄存器压入堆栈
pop eax ----把数据寄存器弹出堆栈
nop -----不执行
add esp,1-----指针寄存器加1
sub esp,-1-----指针寄存器加1
add esp,-1--------指针寄存器减1
sub esp,1-----指针寄存器减1
inc ecx -----计数器加1
dec ecx -----计数器减1
sub esp,1 ----指针寄存器-1
sub esp,-1----指针寄存器加1
jmp 入口地址----跳到程序入口地址
push 入口地址---把入口地址压入堆栈
retn ------ 反回到入口地址,效果与jmp 入口地址一样
mov eax,入口地址 ------把入口地址转送到数据寄存器中.
jmp eax ----- 跳到程序入口地址
jb 入口地址
jnb 入口地址 ------效果和jmp 入口地址一样,直接跳到程序入口地址
xor eax,eax 寄存器EAX清0
CALL 空白命令的地址 无效call 栈指针平衡(引子)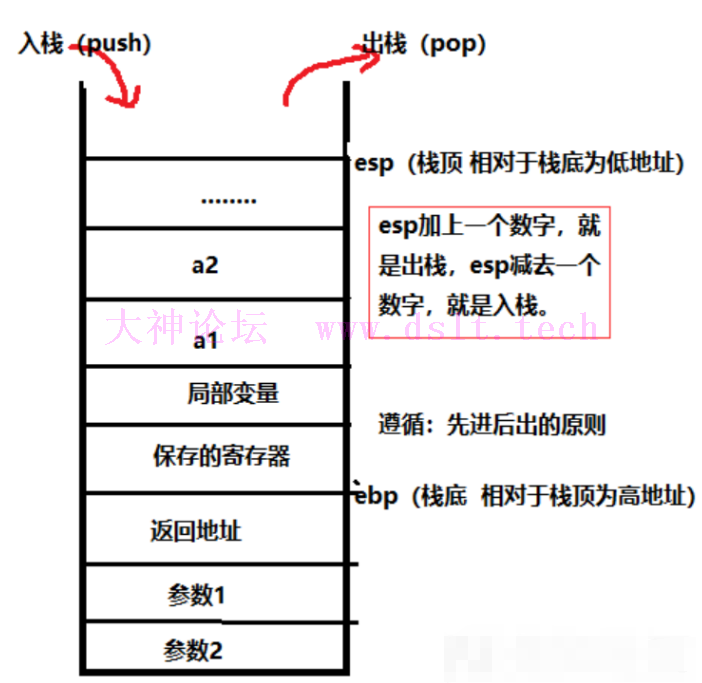
当使用IDA分析伪代码时,有花指令会发生 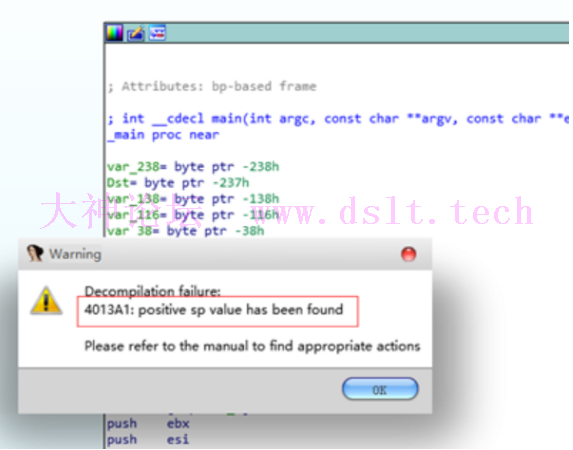
无法查看伪代码 需要去给出的地址查看具体发生的问题 这里,我们要设置一下IDA,让它显示出栈指针 (Options-General-Disassembly-"Stack pointer")
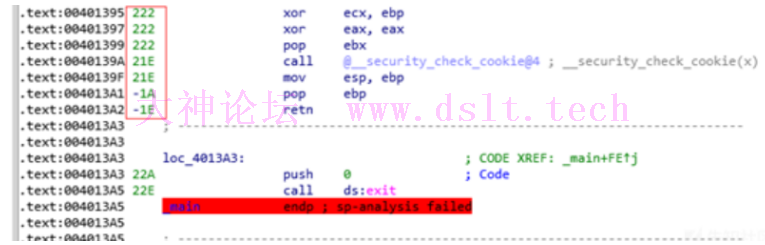
程序段结束后,不应发生mov esp,ebp的操作,因为在pop出栈后,esp和ebp的值相等,这一步是多余的,因为栈指针已经正确地回到了调用函数前的位置,这会引起栈指针不平衡。 这就需要修改栈指针 手动修改地址注意:每条语句前的栈指针是这条语句未执行的栈指针。
找到函数段的开始地址 
