本帖最后由 vlricchen 于 2023-11-26 11:15 编辑
LLVM基础此部分主要涉及基本概念、环境搭建及LLVM IR的基本指令
前言llvm官网(点击) 代码混淆定义:代码混淆是将计算机程序的代码,转换成一种功能上等价,但是难以阅读和理解的形式的行为。 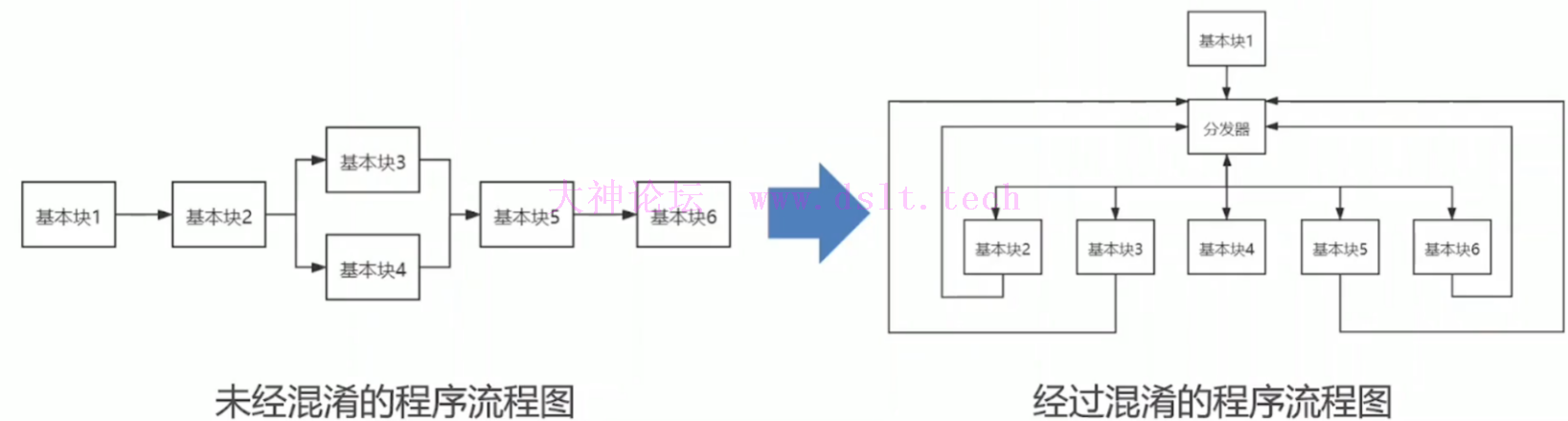
代码执行由顺序图转为分发器控制,使难以分清原来程序的逻辑。 学习混淆的意义对于软件开发者:一定程度上防止代码被逆向破解 对于逆向工程师:帮助我们研究反混淆技术 LLVM环境搭建
第一步:下载 LLVM-Core 和 Clang源代码首先应安装c++环境,安装cmake。
安装C++
安装cmake
https://github.com/llvm/llvm-project/releases/tag/llvmorg-12.0.1 下载 LLVM-Core 和 Clang 源代码: - llvm-12.0.1.src.tar.xz
- clang-12.0.1.src.tar.xz
在 /home/llvm/Programs 文件夹内创建 llvm-project 文件夹,存放我们刚刚下载的源码压缩包。 将两个压缩包解压之后改名为 llvm 和 clang ,方便后续使用。 在同一文件夹内创建名为 build 的文件夹,存放编译后的LLVM 此时的目录结构如下(笔者的ubuntu为中文,用户文件夹即为home): 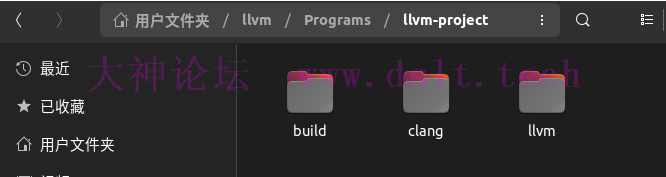
第二步:新建build.sh文件并编译sudo vim build.sh
在sh文件内写入如下命令 cd build
cmake -G "Unix Makefiles" -DLLVM_ENABLE_PROJECTS="clang" \
-DCMAKE_BUILD_TYPE=Release -DLLVM_TARGETS_TO_BUILD="X86" \
-DBUILD_SHARED_LIBS=On ../llvm
make
make install
cmake 参数解释: —G “Unix Makefiles”:生成Unix下的Makefile —DLLVM_ENABLE_PROJECTS=“clang”:除了 LLVM Core 外,还需要编译的子项目。 —DLLVM_BUILD_TYPE=Release:在cmake里,有四种编译模式:Debug, Release,RelWithDebInfo和MinSizeRel。使用 Release 模式编译会节省很多空间。 —DLLVM_TARGETS_TO_BUILD=“X86”:默认是ALL,选择X86可节约很多编译时间。 —DBUILD_SHARED_LIBS=On:指定动态链接 LLVM 的库,可以节省空间。 make install 指令是将编译好的二进制文件和头文件等安装到本机的 /usr/local/bin和 /usr/local/include 目录,方便后续使用。 执行 build.sh 文件自动安装和编译,编译时长从十多分钟到数小时,具体时间由机器性能决定。 sudo ./build.sh
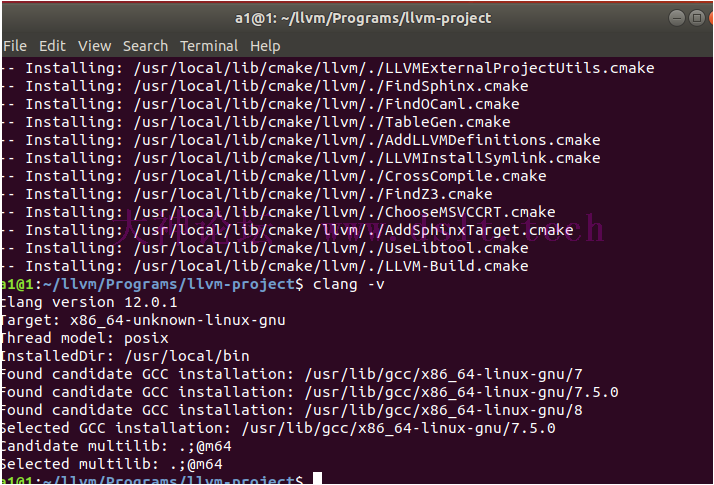
输入 clang -v确认编译和安装是否完成 clang -v
LLVM基本用法
编译流程代码混淆是基于优化器进行的。
1.将源代码转换为中间代码LLVM IR由前端Clang将源代码转化为LLVM IR 代码
LLVM IR主要有两种表现形式: - 人类可阅读的文本形式,对应后缀为.ll
- 方便机器处理的二进制文本,对应后缀为.bc
将源代码转化为以上两种LLVM IR代码的命令分别如下: 可阅读文本 clang -S -emit-llvm 文件名.cpp -o 文件名.ll
二进制 clang -c -emit-llvm 文件名.cpp -o 文件名.bc
以上两种后缀的文件后续均可以被优化和被编译成可执行文件 2.由优化器将对中间代码进行优化,得到优化后的中间代码。使用opt指令对LLVM IR进行优化,opt为optimizer即优化器的缩写
opt -load LLVMObfuscator.so -hlw -S 文件名.ll -o 文件名_opt.ll
- -load 加载指定的LLVM Pass集合进行优化(通常为.so文件)
- -hlw 是LLVM Pass中自定义的参数,用来指定使用哪个Pass文件进行优化
- -S和第一步的意义相同,为指定生成可阅读文本
3.由后端将中间代码转化为目标平台的机器代码,机器代码到可执行文件calng将如上两步整合为了一步,省去了链接器的过程(直接生成了可执行文件)
通过clang完成生成可执行文件的过程。 clnag 文件名_opt.ll -o 文件名
编写LLVM Pass基于 LLVM Pass框架进行编写。 优化器 opt 和 LLVM Pass 框架是我们后续实现代码混淆的基础。
LLVM Pass的基本概念LLVM Pass框架功能非常强大,一些代码优化工具和fuzz(AFL)工具都是基于llvm pass框架进行开发
LLVM Pass 框架是整个 LLVM 提供给用户用来干预代码优化过程的框架,也是我们编写代码混淆工具的基础。 编译后的 LLVM Pass 通过优化器 opt 进行加载,可以对 LLVM IR 中间代码进行分析和修改,生成新的中间代码。 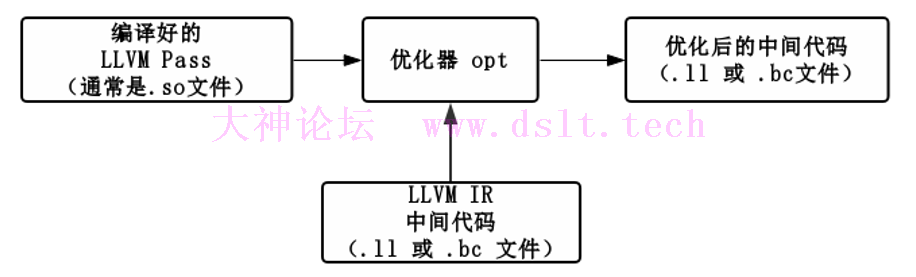
LLVM 源代码目录结构
优化器属于llvm-core的子项目
llvm/include/llvm 文件夹存放了 LLVM 提供的一些公共头文件,这些头文件是开发过程中要用到的。 
llvm/lib 文件夹存放了 LLVM 大部分源代码(.cpp 文件)和一些不公开的头文件,阅读这些源代码可以深入了解llvm的运行原理 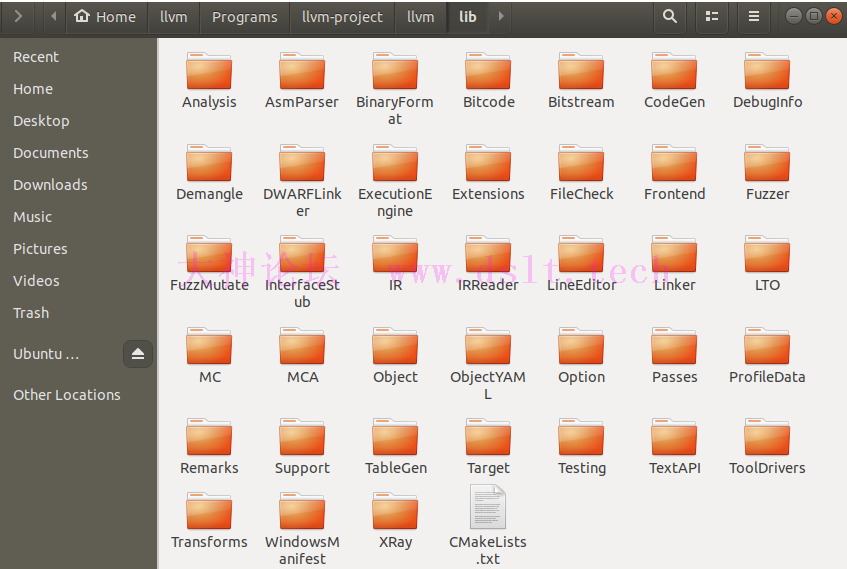
存放所有 LLVM Pass 的源代码。
也存放了一些 LLVM 自带的 Pass。 自己编写的Pass也可以放入该文件夹。 LLVM Pass的编写、编译及加载
LLVM Pass的编写(理论)以 "Hello world" 为例。
目标:编写一个 LLVM Pass,遍历程序中的所有函数,并输出 “Hello, ”+ 函数名。

