本帖最后由 ahxhs 于 2023-12-02 08:24 编辑
首先,我们先来看看这段代码是做什么的。这段代码是一个Python程序,它的主要目的是从一个网站上抓取一些文章链接,并下载这些文章的内容,最后保存为.zip格式的压缩文件。听起来有点复杂,但我会尽力用简单的语言来解释。 首先,我们需要导入三个库:requests、BeautifulSoup和time。 - requests:这个库是用来发送HTTP请求的,就像你平时在浏览器中输入网址并按回车键一样,但这个库可以在程序中自动完成。
- BeautifulSoup:这个库是用来解析HTML文档的,它可以帮你找到你感兴趣的数据,比如在这个程序中,它用来找到文章链接。
- time:这个库用来控制程序的等待时间,避免网站因为被频繁访问而封锁你的IP地址。
这一步是为了让网站认为你是一个真实的浏览器,而不是一个爬虫。你提供了一个常见的浏览器用户代{过}{滤}理字符串,这是你浏览器的身份标识,就像你的身份证一样。这样,网站就会认为你是一个真实的用户,而不是一个自动访问的程序。
3. 循环爬取链接这个程序要爬取多个页面的文章链接,所以它设置了一个循环来重复爬取1到5页面的链接。每爬取一个页面,它就会获取页面上所有的文章链接,并打印出来。
4. 解析链接并下载文章对于每个找到的文章链接,程序会发送一个GET请求来获取链接的内容。然后它用BeautifulSoup来解析获取到的HTML内容,找到下载链接,并下载文章的内容。
5. 保存文章为.zip文件最后,程序会将下载的内容保存为一个.zip格式的压缩文件。文件名会根据下载的顺序来编号,比如"1.zip"、"2.zip"等等。以上就是这段代码的基本解释。希望这个解释能够帮助你更好地理解这段代码。如果你还有其他问题,欢迎随时向我提问!这段代码的主要目的是从指定的网站(http://www.ypppt.com/moban/lunwen/)抓取一些文章链接,并下载这些文章的内容,保存为.zip格式的压缩文件。以下是详细的代码解析: - 导入所需的库:
- requests: 用于发送HTTP请求,包括GET和POST请求。
- BeautifulSoup: 用于解析HTML或XML文档,提供便捷的搜索、修改和导航功能。
- time: 用于控制代码的运行速度和等待时间。
- 设置请求头:
- "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Edg/94.0.992.38"
- 这是一个常见的浏览器用户代{过}{滤}理字符串,可以帮助模拟真实的浏览器行为,避免被网站识别为爬虫而进行限制。
- 定义一个循环来爬取所有页面的链接:
- 设定一个变量num用于记录当前下载文件的序号,初始化为1。
- 设定一个变量page用于记录当前爬取的页面,初始化为1。
- 通过循环爬取1到5页面的链接。
- 根据当前页面的不同,构造请求的URL:
- 如果当前页面是第一页,则直接构造URL为"http://www.ypppt.com/moban/lunwen/"。
- 如果当前页面不是第一页,则构造URL为"http://www.ypppt.com/moban/lunwen/list-{}.html".format(page)。"
- 使用列表推导式将URL字符串中的{}替换为page的值。
- 发送GET请求获取网页内容:
- 使用requests库发送GET请求获取网页内容。
- 设置响应的编码为'utf-8'。
- 使用BeautifulSoup库解析网页内容。
- 查找并提取所需的数据:
- 查找所有包含'class'属性值为'posts clear'的<ul>标签。
- 在找到的<ul>标签中查找所有的<li>标签。
- 对于每个<li>标签,提取其中的<a>标签的'href'属性值。
- 使用print函数输出这些链接。
- 对于每个提取到的链接,发送GET请求获取链接的内容:
- 对于每个提取到的链接,使用requests库发送GET请求获取链接的内容。
- 设置响应的编码为响应内容的实际编码。
- 使用BeautifulSoup库解析网页内容。
- 从解析的网页中查找并提取下载链接:
- 在解析的网页中查找'class'属性值为'button'的<div>标签。
- 在找到的<div>标签中查找'class'属性值为'a'的<a>标签的'href'属性值。
- 使用requests库发送GET请求获取下载链接的内容。