计算结束地址的栈指针应为多少: 0x21E-0x4 = 0x21A 修改最后两句应为的栈指针: Alt+k: 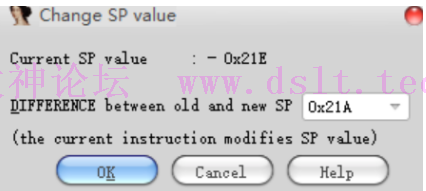
栈指针平衡 使用插件nop掉通过前面知道,经过pop栈针已经平衡,所以这两句汇编代码是没有必要的 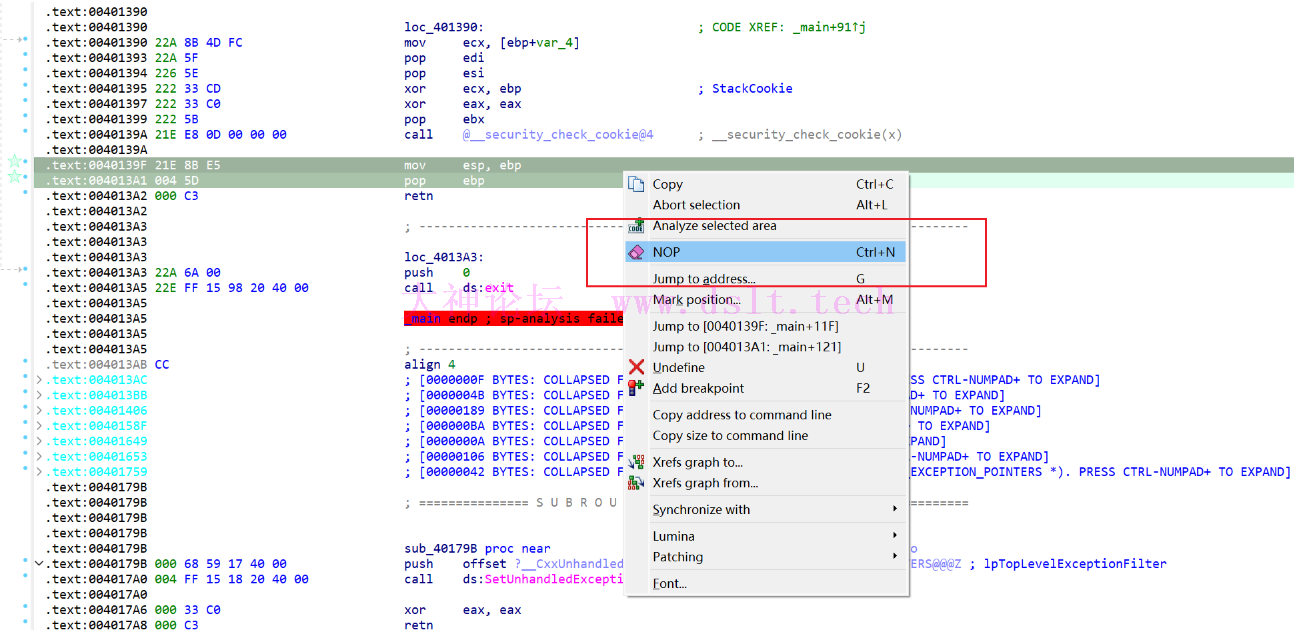
删除这两条指令的目的是在已经发生了出栈操作并且栈指针ESP与基址指针EBP相等的情况下,不再手动调整栈指针。这是因为栈指针已经回到了调用函数之前的位置,不需要再额外的指令来处理栈平衡。 
花指令的编写此处笔者踩了个大坑,值得一提的是,win下的gcc只支持x86下的内联汇编。
环境:VS2022 x86架构 C++ reference 内联汇编官方文档 asm__asm 关键字用于调用内联汇编程序,并且可在 C 或 C++ 语句合法时出现。 它不能单独显示。 它后面必须跟一个程序集指令、一组括在大括号中的指令,或者至少是一对空大括号。 此处的术语“__asm 块”指任何指令或指令组(无论是否在大括号中)。