1.创建Pass项目CMake是一种项目管理工具,可以对各种LLVM Pass进行编写
LLVM Pass 支持三种编译方式: - 第一种是与整个 LLVM 一起重新编译,Pass 代码需要存放在 llvm/lib/Transforms 文件夹中。(编译耗时间)
- 第二种方法是通过 CMake 对 Pass 进行单独编译。(最常使用)
- 第三种方法是使用命令行对 Pass 进行单独编译。(项目越大越不好管理)
2.Pass类型的选择- 在设计一个新的 LLVM Pass 时,最先要决定的就是选择 Pass 的类型。
- LLVM 有多种类型的 Pass 可供选择,包括:ModulePass(基于模块)、FunctionPass(基于函数)、CallGraphPass(基于调用图)、LoopPass(基于循环)等等。
本文重点学习FunctionPass,基于函数的Pass 3.FunctionPass简介- FunctionPass 以函数为单位进行处理。
- FunctionPass 的子类必须实现 runOnFunction(Function &F) 函数。
- 在 FunctionPass 运行时,会对程序中的每个函数执行runOnFunction 函数。
4.LLVM Pass的编写步骤1).创建一个类(class),继承 FunctionPass 父类 2).在创建的类中实现 runOnFunction(Function &F) 函数。 3).向 LLVM 注册我们的 Pass 类。 5.LLVM的编译选择基于CMake的编译,直接使用CMake进行编译即可。 编译好的.so文件在build文件夹内。 6.LLVM Pass的加载使用优化器 opt 将处理中间代码,生成新的中间代码: opt -load ./LLVMObfuscator.so -hlw -S hello.ll -o hello_opt.ll
-load 加载编译好的 LLVM Pass(.so文件)进行优化 LLVM Pass的编写(实践)创建文件夹首先在虚拟机的llvm文件夹创建OLLVM++文件夹 在此创建如下文件夹及文件 Build 文件夹:存放编译后 LLVM Pass Test 文件夹:存放测试程序 TestProgram.cpp Test/TestProgram.cpp:一个简单的 CTF 逆向题 Transforms/include 文件夹:存放整个 LLVM Pass 项目的头文件,暂时还没有用到 Transforms/src 文件夹:存放整个 LLVM Pass 项目的源代码 Transforms/src/HelloWorld.cpp:HelloWorld Pass 的源代码,一般来说一个 Pass 使用一个 cpp 文件 实现即可。 Transforms/CMakeLists.txt:整个 CMake 项目的配置文件。
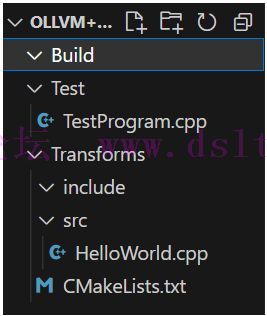
各文件内容分别如下: TestProgram.cpp 将要被编译的源代码 #include <cstdio>
#include <cstring>
char input[100] = {0};
char enc[100] = "\x86\x8a\x7d\x87\x93\x8b\x4d\x81\x80\x8a\
\x43\x7f\x49\x49\x86\x71\x7f\x62\x53\x69\x28\x9d";
void encrypt(unsigned char *dest, char *src){
int len = strlen(src);
for(int i = 0;i < len;i ++){
dest[i] = (src[i] + (32 - i)) ^ i;
}
}
//flag{s1mpl3_11vm_d3m0}
int main(){
printf("Please input your flag: ");
scanf("%s", input);
unsigned char dest[100] = {0};
encrypt(dest, input);
bool result = strlen(input) == 22 && !memcmp(dest, enc, 22);
if(result){
printf("Congratulations~\n");
}else{
printf("Sorry try again.\n");
}
}
CMakeLists.txt # 参考官方文档:https://llvm.org/docs/CMake.html#developing-llvm-passes-out-of-source
project(OLLVM++) #项目名称 OLLVM++
cmake_minimum_required(VERSION 3.13.4) #和llvm有关的环境变量
find_package(LLVM REQUIRED CONFIG)
list(APPEND CMAKE_MODULE_PATH "${LLVM_CMAKE_DIR}")
include(AddLLVM)
include_directories("./include") # 包含 ./include 文件夹中的头文件
separate_arguments(LLVM_DEFINITIONS_LIST NATIVE_COMMAND ${LLVM_DEFINITIONS})
add_definitions(${LLVM_DEFINITIONS_LIST})
include_directories(${LLVM_INCLUDE_DIRS})
add_llvm_library( LLVMObfuscator MODULE #注册LLVMObfuscator模块
src/HelloWorld.cpp #添加项目的源代码文件
)
编写相关代码具体操作在bool Demo::runOnFunction(Function &F){}中实现即可。
Hello.cpp为我们要编写的LLVM Pass代码 模板如下 #include "llvm/Pass.h"
#include "llvm/IR/Function.h"
#include "llvm/Support/raw_ostream.h"
using namespace llvm;
namespace {
class Demo : public FunctionPass{
public:
static char ID;
Demo() : FunctionPass(ID) {}
bool runOnFunction(Function &F);
};
}
// runOnFunction 函数实现
bool Demo::runOnFunction(Function &F){
// do something