- 设置响应的编码为响应内容的实际编码。
- 使用BeautifulSoup库解析网页内容。
- 在解析的网页中查找'class'属性值为'down clear'的<ul>标签。
- 在找到的<ul>标签中查找所有的<li>标签。
- 在找到的<li>标签中查找'class'属性值为'a'的<a>标签的'href'属性值,这就是下载链接。
- 下载并保存文件:
- 对于每个提取到的下载链接,使用requests库发送GET请求获取下载内容。
- 将下载内容保存为一个zip文件,文件名为"num.zip",其中"num"是当前下载文件的序号。
# http://www.ypppt.com/moban/lunwen/list-2.html
# http://www.ypppt.com/moban/lunwen/
# /html/body/div[2]/div/ul/li[1]/a
from bs4 import BeautifulSoup
import requests
import time
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Edg/94.0.992.38"
}
time.sleep(4)
num = 1
page = 1
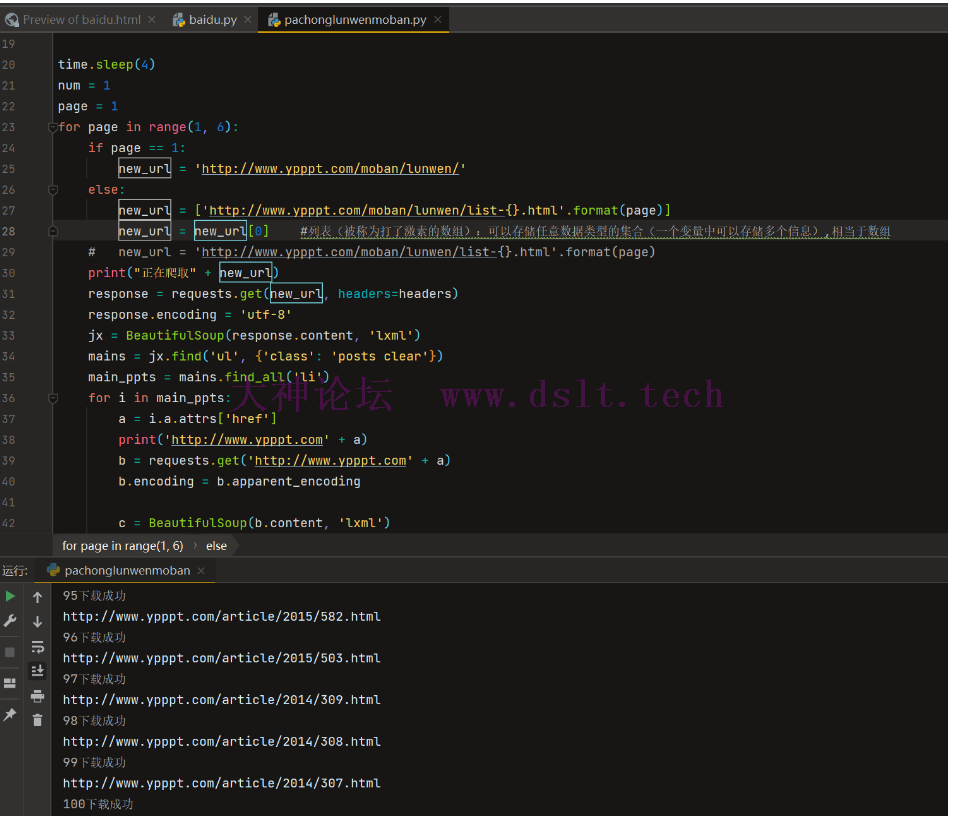
for page in range(1, 6):
if page == 1:
new_url = 'http://www.ypppt.com/moban/lunwen/'
else:
new_url = ['http://www.ypppt.com/moban/lunwen/list-{}.html'.format(page)]
new_url = new_url[0] #列表(被称为打了激素的数组):可以存储任意数据类型的集合(一个变量中可以存储多个信息),相当于数组
# new_url = 'http://www.ypppt.com/moban/lunwen/list-{}.html'.format(page)
print("正在爬取" + new_url)
response = requests.get(new_url, headers=headers)
response.encoding = 'utf-8'
jx = BeautifulSoup(response.content, 'lxml')
mains = jx.find('ul', {'class': 'posts clear'})
main_ppts = mains.find_all('li')
for i in main_ppts:
a = i.a.attrs['href']
print('http://www.ypppt.com' + a)
b = requests.get('http://www.ypppt.com' + a)
b.encoding = b.apparent_encoding
c = BeautifulSoup(b.content, 'lxml')
down = c.find('div', {'class': 'button'})
down1 = down.a.attrs['href']
down_1 = requests.get('http://www.ypppt.com' + down1)
down_1.encoding = down_1.apparent_encoding
down_2 = BeautifulSoup(down_1.content, 'lxml')
e = down_2.find('ul', {'class': 'down clear'})
f = e.find('li')
downlaod_url = f.a.attrs['href']
download = requests.get(url=downlaod_url, headers=headers).content
with open(str(num) + '.zip', 'wb') as f:
f.write(download)
print(str(num) + '下载成功')
num += 1
注:若转载请注明大神论坛来源(本贴地址)与作者信息。
|
 发表于 2023-12-02 08:24
发表于 2023-12-02 08:24





 评分
评分 顶
顶 踩
踩 扫码赞助
扫码赞助