本帖最后由 mmortalyi 于 2023-12-23 23:33 编辑
题目题目名称:decode_me 附件:https://dslt.lanzouv.com/iR2ww1is558b 非常简单粗暴的一题,直接丢个文件过来,要求找出 flag
文件格式判断拿到文件,先判断一下文件格式,丢入 PE 工具:Detect It Easy 里看一下: 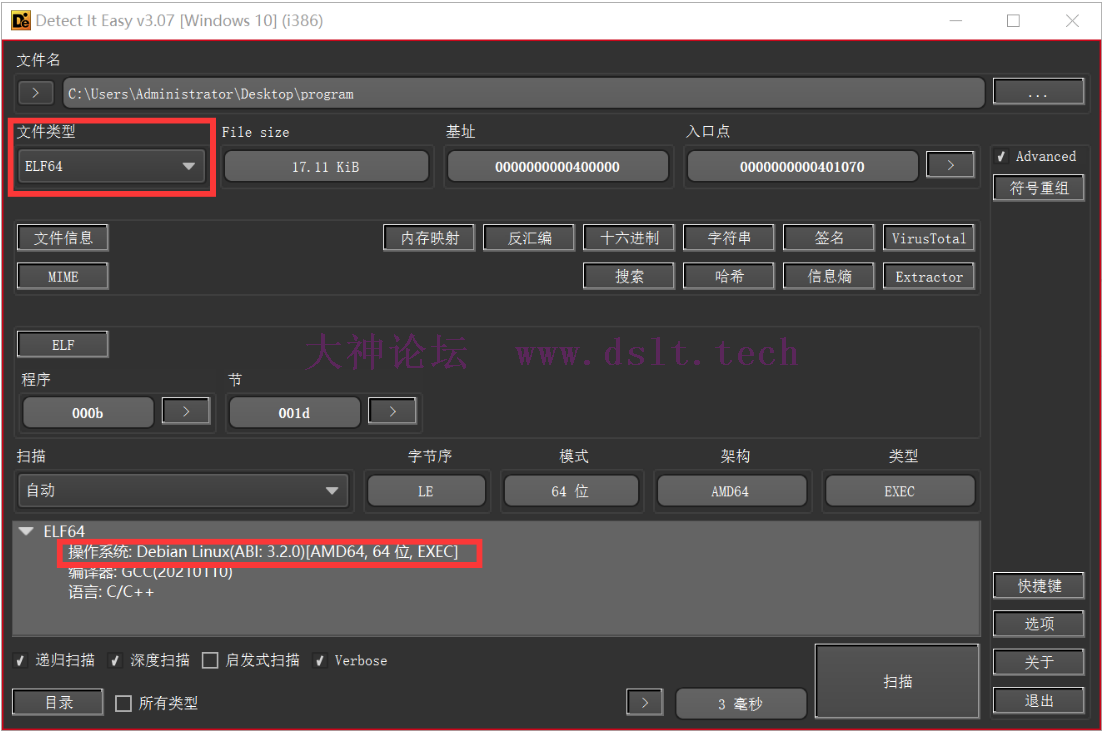
可以看到是 ELF64 的文件格式,可以在 Linux 64 位系统上运行
IDA 解析把文件直接拖入 IDA Pro 64 得到: 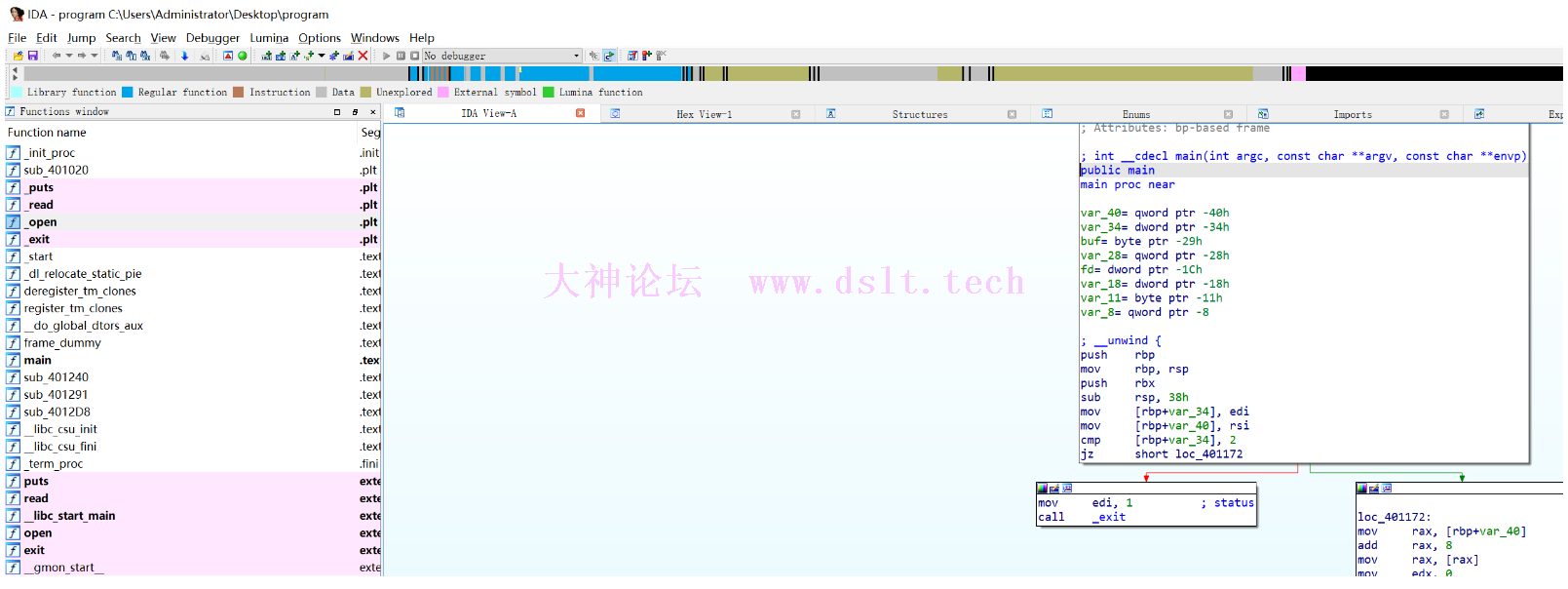
自动定位到了 main 函数入口,直接按 F5 生成伪代码看看: int __cdecl main(int argc, const char **argv, const char **envp)
{
char v3; // bl
char buf; // [rsp+17h] [rbp-29h] BYREF
ssize_t v6; // [rsp+18h] [rbp-28h]
int fd; // [rsp+24h] [rbp-1Ch]
unsigned int v8; // [rsp+28h] [rbp-18h]
char v9; // [rsp+2Fh] [rbp-11h]
if ( argc != 2 )
exit(1);
fd = open(argv[1], 0, 0LL);
if ( fd == -1 )
exit(1);
v8 = 0;
v9 = 0;
while ( v8 <= 0x224 )
{
v6 = read(fd, &buf, 1uLL);
if ( v6 <= 0 )
break;
v3 = byte_404060[v8];
v9 |= v3 ^ sub_4012D8((unsigned int)buf, v8++);
}
if ( !v9 )
puts("[+] Correct one!");
return 0;
}
伪代码很简洁,感觉很简单.jpg 忽略掉伪代码里不确定的部分,可以大致分析出对应的逻辑 int main(){
//如果参数个数不为2 则自动退出
if(argc !=2){
exit(1);
}
//打开参数对应路径的文件,PS:argv[0] 是运行路径,argv[1] 才是真正的参数
fd = open(argv[1], 0, 0LL);
//如果文件打开失败则退出
if ( fd == -1 )
exit(1);
//这里重命名为 index 是根据下面 while 循环对数组的遍历可以推断出这是下标
int index = 0;
//这里重命名为 flag 是根据最下面输出 Correct one 判断这个是个标记
int flag = 0;
while(index <= 0x224){
//每次从文件里读 1 个字节,如果读不到就终止
ssize_t read_bytes = read(fd, &buf, 1uLL);
if ( read_bytes <= 0 ){
break;
}
//从某个数组里根据下标读取值
key = byte_404060[index];
//计算 flag
flag |= (key ^ sub_4012D8((unsigned int)buf, index++));
}
//如果 flag = 0 才输出正确
if ( !flag )
puts("[+] Correct one!");
return 0;
}
伪代码很简洁,感觉很简单.jpg 忽略掉伪代码里不确定的部分,可以大致分析出对应的逻辑 int main(){
//如果参数个数不为2 则自动退出
if(argc !=2){
exit(1);
}
//打开参数对应路径的文件,PS:argv[0] 是运行路径,argv[1] 才是真正的参数
fd = open(argv[1], 0, 0LL);
//如果文件打开失败则退出
if ( fd == -1 )
exit(1);
//这里重命名为 index 是根据下面 while 循环对数组的遍历可以推断出这是下标
int index = 0;
//这里重命名为 flag 是根据最下面输出 Correct one 判断这个是个标记
int flag = 0;
while(index <= 0x224){
//每次从文件里读 1 个字节,如果读不到就终止
ssize_t read_bytes = read(fd, &buf, 1uLL);
if ( read_bytes <= 0 ){
break;
}
//从某个数组里根据下标读取值
key = byte_404060[index];
//计算 flag
flag |= (key ^ sub_4012D8((unsigned int)buf, index++));
}
//如果 flag = 0 才输出正确
if ( !flag )
puts("[+] Correct one!");
return 0;
}