}
char Demo::ID = 0;
// 注册该 Demo Pass
static RegisterPass<Demo> X("xxx", "Pass 描述.");
关于此次实验代码 HelloWorld.cpp如下 //在此编写LLVM Pass的代码
//导入llvm所需的头文件
#include "llvm/Pass.h"
#include "llvm/IR/Function.h"
#include "llvm/Support/raw_ostream.h" //和输入输出有关
using namespace llvm;
//定义我们自己的命名空间
namespace{
class HelloWorld : public FunctionPass{ //自定义的HelloWorld类继承FunctionPass
public:
static char ID;
HelloWorld() : FunctionPass(ID) {} //HelloWorld的构造函数
bool runOnFunction(Function &F);
};
}
bool HelloWorld::runOnFunction(Function &F){
//todo 对函数的分析或修改代码
outs() << "Hello," << F.getName() << "\n"; //获取llvm的输出流
}
char HelloWorld::ID = 0;
static RegisterPass<HelloWorld> X("hlw","对Pass的描述"); //注册该Pass
test.sh:编译 LLVM Pass 并对 Test 文件夹中的代码进行测试(复制时把我的注释去掉) 在vscode控制台输入 chmod 777 test.sh
然后运行 ./test.sh
笔者在此处遇到一个问题,第一次编译并不会在Build文件夹下产生LLVMObfuscator.so文件,需要进入Transforms文件夹手动进行复制到Build文件夹进行第二次编译。 cd ./Build
cmake ../Transforms //对transforms的项目进行编译,得到编译后的`.so`文件
make
cd ../Test
clang -S -emit-llvm TestProgram.cpp -o TestProgram.ll //clang将源代码转换为中间代码
opt -load ../Build/LLVMObfuscator.so -hlw -S TestProgram.ll -o TestProgram_hlw.ll ////opt加载so文件,用hlw pass进行优化
clang TestProgram_hlw.ll -o TestProgram_hlw //将优化后的中间代码编译为可执行文件
./TestProgram_hlw //运行可执行文件
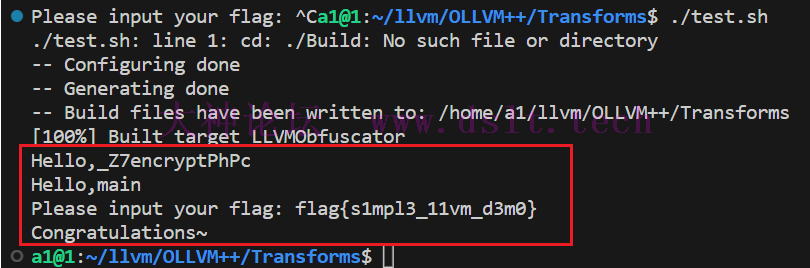
实现了对样本程序中的每个函数进行扫描,并输出了"Hello,"+函数名 CMake学习https://github.com/ttroy50/cmake-examples LLVM IR概述LLVM编译过程回顾: 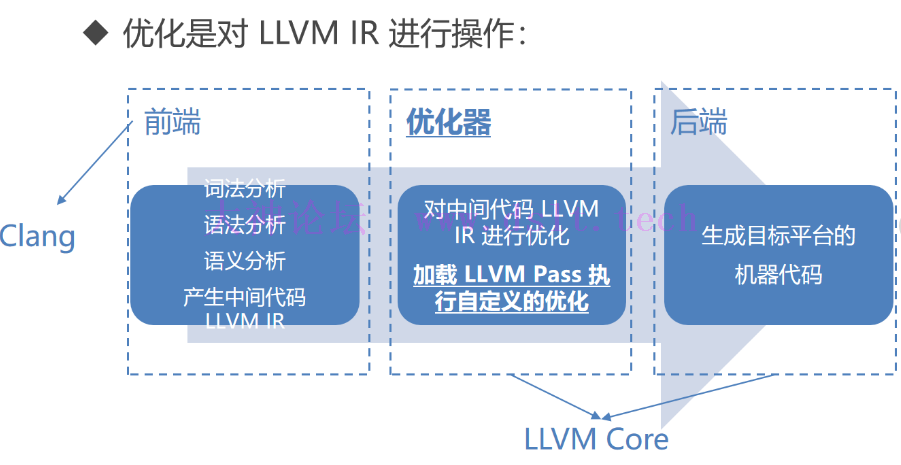
什么是LLVM IR?- LLVM IR 是一门低级编程语言,语法类似于汇编
- 任何高级编程语言(如C++)都可以用 LLVM IR 表示
- 基于 LLVM IR 可以很方便地进行代码优化(任何编程语言都能统一转换为LLVM IR)
LLVM IR的两种表示方法LLVM IR 共有两种表示方法: - 人类可以阅读的文本形式,文件后缀为 .ll
- 易于机器处理的二进制格式,文件后缀为 .bc
通过LLVM自带的工具,该两种表示形式也可以互相转换 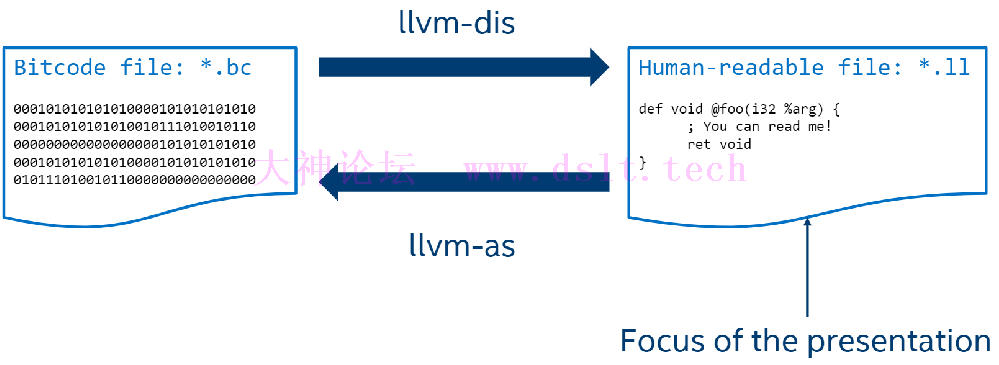
LLVM IR结构
源代码被LLVM IR编译后,有如下结构 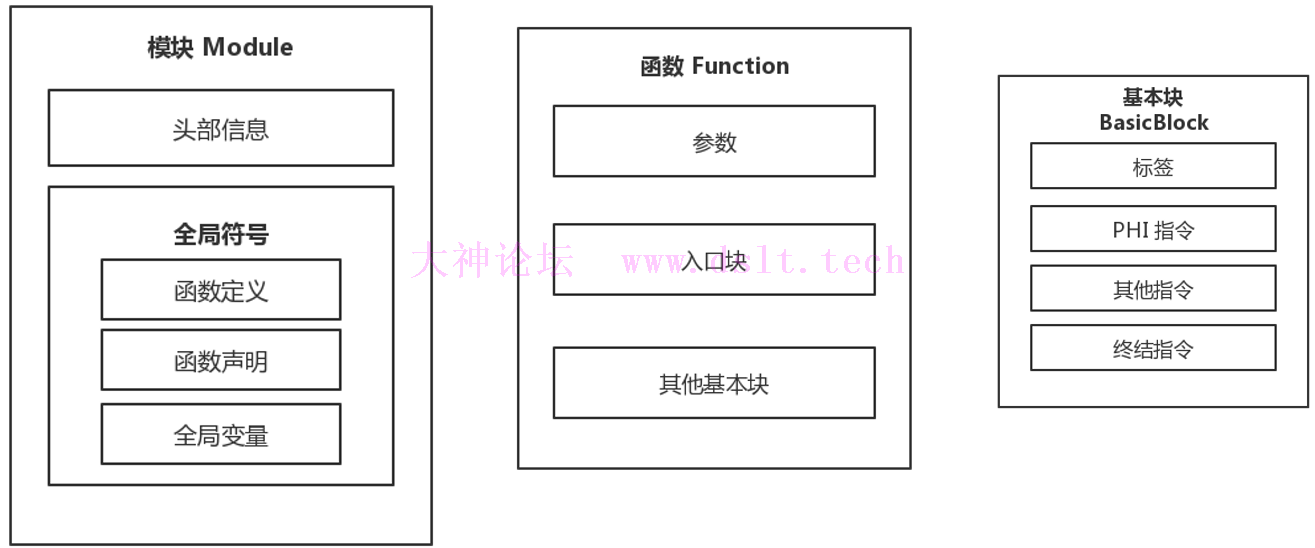
模块 Module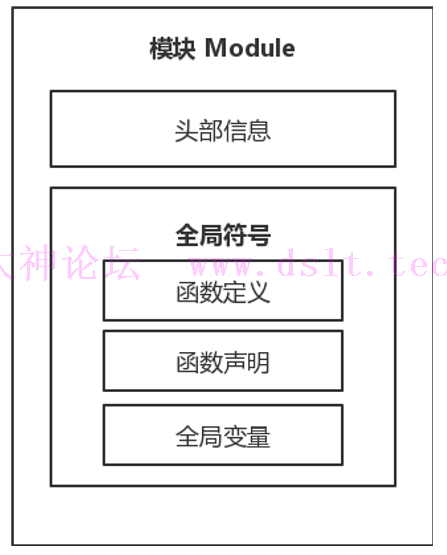
- 一个源代码文件对应 LLVM IR 中的一个模块。
- 头部信息包含程序的目标平台,如X86、ARM等等,和一些其他信息。
- 全局符号包含全局变量、函数的定义与声明。
函数 Function
- LLVM IR 中的函数表示源代码中的某个函数。
- 参数,顾名思义为函数的参数。
- 一个函数由若干基本块组成,其中函数最先执行的基本块为入口块。
基本块 BasicBlock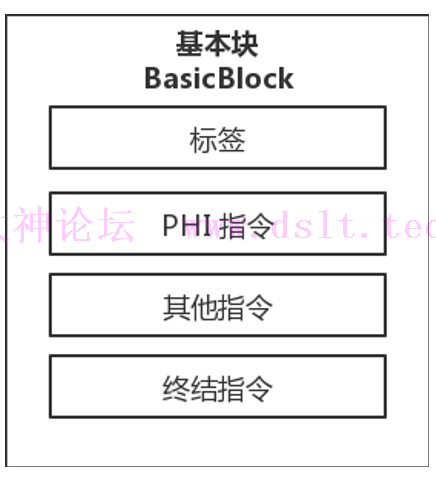
- 一个基本块由若干个指令和标签组成。
- 正常情况下,基本块的最后一条指令为跳转指令(br 或 switch),或返回指令(retn),也叫作终结指令(Terminator Instruction)。
- 其他指令:PHI 指令是一种特殊的指令。
LLVM IR和IDA反汇编的结构比较相似。 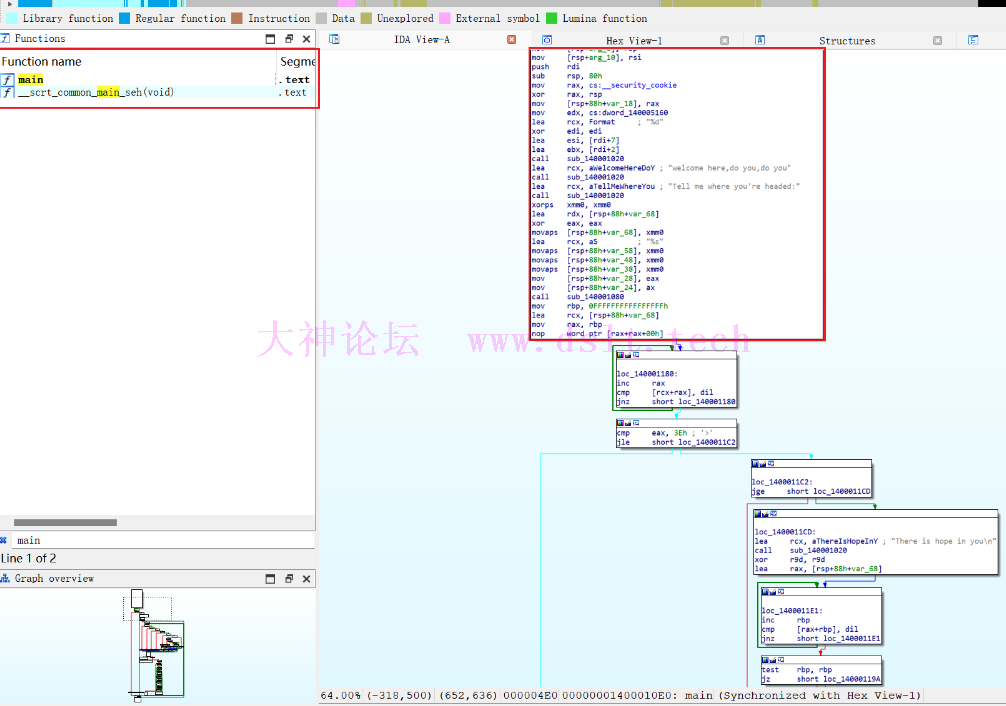
基于 LLVM 的混淆,通常是以函数或者比函数更小的单位为基本单位进行混淆的,我们通常更关心函数和基本块这两个结构。 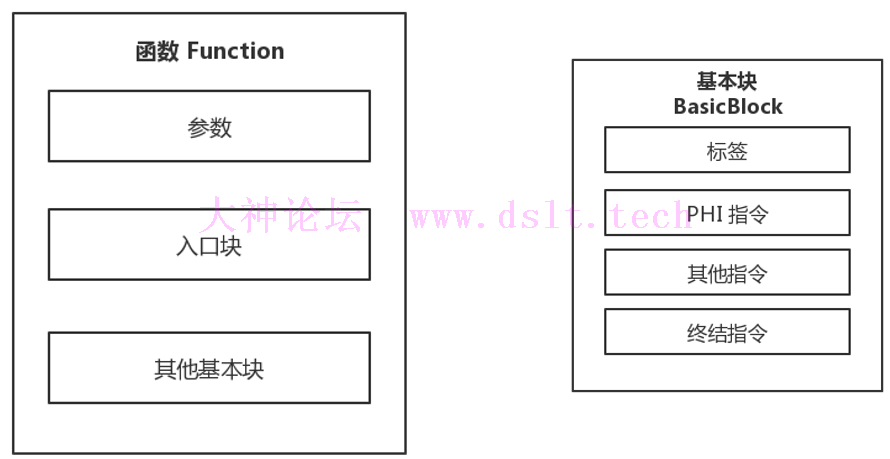
了解 LLVM IR 的结构是我们学习代码混淆的基础:- 以函数为基本单位的混淆:控制流平坦化。
- 以基本块基本单位的混淆:虚假控制流。
- 以指令为基本单位的混淆:指令替代。
LLVM IR指令总共有六大类指令 - 终结指令 Terminator Instructions
- 二元运算 Binary Operations
- 按位二元运算 Bitwise Binary Operations
- 内存访问和寻址操作 Memory Access and Addressing Operations
- 类型转换操作 Conversion Operations
- 其他操作 Other Operations
终结指令基本块的最后一个指令,通常为跳转指令或返回指令。
跳转到下一个基本快进行执行或从当前执行的函数中返回。
ret指令return
函数的返回指令,对应 C/C++ 中的 return。 分为有返回值的ret指令和无返回值的ret指令。 
实例 
br指令branch
跳转指令,分为条件分支和非条件分支。 - br 是”分支”的英文 branch 的缩写,分为非条件分支和条件分支,对应 C/C++ 的 if 语句。
- 无条件分支类似于x86汇编中的 jmp 指令,条件分支类似于x86汇编中的 jnz, je 等条件跳转指令