asm语法asm-block:
__asm assembly-instruction;opt
__asm { assembly-instruction-list}**;**opt assembly-instruction-list:
assembly-instruction;opt
assembly-instruction;assembly-instruction-list;opt asm示例1.括在大括号里的简单 __asm 块: __asm {
mov al, 2
mov dx, 0xD007
out dx, al
}
__asm 放在每个程序集指令前面:
__asm mov al, 2
__asm mov dx, 0xD007
__asm out dx, al
3.由于 __asm 关键字是语句分隔符,因此还可将程序集指令放在同一行中: __asm mov al, 2 __asm mov dx, 0xD007 __asm out dx, al
这三个示例将生成相同的代码,但第一个样式(用大括号括起 __asm 块)具有一些优势。 大括号可清楚地将程序集代码与 C 或 C++ 代码分隔开,并避免了不必要的 __asm 关键字重复。 大括号还可防止二义性。 如果要将 C 或 C++ 语句放在与 __asm 块相同的行上,则必须将此块括在大括号中。 如果没有大括号,编译器无法判断程序集代码停止的位置以及 C 或 C++ 语句的开始位置。 花指令实现reference: https://www.anquanke.com/post/id/236490#h2-1 1.插入字节:这里就提到汇编里一个关键指令:_emit 立即数 //C语言中使用内联汇编
__asm
{
_emit 0xE8
}
//代表在这个位置插入一个字节数据0xE8
2.保证不被执行:通过构造一个永恒的跳转 __asm
{
jmp Label1
db thunkcode1; 垃圾数据
//垃圾数据例如:_emit 0xE8
Label1:
}