简单分析可以得出逻辑: 读取传入的参数作为要读取文件的路径 按字节读取文件内容,然后计算 Flag 最终判断 flag 是否为 0,为 0 才是正解
可以传入的参数也就是要读取的文件路径其实并不重要 重要的是要读取的文件里面的内容,得想办法逆推这个内容
算法的核心就在于 //计算 flag
flag |= (key ^ sub_4012D8((unsigned int)buf, index++));
结合最后的判断,flag 必须为 0,可以推断出: (key ^ sub_4012D8((unsigned int)buf, len++)) 必须一直为 0 PS:0 只有与 0 进行 或运算结果才为 0
这里的 key 十分简单,就是个固定的数组 byte_404060 用 IDA 双击查看: 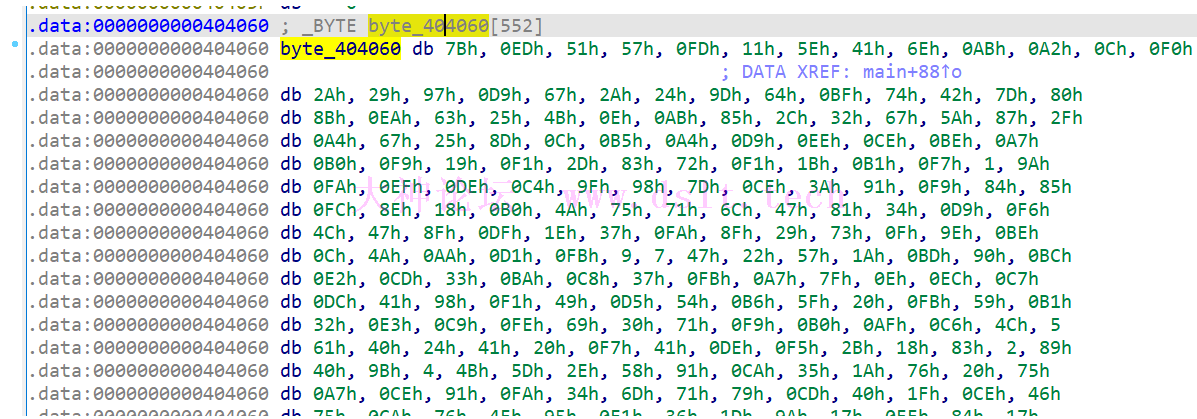
直接把这里的数组先拷出来,拷贝前面 while 循环的长度:0x224 (IDA 这里解析的并不准确,多了 4 字节是 552): byte_404060 = [0x7b, 0xed, 0x51, 0x57, 0xfd, 0x11, 0x5e, 0x41, 0x6e, 0xab, 0xa2, 0x0c, 0xf0, 0x2a, 0x29, 0x97, 0xd9, 0x67, 0x2a, 0x24, 0x9d, 0x64, 0xbf, 0x74, 0x42, 0x7d, 0x80, 0x8b, 0xea, 0x63, 0x25, 0x4b, 0x0e, 0xab, 0x85, 0x2c, 0x32, 0x67, 0x5a, 0x87, 0x2f, 0xa4, 0x67, 0x25, 0x8d, 0x0c, 0xb5, 0xa4, 0xd9, 0xee, 0xce, 0xbe, 0xa7, 0xb0, 0xf9, 0x19, 0xf1, 0x2d, 0x83, 0x72, 0xf1, 0x1b, 0xb1, 0xf7, 0x01, 0x9a, 0xfa, 0xef, 0xde, 0xc4, 0x9f, 0x98, 0x7d, 0xce, 0x3a, 0x91, 0xf9, 0x84, 0x85, 0xfc, 0x8e, 0x18, 0xb0, 0x4a, 0x75, 0x71, 0x6c, 0x47, 0x81, 0x34, 0xd9, 0xf6, 0x4c, 0x47, 0x8f, 0xdf, 0x1e, 0x37, 0xfa, 0x8f, 0x29, 0x73, 0x0f, 0x9e, 0xbe, 0x0c, 0x4a, 0xaa, 0xd1, 0xfb, 0x09, 0x07, 0x47, 0x22, 0x57, 0x1a, 0xbd, 0x90, 0xbc, 0xe2, 0xcd, 0x33, 0xba, 0xc8, 0x37, 0xfb, 0xa7, 0x7f, 0x0e, 0xec, 0xc7, 0xdc, 0x41, 0x98, 0xf1, 0x49, 0xd5, 0x54, 0xb6, 0x5f, 0x20, 0xfb, 0x59, 0xb1, 0x32, 0xe3, 0xc9, 0xfe, 0x69, 0x30, 0x71, 0xf9, 0xb0, 0xaf, 0xc6, 0x4c, 0x05, 0x61, 0x40, 0x24, 0x41, 0x20, 0xf7, 0x41, 0xde, 0xf5, 0x2b, 0x18, 0x83, 0x02, 0x89, 0x40, 0x9b, 0x04, 0x4b, 0x5d, 0x2e, 0x58, 0x91, 0xca, 0x35, 0x1a, 0x76, 0x20, 0x75, 0xa7, 0xce, 0x91, 0xfa, 0x34, 0x6d, 0x71, 0x79, 0xcd, 0x40, 0x1f, 0xce, 0x46, 0x75, 0xca, 0x76, 0x4f, 0x95, 0xe1, 0x36, 0x1d, 0x9a, 0x17, 0xff, 0x84, 0x17, 0x15, 0x5e, 0x6d, 0x89, 0x6c, 0x33, 0xa8, 0xde, 0x08, 0x66, 0x92, 0xe7, 0x27, 0x1a, 0x95, 0xeb, 0x48, 0xb7, 0xf6, 0xf1, 0xf1, 0x15, 0x37, 0x71, 0x02, 0x70, 0x27, 0x8d, 0x1c, 0x4d, 0xb5, 0x20, 0x9b, 0x1e, 0x0a, 0x7e, 0xcf, 0x18, 0xfb, 0xf2, 0x9e, 0x65, 0xa1, 0x6d, 0xc3, 0x81, 0xaa, 0x6c, 0x77, 0xae, 0xfd, 0xbd, 0x2b, 0xfd, 0xe9, 0xcd, 0x8c, 0xc1, 0x90, 0xb4, 0x68, 0xe9, 0x3f, 0xd2, 0xaf, 0x52, 0x45, 0xce, 0xe9, 0x01, 0xba, 0x21, 0xc5, 0x4e, 0x7d, 0xad, 0xd4, 