br il<cond>, label <iftrue>, label <ifflase> //i1为条件分支指定的热条件, i1是1位整数,可以理解成一个bool类型,若i1为true,则跳转到第一个基本块;否则跳转到第二个基本块
br label <dest> //直接跳转到目的基本块
实例 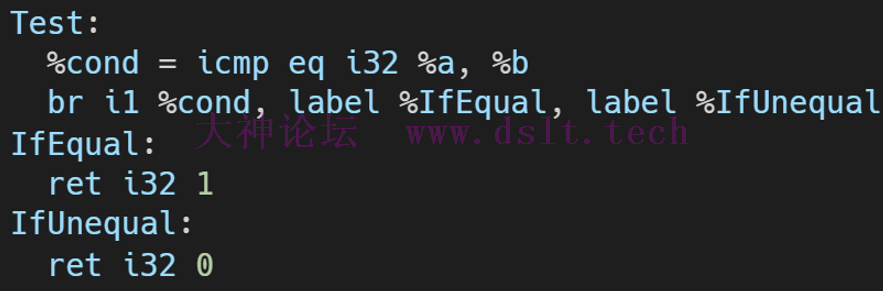
Test:
%cond = icmp eq i32 %a, %b //比较ab变量是否相等,返回true or flase
br i1 %cond, label %IfEqual, label %IfUnequal //根据%cond判断跳转到哪个基本快
IfEqual:
ret i32 1
IfUnequal:
ret i32 0
比较指令比较指令,通常与br指令一起出现
- 在x86汇编中,条件跳转指令(jnz, je 等)通常与比较指令 cmp, test 等一起出现。
- 在 LLVM IR 中也有这样一类指令,他们通常与条件分支指令 br 一起出现。
icmp指令整数或指针的比较指令。 - 条件 cond 可以是 eq(相等), ne(不相等), ugt(无符号大于unsigned greater than)等等。