例如这样: 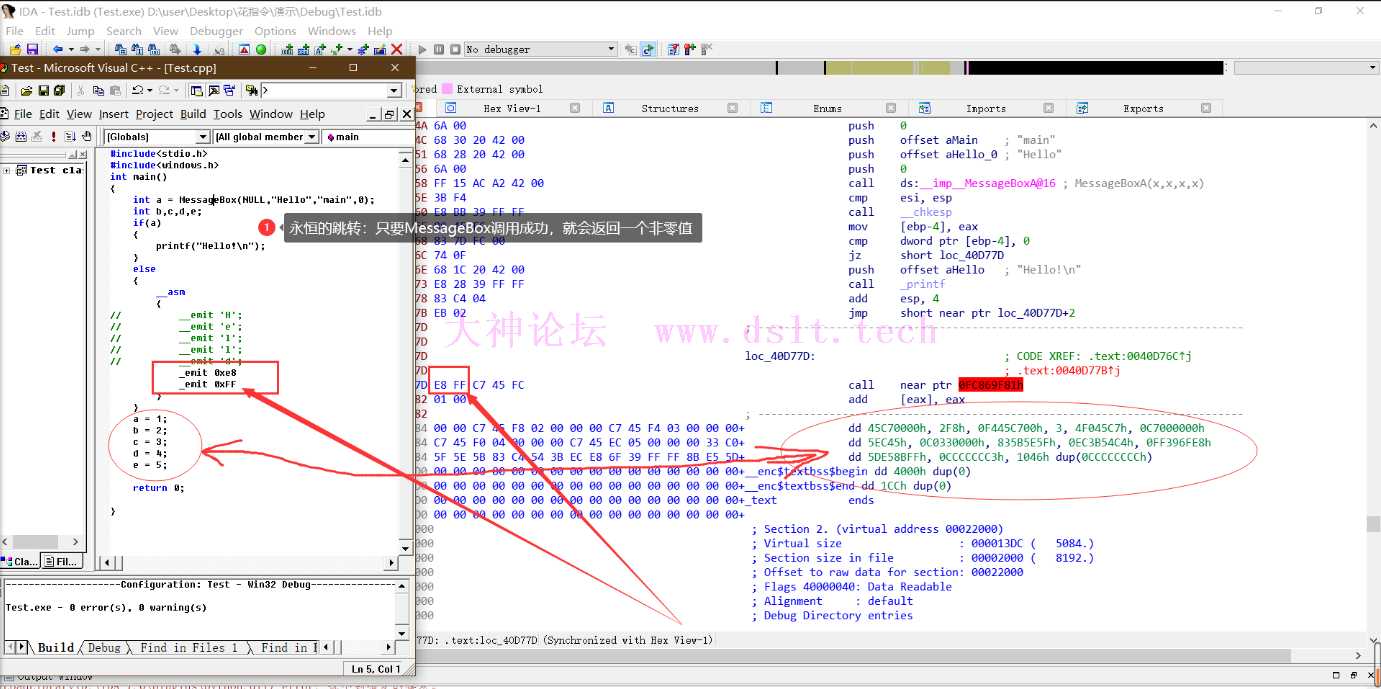
我对这反编译器对花指令的反编译稍作修改 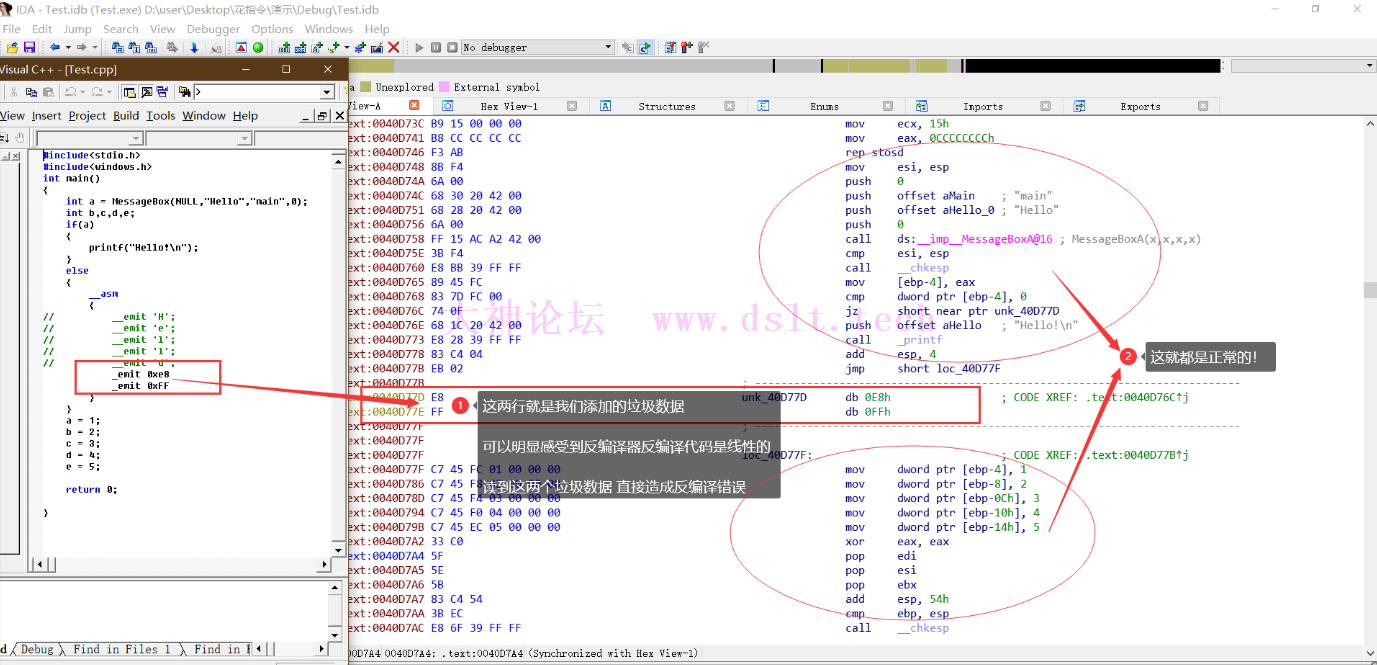
去掉花指令-> nop(0x90) 这部分是通过IDA手动去掉花指令,也可以在IDA里用IDApython/IDC写脚本去,或者在OD调试的时候去掉,原理都一样。 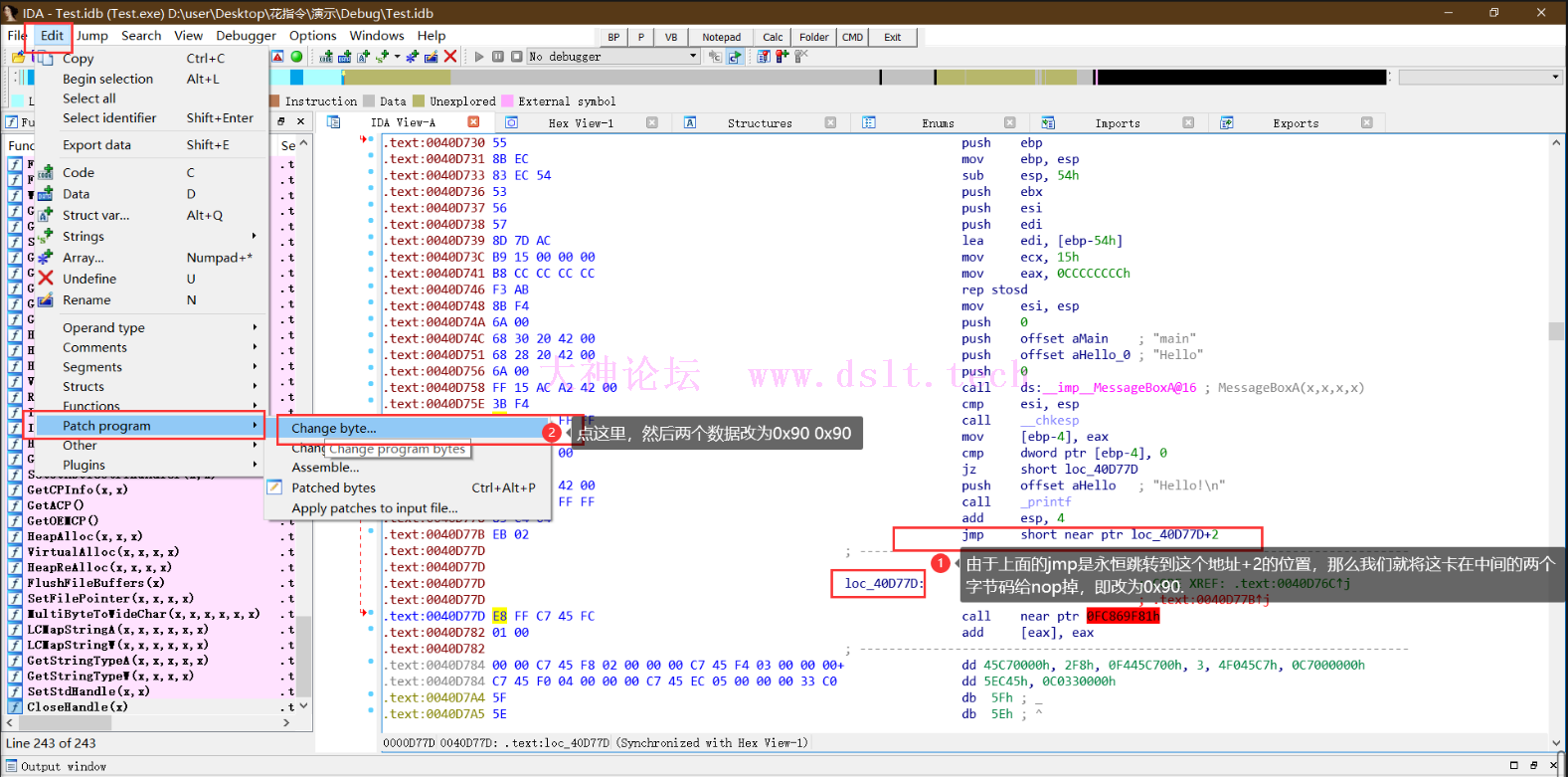
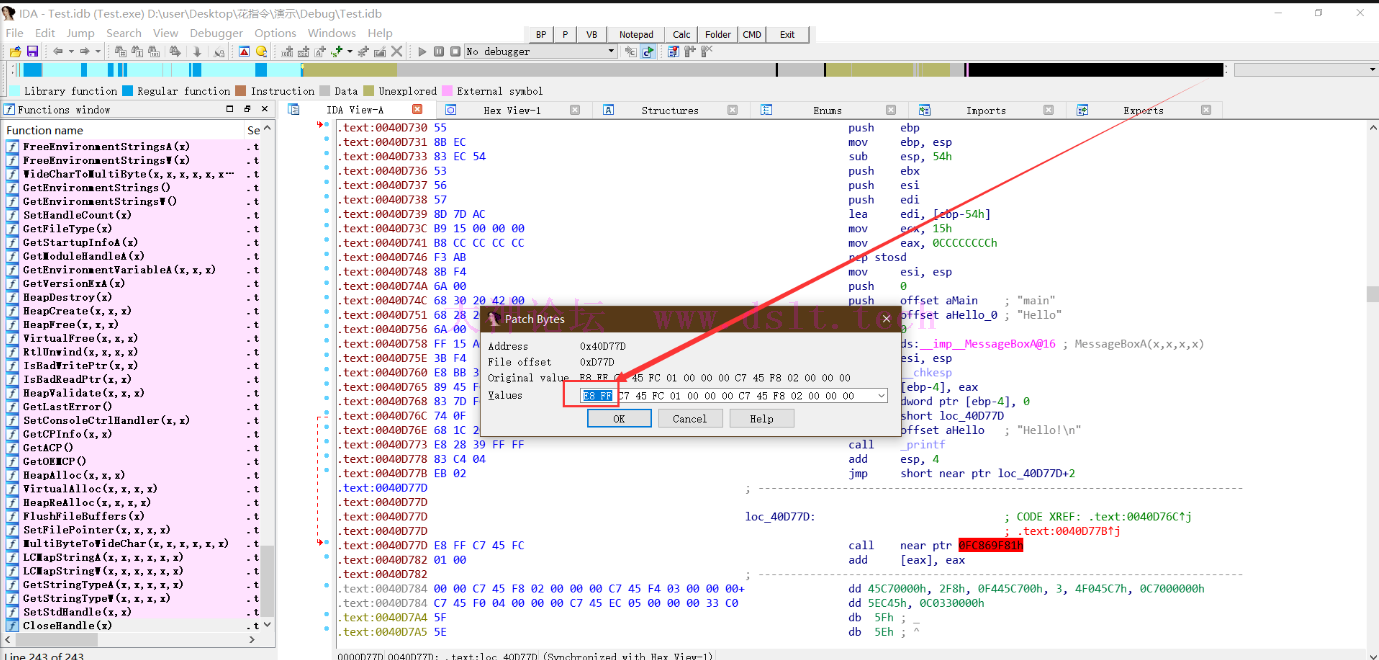
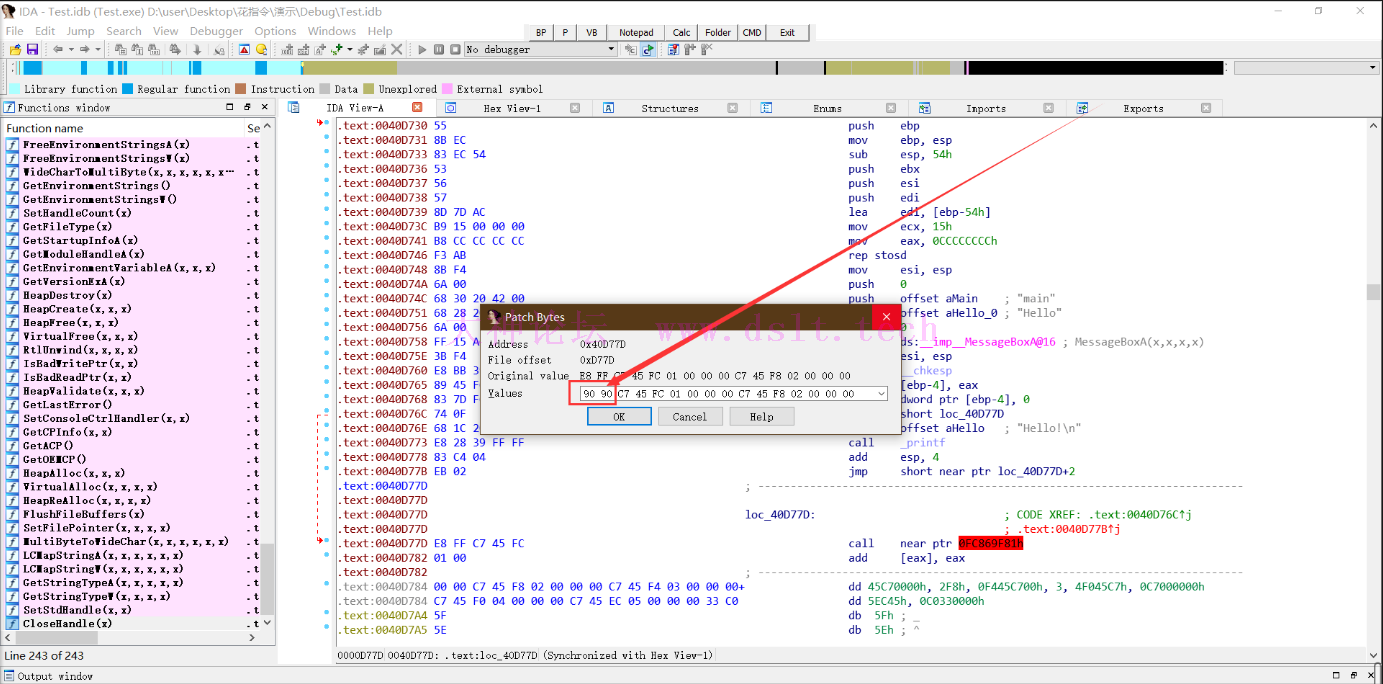
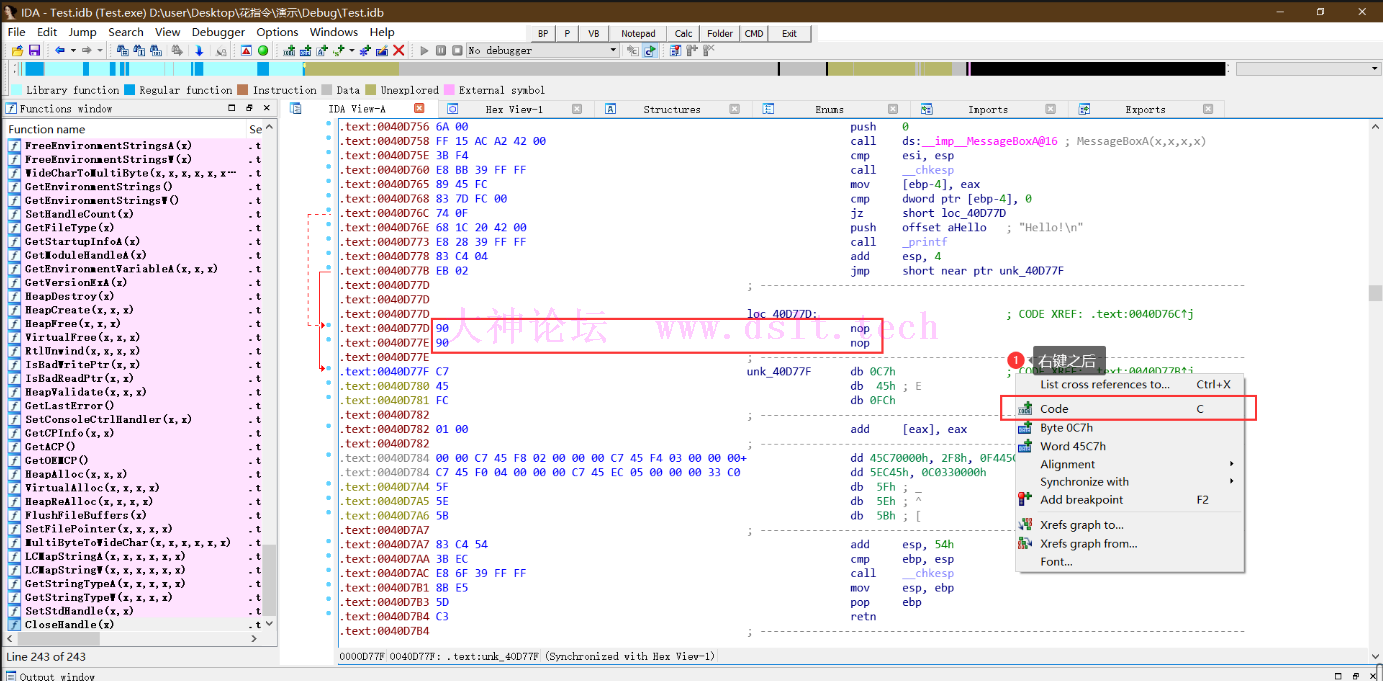
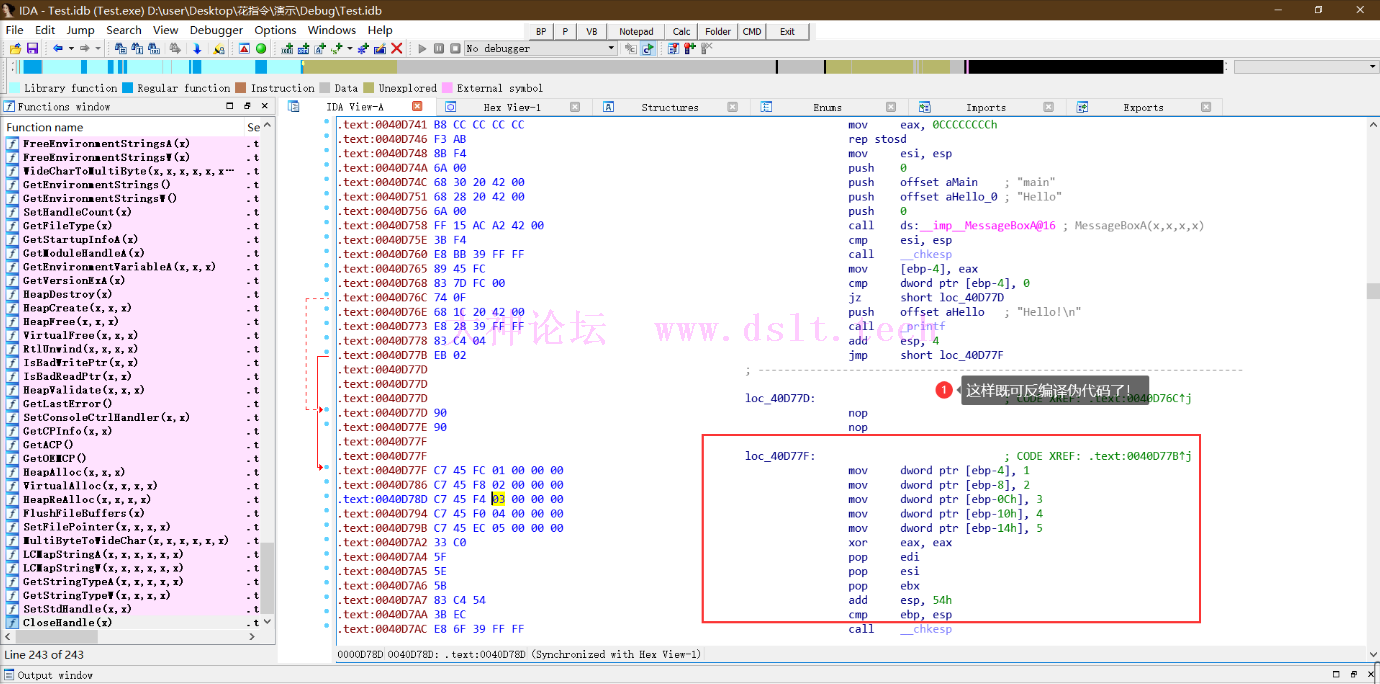
花指令分类emit指令的作用:- 编译器不认识的指令,拆成机器码来写。
- 插入垃圾字节来反跟踪,又称花指令。
用emit就是在当前位置直接插入数据(实际上是指令),一般是用来直接插入汇编里面没有的特殊指令,多数指令可以用asm内嵌汇编来做,没有必要用emit来做,除非你不想让其它人看懂你的代码。
我们来看用IDA反汇编的效果吧。
1.最简单的花指令a.最简单的jmpjmp Label1
db thunkcode1;垃圾数据
Labe1:
不过很可惜,反编译器能直接识别这种简单花指令,遇到这种能轻松过掉并反编译。 b.过时的多节形式与多层乱序这两周都是通过多次跳转,把垃圾数据和有用代码嵌套在一起,不过这种形式也比较老套了,反编译器依然能够轻松过掉并成功反汇编。 #多节形式
JMP Label1
Db thunkcode1
Label1:
……
JMP Label2
Db thunkcode2
Label2:
……
JMP Label1
Db thunkcode1
Label2:
……
JMP Label3
Db thunkcode3
Label1:
…….