0x2d, 0xb9, 0x9e, 0x81, 0xbd, 0xc3, 0x92, 0xad, 0x3b, 0x28, 0x05, 0x5b, 0xe5, 0x41, 0xfe, 0x50, 0x85, 0x04, 0xe7, 0xb4, 0x78, 0x83, 0xc3, 0x4c, 0x9a, 0x3d, 0xde, 0xf8, 0xbb, 0x50, 0xce, 0xbd, 0x19, 0x73, 0x5a, 0xcb, 0x52, 0x9b, 0x4e, 0xf3, 0x31, 0xf3, 0x9d, 0xbd, 0x9e, 0x5d, 0x6d, 0x38, 0xb2, 0xea, 0x74, 0xdb, 0xf6, 0x3e, 0x9b, 0xa9, 0xe9, 0x99, 0x81, 0x49, 0x9a, 0xe2, 0x89, 0x17, 0x89, 0x1a, 0x4d, 0x37, 0xde, 0xa4, 0xfd, 0x18, 0xfc, 0x93, 0x2e, 0x61, 0xc9, 0x1e, 0x6e, 0xdd, 0x3d, 0xd3, 0x11, 0x6f, 0x03, 0x0c, 0x76, 0xb4, 0x41, 0x14, 0xfe, 0xb1, 0xe6, 0x07, 0x9d, 0x4c, 0xf9, 0xf3, 0x51, 0x68, 0xe9, 0xca, 0xf5, 0x59, 0x60, 0xdb, 0xa1, 0x6b, 0xab, 0x2a, 0xd8, 0x61, 0xd1, 0x53, 0x1b, 0x81, 0x3a, 0x6d, 0xa2, 0x74, 0xe7, 0xd5, 0xba, 0x4c, 0xa9, 0x64, 0x25, 0x4e, 0xbd, 0xab, 0x31, 0xfb, 0x95, 0xd2, 0x4e, 0x09, 0xaf, 0x6b, 0xf1, 0x41, 0x38, 0xfd, 0x19, 0x1f, 0x2e, 0x99, 0xcc, 0xbc, 0x3a, 0xbe, 0x55, 0xe1, 0xbe, 0xc4, 0x83, 0x4c, 0x45, 0x7b, 0xd5, 0xc4, 0xe2, 0x92, 0xb7, 0xb5, 0x11, 0xc4, 0x27, 0x98, 0xbe, 0x69, 0xcd, 0x0c, 0x41, 0x26, 0x22, 0xa9, 0x86, 0xbf, 0xeb, 0x1c, 0xcd, 0x65, 0xda, 0x37, 0x0f, 0x80, 0xe7, 0xe2, 0x1e, 0xeb, 0x39, 0x8f, 0xfb, 0x92, 0x4c, 0x76, 0x3d, 0x4a, 0x0f, 0x39, 0x98, 0x4d, 0xeb, 0x43, 0x65, 0xd5, 0xa0, 0x80, 0x03, 0x1a, 0x66, 0x8b, 0x80, 0xbc, 0x73, 0x06, 0xa4, 0xbb, 0xa2, 0x79, 0x68, 0x0e, 0x10, 0x9a, 0xbd, 0x01, 0xd3, 0xd0, 0xf2, 0xf4, 0x04, 0x04, 0x17, 0x1c, 0xe8, 0x3d, 0x0e, 0x56, 0x5e, 0xa3, 0x5d, 0x1b, 0x26, 0x7b, 0x5a, 0xb7, 0x3b, 0x59, 0x60, 0x1b, 0x1d, 0x2f, 0xe9, 0x75, 0x14, 0x24, 0x41, 0x8b, 0x7e, 0xe1, 0x3d ]
所以重点就在于 sub_4012D8((unsigned int)buf, index++) 这个函数的算法了 函数的参数很简单,buf :读取进来的文件内容;index:当前下标
双击用 IDA 查看这个函数: __int64 __fastcall sub_4012D8(__int64 a1, __int64 a2)
{
__int64 v3; // [rsp+0h] [rbp-8h]
v3 = sub_401291();
return v3 ^ sub_401240(a2);
}
根据前面可以得知 这 2 个参数的含义,对应修改下参数类型和参数名称 //buf 从文件中读出来的字符
//index 当前读取文件的对应偏移(下标)
__int64 __fastcall sub_4012D8(char buf, __int64 index)
{
__int64 ret; // rax
//暂时不清楚是干什么的运算
ret = sub_401291();
//把前面返回的结果和另一个函数得到的结果做 xor 运算返回
//这个函数传入当前下标,返回一个结果
return ret ^ sub_401240(index);
}
接下来看第一个函数 sub_401291,依旧直接用 IDA 双击点进去: // positive sp value has been detected, the output may be wrong!