实例 
fcmp指令浮点数的比较指令。 - 条件 cond 可以是 oeq(ordered and equal), ueq(unordered or equal), false(必定不成立)等等。
- ordered的意思是,两个操作数都不能为 NAN
实例 
fcmp oeq //比较两个浮点数是否相等
fcmp one //比较两个浮点数是否不相等 ordered and not equal
switch指令分支指令,可看做是 br 指令的升级版 - 支持的分支更多,但使用也更复杂。对应 C/C++ 中的 switch。
- 根据switch变量值value进行跳转,若value没有对应值,则执行默认的<defaultdest>基本块

switch <intty/变量类型> <value/变量值>, label <defaultdest> [ <intty><val>, label <dest>...]
实例 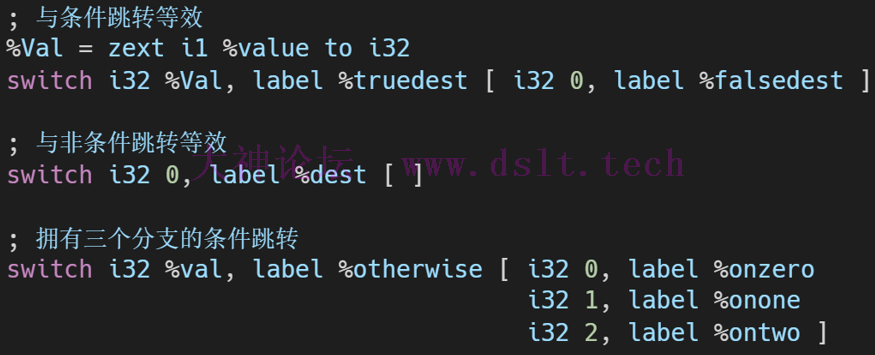
二元运算指令add指令整数加法指令 - 整数加法指令,对应 C/C++ 中的“+”操作符,类似x86汇编中的 add 指令。