JMP Label2
Db thunkcode2
Label3:
……
2.简单花指令a.互补条件代替jmp跳转asm
{
Jz Label
Jnz Label
Db thunkcode;垃圾数据
Label:
}
类似这种,无论如何都会跳转到label1处,还是能骗过反编译器。 b.跳转指令构造花指令1.简单跳转 __asm {
push ebx;
xor ebx, ebx;
test ebx, ebx;
jnz LABEL7;
jz LABEL8;
LABEL7:
_emit 0xC7;
LABEL8:
pop ebx;
}
很明显,先对ebx进行xor之后,再进行test比较,zf标志位肯定为1,就肯定执行jz LABEL8,也就是说中间0xC7永远不会执行。 不过这种一定要注意:记着保存ebx的值先把ebx压栈,最后在pop出来。 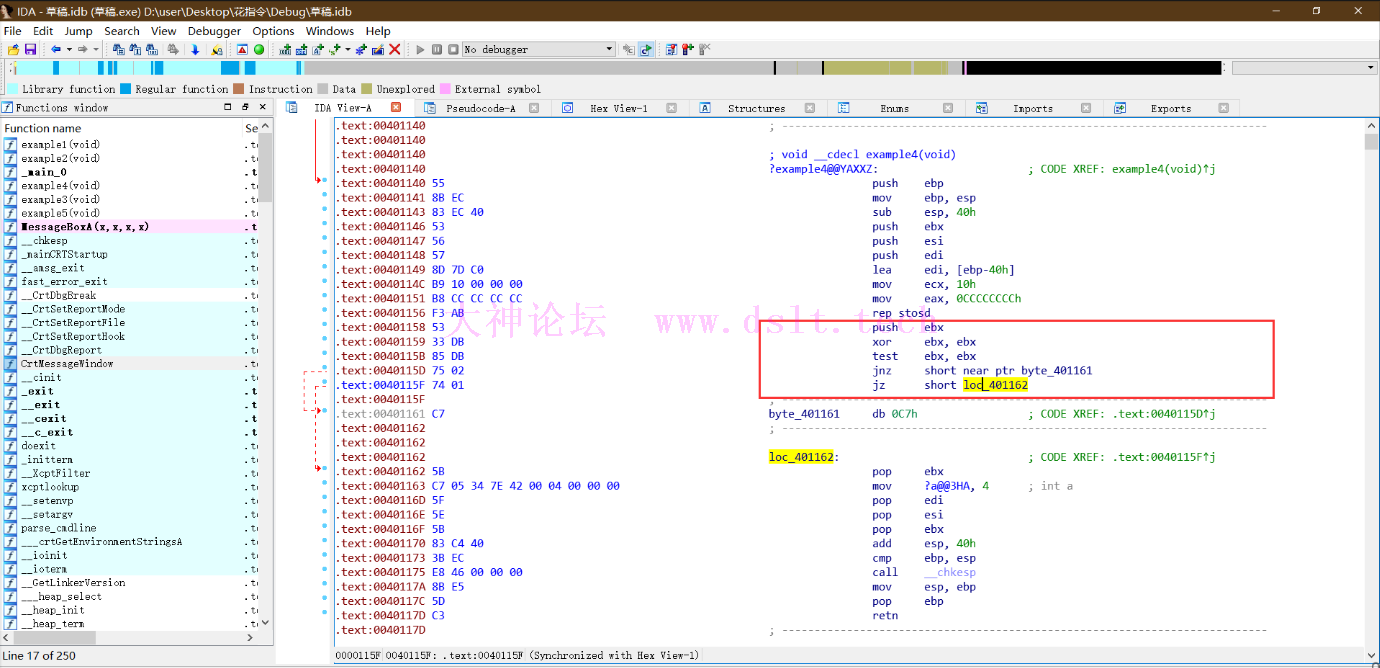
2.永真永加 通过设置永真或者永假的,导致程序一定会执行,由于ida反汇编会优先反汇编接下去的部分(false分支)。也可以调用某些函数会返回确定值,来达到构造永真或永假条件。ida和OD都被骗过去了
__asm{
push ebx
xor ebx,ebx
test ebx,ebx
jnz label1
jz label2
label1:
_emit junkcode
label2:
pop ebx//需要恢复ebx寄存器
}
__asm{
注:若转载请注明大神论坛来源(本贴地址)与作者信息。
|
 发表于 2023-11-25 11:16
发表于 2023-11-25 11:16





 评分
评分 顶
顶 踩
踩 扫码赞助
扫码赞助