void sub_401291()
{
__asm { jmp off_404388[rax] }
}
QAQ:好像没办法直接反编译出伪代码,得啃一下汇编了
退出伪代码界面(Pseudocode) 转到 IDA View 界面查看汇编 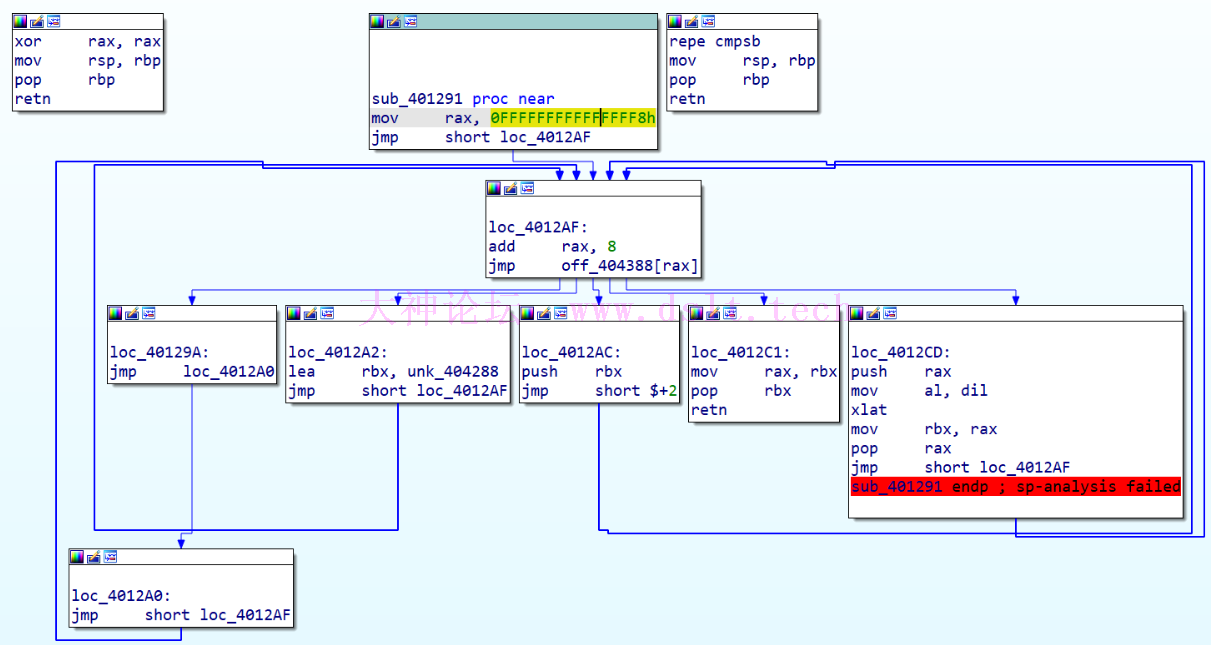
先看前半部分: 00000000401291 sub_401291 proc near ; CODE XREF: sub_4012D8+C↓p
.text:0000000000401291 mov rax, 0FFFFFFFFFFFFFFF8h
.text:0000000000401298 jmp short loc_4012AF
0000000004012AF loc_4012AF: ; CODE XREF: sub_401291+7↑j
.text:00000000004012AF ; sub_401291:loc_4012A0↑j ...