实例 
sub指令整数减法指令 - 整数减法指令,对应 C/C++ 中的“-”操作符,类似x86汇编中的 sub 指令。

实例 
mul指令整数乘法指令 - 对应 C/C++ 中的“*”操作符,类似x86汇编中的 mul 指令。

实例 
udiv指令无符号整数除法指令 - 对应 C/C++ 中的“/”操作符。如果存在exact关键字,且op1不是op2的倍数,就会出现错误。

加入exact时,需要精确保证op1是op2的倍数,指令才会正常执行 实例 
sdiv指令有符号整数除法指令 
实例 
urem指令无符号整数取余指令 
实例 
srem指令有符号整数取余指令 
实例 
按位二元运算指令逻辑移位统一当成无符号数 算数右移按照原来符号数来决定正负
shl指令整数左移指令 - 对应 C/C++ 中的“<<”操作符,类似x86汇编中的 shl 指令。

<result> = shl <ty> <op1>, <op2> //op1左移op2位
实例 
lshr指令整数逻辑右移指令 - 对应 C/C++ 中的“>>”操作符,右移指定位数后在左侧补0。

实例 
-2当做无符号数来处理,右移得到16进制数 无符号的右移
ashr指令整数算术右移指令 - 右移指定位数后在左侧补符号位(负数的符号位为1,正数的符号位为0)。

实例 
-2右移1:带符号的右移
逻辑移位:无符号右移
算数移位:带符号右移 and指令整数按位与运算指令 
实例 
or指令整数按位或运算指令 
实例 
xor指令整数按位异或运算指令 
实例 
变量和"-1"进行异或,相当于把变量按位取反
内存访问和寻址操作指令(重点)静态单赋值- 在编译器设计中,静态单赋值(Static Single Assignment, SSA),是 IR 的一种属性。
- 简单来说,SSA 的特点是:在程序中一个变量仅能有一条赋值语句。
- LLVM IR 正是基于静态单赋值原则设计的。
实例 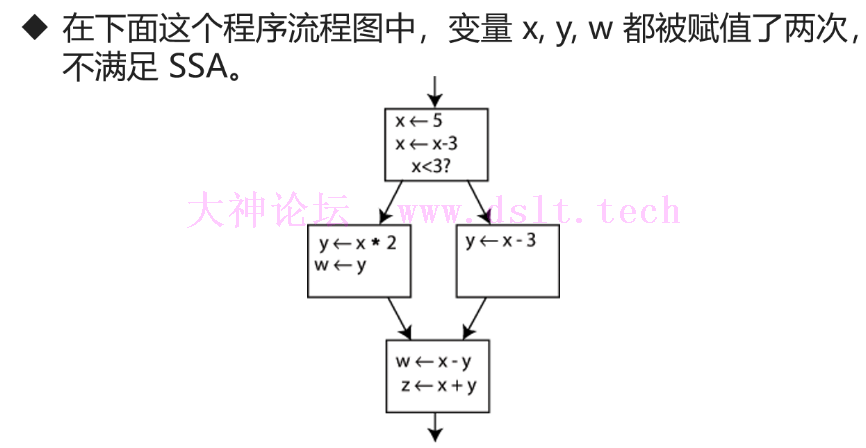
引例: - 假设 C++ 也是基于静态单赋值原则的(即一个变量只能被赋值一次),要怎样修改这个 for 循环,使其符合 SSA 原则?
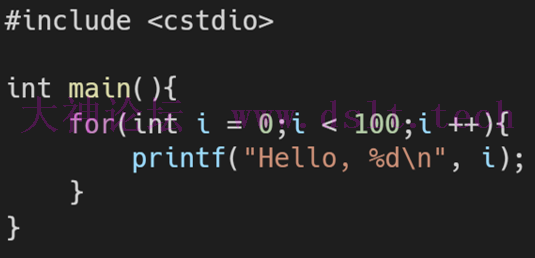
- 以下是一种实现方式,也是 LLVM IR 采取的实现方式。在LLVM IR 中也有类似 malloc 和 指针操作 的指令:
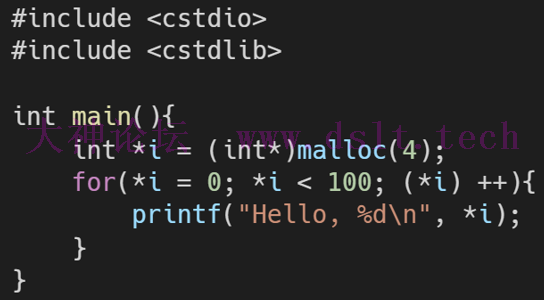
只有第一次给指针i进行了赋值,后面都是对指针指向的区域进行赋值
alloca指令内存分配指令 - 在栈中分配一块空间并获得指向该空间的指针,类似于 C/C++ 中的 malloc 函数。(区别于C语言malloc函数在堆中分配空间)

type指定了分配什么类型的空间,NumElements指定了分配空间的个数
实例 
store指令内存存储指令 - 向指针指向的内存中存储数据,类似于 C/C++ 中的指针解引用后的赋值操作。

实例 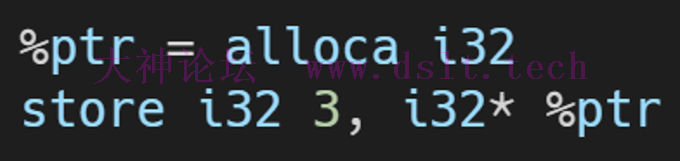
load指令内存读取指令 - 从指针指向的内存中读取数据,类似于 C/C++ 中的指针解引用操作。

实例!分配4字节内存
存储3
读取ptr指向的内存,即3
类型转换操作指令trunc ... to指令截断指令 - 将一种类型的变量截断为另一种类型的变量。对应 C/C++ 中大类型向小类型的强制转换(比如 long 强转 int)

实例 
%X = trunc i32 257 to i8 //截断低8位,十进制为1
%Y = trunc i32 123 to i1 //转换为i1类型,即bool类型 保留最低一位,即1或true
zext ... to指令零拓展(Zero Extend)指令 将一种类型的变量拓展为另一种类型的变量,高位补0。对应 C/C++ 中小类型向大类型的强制转换(比如 int 强转 long) 
实例 
sext .. to 指令符号位拓展(Sign Extend)指令 通过复制符号位(最高位)将一种类型的变量拓展为另一种类型的变量。 
实例 
其他操作指令不太好分类,又比较常见的指令
phi指令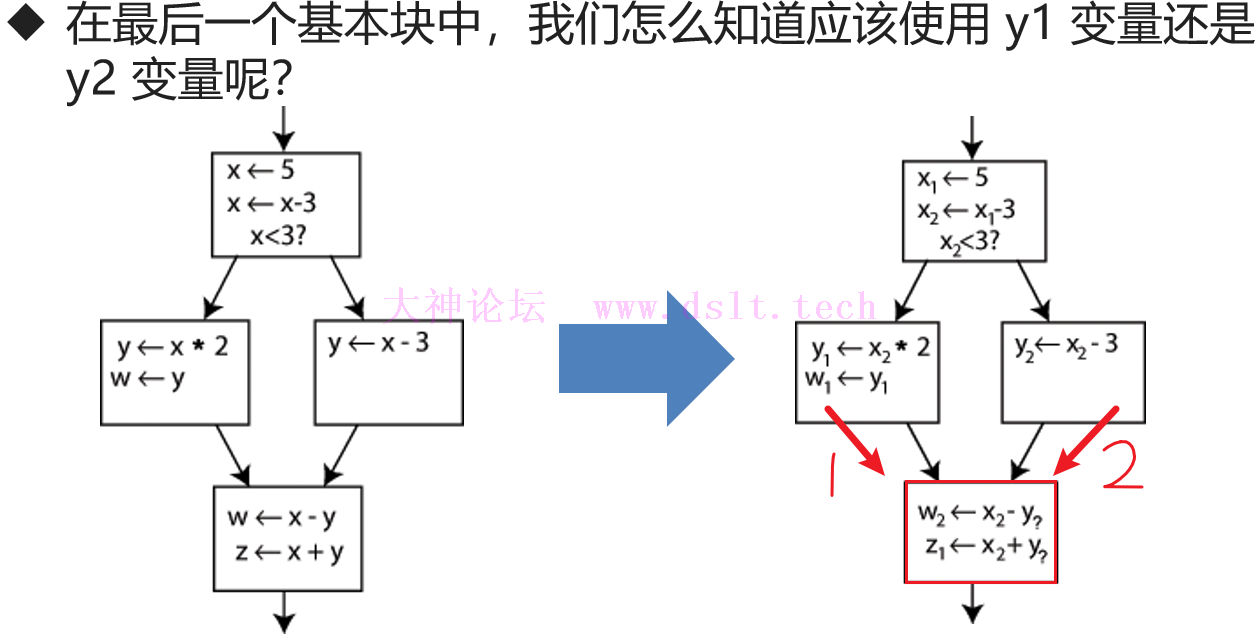
通过引入Φ函数来解决这个问题,Φ函数的值由前驱块决定,这里的Φ函数对应 LLVM IR 中的 phi 指令: 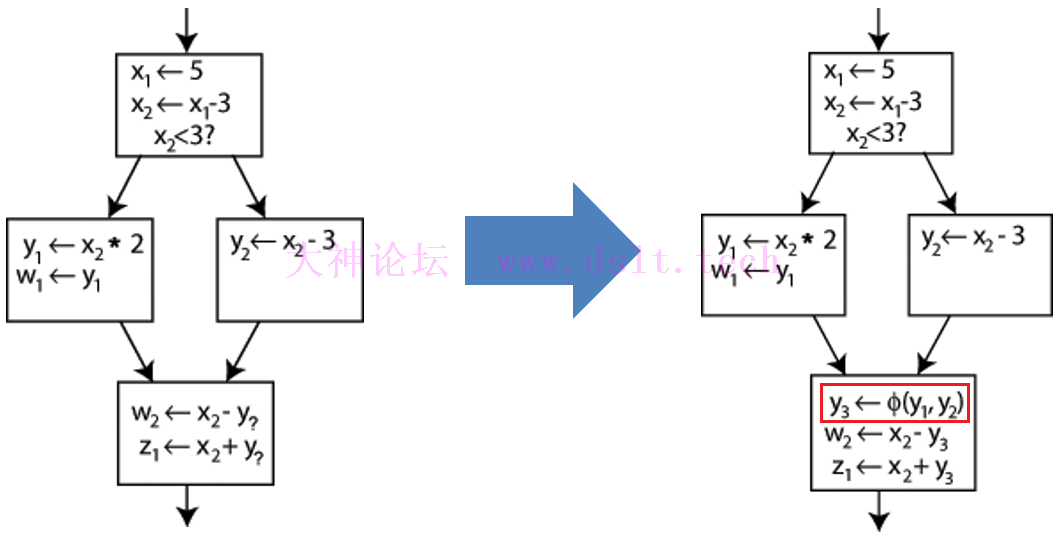
以下是一个用 phi 指令实现for循环的实例: 
select 指令- select 指令类似于 C/C++ 中的三元运算符”... ? ... : ...”