.text:00000000004012AF add rax, 8
.text:00000000004012B3 jmp off_404388[rax]
也就是: # rax = -8
mov rax, 0FFFFFFFFFFFFFFF8h
# rax = rax + 8 也就是 -8 + 8 = 0
add rax,8
# 跳转到 404388 这个数组里偏移为 rax 的数据对应的地址
# 根据上面的图,可以看出来一共有 5 个地址可跳转(分出来了 5 个分支)
jmp off_404388[rax]
看一下 off_404388 里存储的内容: 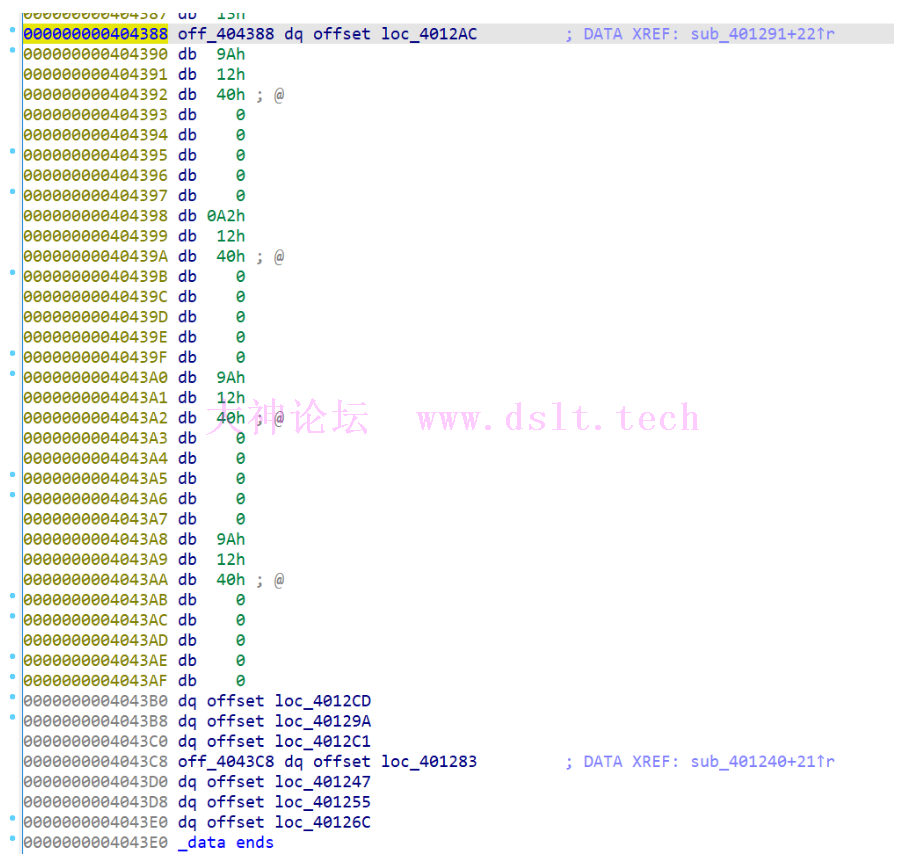
根据 rax 每次是 +8 ,调整一下后面数据的类型为 qword (8 字节) 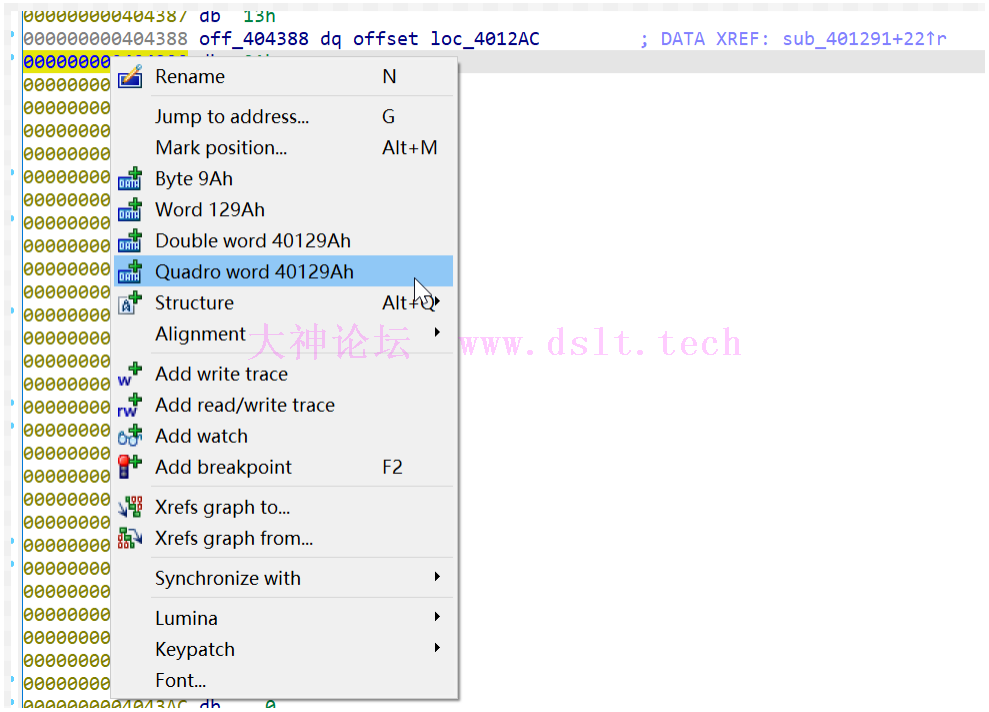
PS:选中对应段按 q 也可以改成 qword 格式
全部调整完得到: 00000000404388 off_404388 dq offset loc_4012AC ; DATA XREF: sub_401291+22↑r
.data:0000000000404390 dq offset loc_40129A
.data:0000000000404398 dq offset loc_4012A2
.data:00000000004043A0 dq offset loc_40129A
.data:00000000004043A8 dq offset loc_40129A
.data:00000000004043B0 dq offset loc_4012CD
.data:00000000004043B8 dq offset loc_40129A
.data:00000000004043C0 dq offset loc_4012C1
.data:00000000004043C8 off_4043C8 dq offset loc_401283 ; DATA XREF: sub_401240+21↑r
.data:00000000004043D0 dq offset loc_401247
.data:00000000004043D8 dq offset loc_401255
.data:00000000004043E0 dq offset loc_40126C
.data:00000000004043E0 _data ends
结合下半部分的逻辑 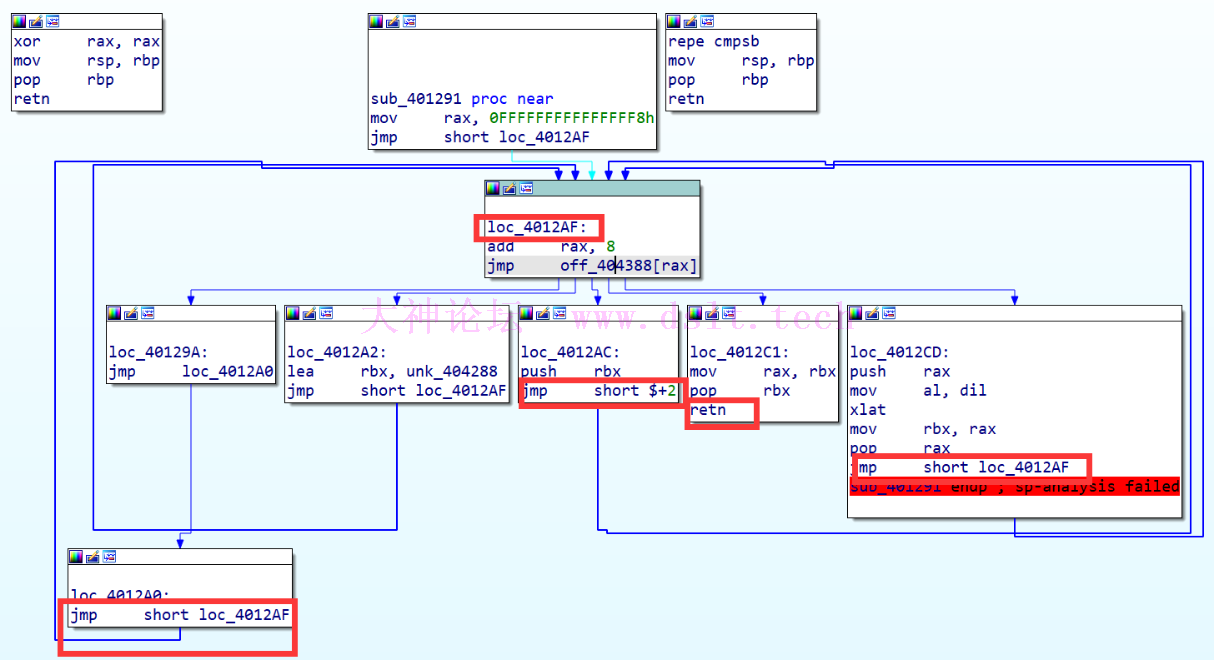