实例 
call指令- call 指令用来调用某个函数,对应 C/C++ 中的函数调用,与x86汇编中的 call 指令类似

实例 
一个简单的LLVM IR阅读与分析(了解结构)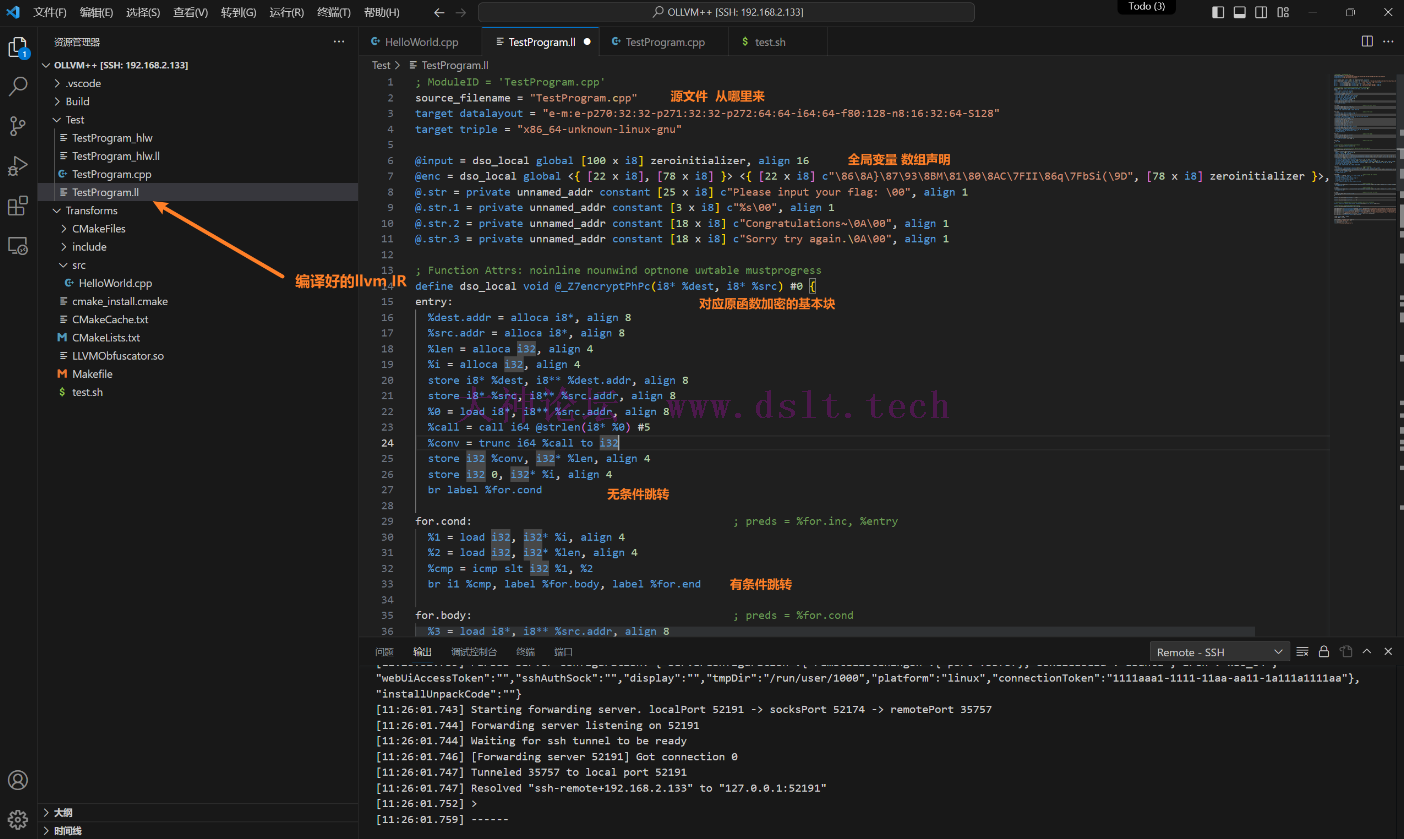
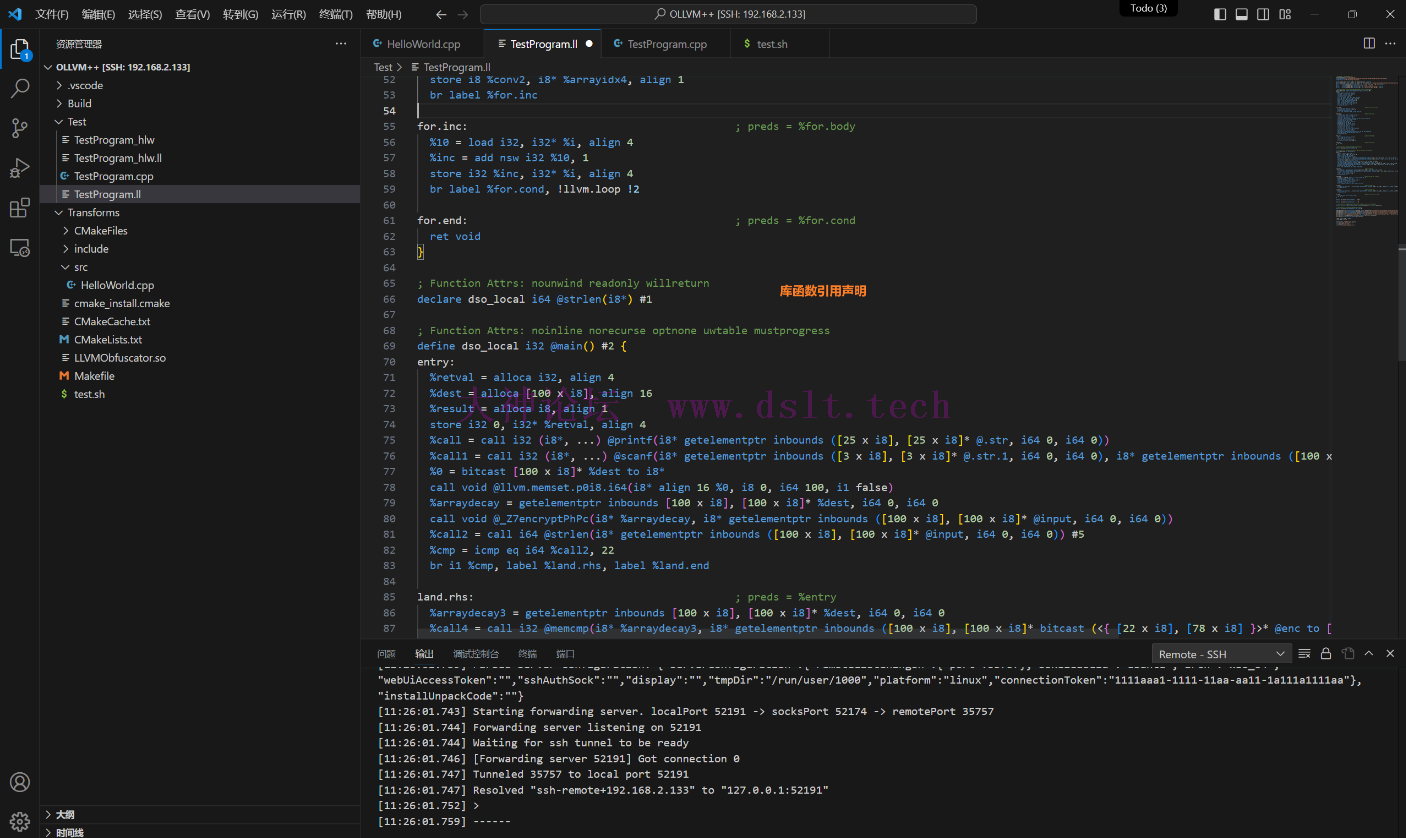
LLVM IR for循环分析for循环的实现方法
注:若转载请注明大神论坛来源(本贴地址)与作者信息。
|


 发表于 2023-11-26 11:15
发表于 2023-11-26 11:15







 评分
评分 顶
顶 踩
踩 扫码赞助
扫码赞助