只有 loc_4012C1 的逻辑有 retn,其他部分都是跳转回去继续执行 可以推断出这部分的逻辑是按顺序执行 off_404388 这个数组里的存储的函数地址,直到执行完 loc_4012C1 retn 返回 按数组里的顺序依次分析对应的函数: 00000000404388 off_404388 dq offset loc_4012AC ; DATA XREF: sub_401291+22↑r
.data:0000000000404390 dq offset loc_40129A
.data:0000000000404398 dq offset loc_4012A2
.data:00000000004043A0 dq offset loc_40129A
.data:00000000004043A8 dq offset loc_40129A
.data:00000000004043B0 dq offset loc_4012CD
.data:00000000004043B8 dq offset loc_40129A
.data:00000000004043C0 dq offset loc_4012C1
第一个函数:loc_4012AC loc_4012AC:
# 将 rbx 压入堆栈,但这里的 rbx 是什么? 动态调试瞅瞅吧
push rbx
# 跳转回去
jmp short $+2
动态调试环境搭建前面在文件格式判断里得出了这个文件是 ELF64 且运行在 Linux AMD64上,所以需要搞个 linux AMD64 的环境 我是用 vmware 搞了个 centos 7.9 的 环境: 
PS:vmware 安装 centos 的教程网上一抓一大把,这里就不展开了
把要调试的程序 program 传到 centos7.9 上,可以用 Winscp 或者 xftp 等软件 然后赋予权限: chmod +x program
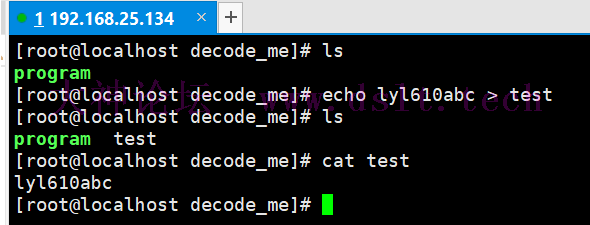
根据前面的分析得知,调用时需要给一个文件路径 于是在同个目录下随便创建个文件,然后随便给点字符串 #将字符串 "lyl610abc" 写出到 test 文件
echo lyl610abc > test
打开 IDA Pro 的安装目录找到 dbgsrv : 
打开得到: 
把 linux_server64 拷贝到 centos7.9 上,赋予访问权限,然后运行 chmod +x linux_server64
./linux_server64

为避免可能存在防火墙导致无法连接可以下面命令关闭: systemctl stop firewalld.service
回到 IDA Pro,选择调试器为 Remote Linux debugger 
Debugger → Process options 设置要调试的应用 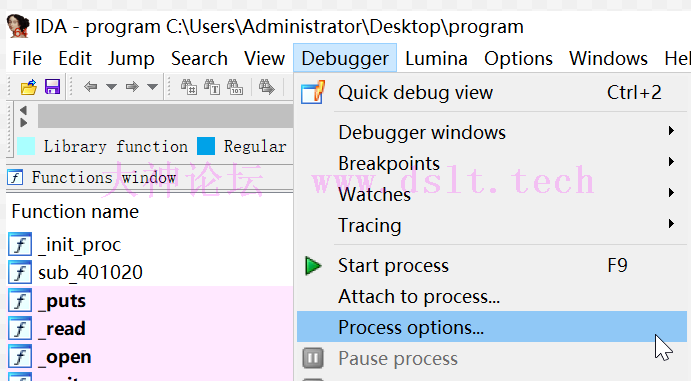
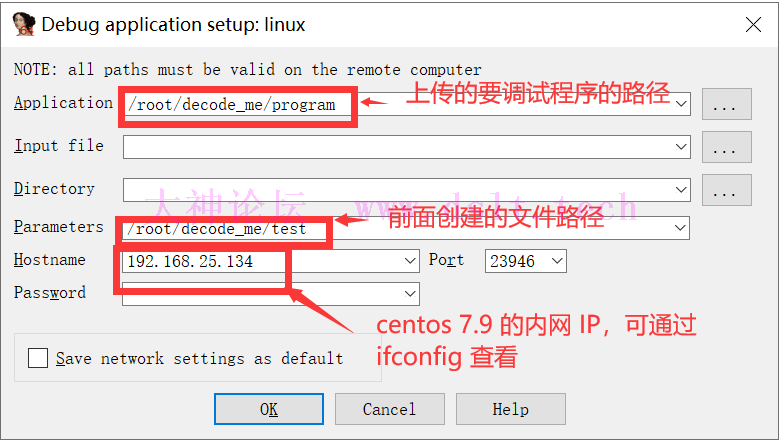
设置好以后,随便找个地方下个断点验证下是否能正常调试 这里选 main 函数的开头 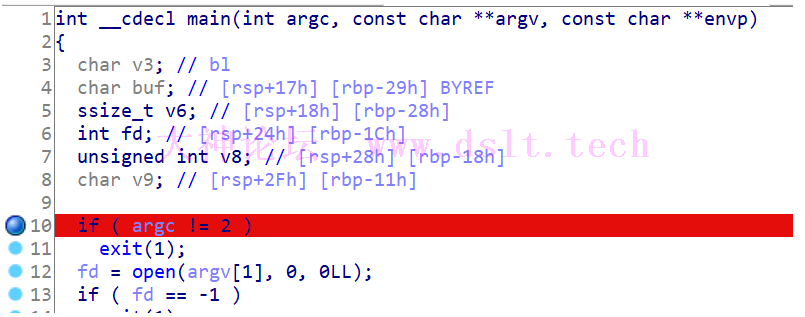
然后按快捷键 F9 运行 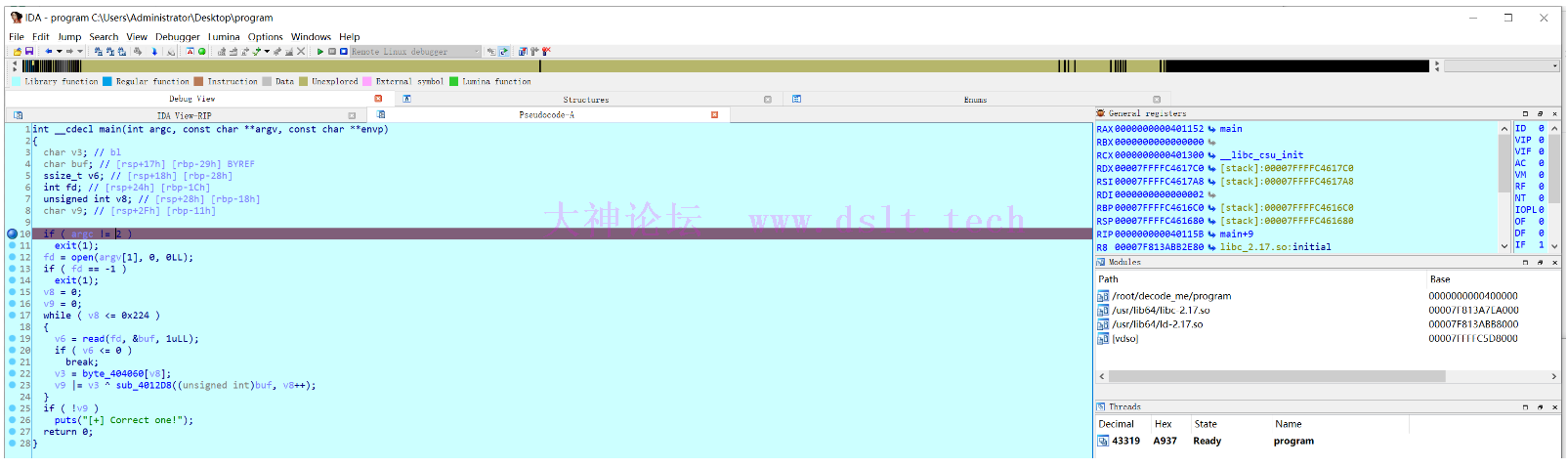
到这里动态调试环境的搭建完毕了
动态调试继续回到前面要分析的地方,为避免往上翻,再贴一遍: 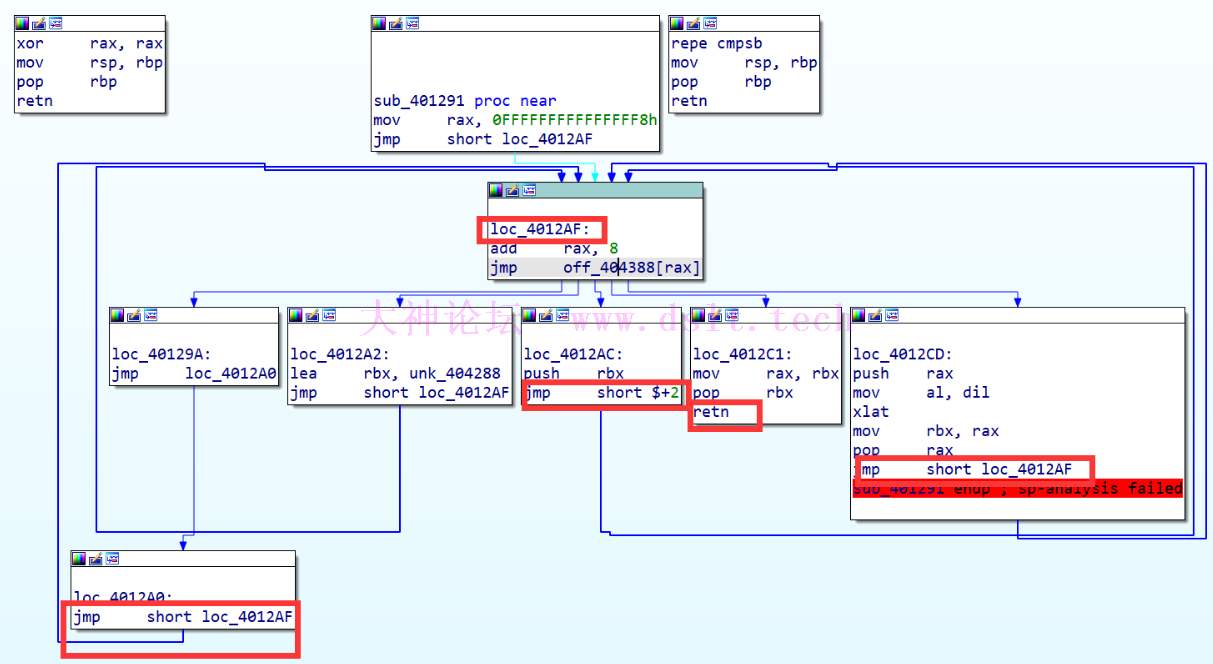
按数组里的顺序依次分析对应的函数: 00000000404388 off_404388 dq offset loc_4012AC ; DATA XREF: sub_401291+22↑r
.data:0000000000404390 dq offset loc_40129A
.data:0000000000404398 dq offset loc_4012A2
.data:00000000004043A0 dq offset loc_40129A
.data:00000000004043A8 dq offset loc_40129A
.data:00000000004043B0 dq offset loc_4012CD
.data:00000000004043B8 dq offset loc_40129A
.data:00000000004043C0 dq offset loc_4012C1
第一个函数:loc_4012AC 在 loc_4012AC 下个断点,然后断下来后查看对应值 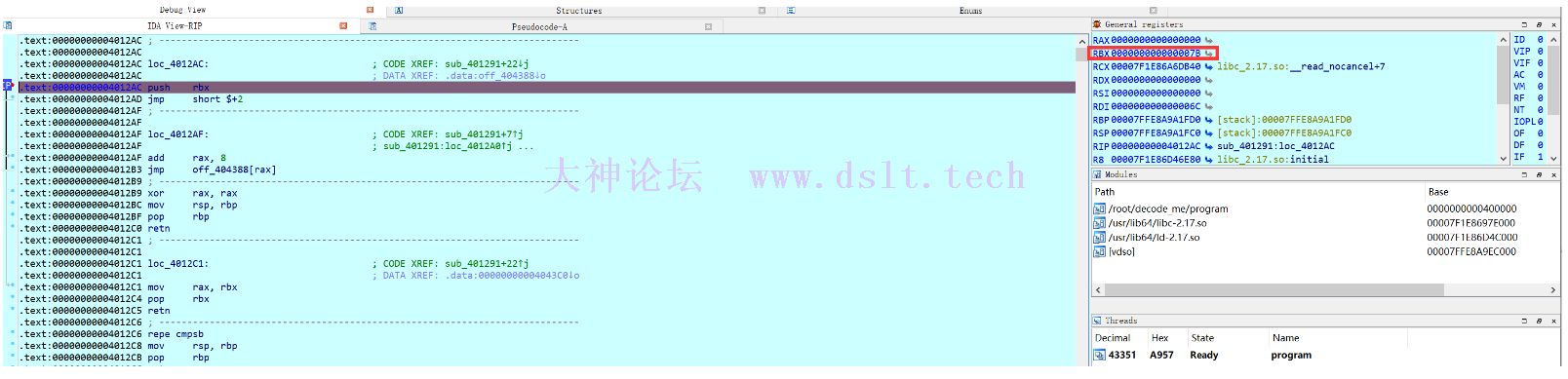
可以看到 rbx 的值是 0x7b,这个值是不是似曾相识,这正是前面拷贝数组里第一个下标的值: byte_404060 = [0x7b, 0xed, 0x51, 0x57, 0xfd, 0x11, 0x5e, 0x41, 0x6e, 0xab, 0xa2, 0x0c, 0xf0, 0x2a, 0x29, 0x97, 0xd9, 0x67, 0x2a, 0x24, 0x9d, 0x64, 0xbf, 0x74, 0x42, 0x7d, 0x80 ......]
避免再往上翻,贴一遍引用到的地方 int main(){
//如果参数个数不为2 则自动退出
if(argc !=2){
exit(1);
}
//打开参数对应路径的文件,PS:argv[0] 是运行路径,argv[1] 才是真正的参数
fd = open(argv[1], 0, 0LL);
//如果文件打开失败则退出
if ( fd == -1 )
exit(1);
//这里重命名为 index 是根据下面 while 循环对数组的遍历可以推断出这是下标
int index = 0;
//这里重命名为 flag 是根据最下面输出 Correct one 判断这个是个标记
int flag = 0;
while(index <= 0x224){
//每次从文件里读 1 个字节,如果读不到就终止
ssize_t read_bytes = read(fd, &buf, 1uLL);
if ( read_bytes <= 0 ){
break;
}
//从某个数组里根据下标读取值
key = byte_404060[index];
//计算 flag
flag |= (key ^ sub_4012D8((unsigned int)buf, index++));
}
//如果 flag = 0 才输出正确
if ( !flag )
puts("[+] Correct one!");
return 0;
}
所以这里的 rbx 就是 byte_404060[index] 也就是 key 先记下,接着看第二个函数:loc_40129A loc_40129A:
jmp loc_4012A0
loc_4012A0:
jmp short loc_4012AF
这个函数啥都没做,就是直接跳转到下一个函数
第三个函数:loc_4012A2 loc_4012A2:
# rbx = unk_404288
lea rbx, unk_404288
# 跳回去
jmp short loc_4012AF
调试可以看到,执行完 lea rbx, unk_404288 后 rbx 就等于 unk_404288 了 
第四、五个函数:loc_40129A 在第二个函数里分析过了,啥都没做,略过 第六个函数:loc_4012CD loc_4012CD:
# 把 rax 压入堆栈
push rax
# rax 的低 8 位 等于 rdi 的低 8 位
mov al, dil
# mov al,[(E)BX + unsigned AL], ebx这个地址指向的是一个数组,从数组里取出 al 偏移的值 赋值给 al
xlat
# rbx = rax
mov rbx, rax
# 把 rax 弹出堆栈 还原rax
pop rax
# 跳回去
jmp short loc_4012AF
按顺序执行观察寄存器情况: push rax 执行前 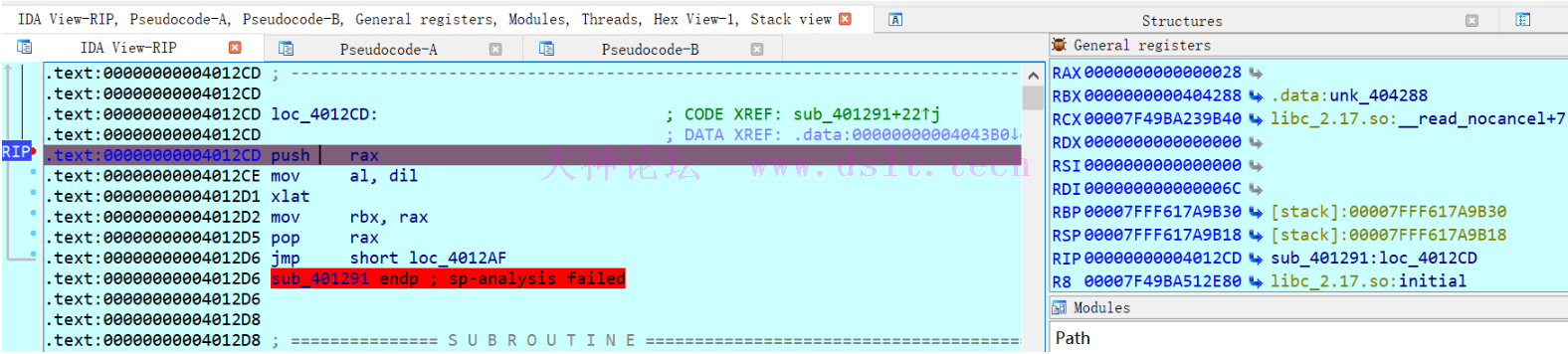
push rax 执行后,mov al,dil执行前 可以看到只有堆栈 RSP RIP变化了,毕竟只是个入栈操作 
mov al,dil 执行后,xlat 执行前 可以看到这里 al = 6C,这个 6C 对应的 ascii 码 是 l ,也就是我们给的文件内容("lyl610abc")的第一个字符 前面已经说明了 xlat 的作用:mov al,[(E)BX + unsigned AL], ebx这个地址指向的是一个数组,从数组里取出 al 偏移的值 赋值给 al 此时的 ebx 对应的正是一个数组,从这个数组里取出偏移为输入字符 ascii 码的值 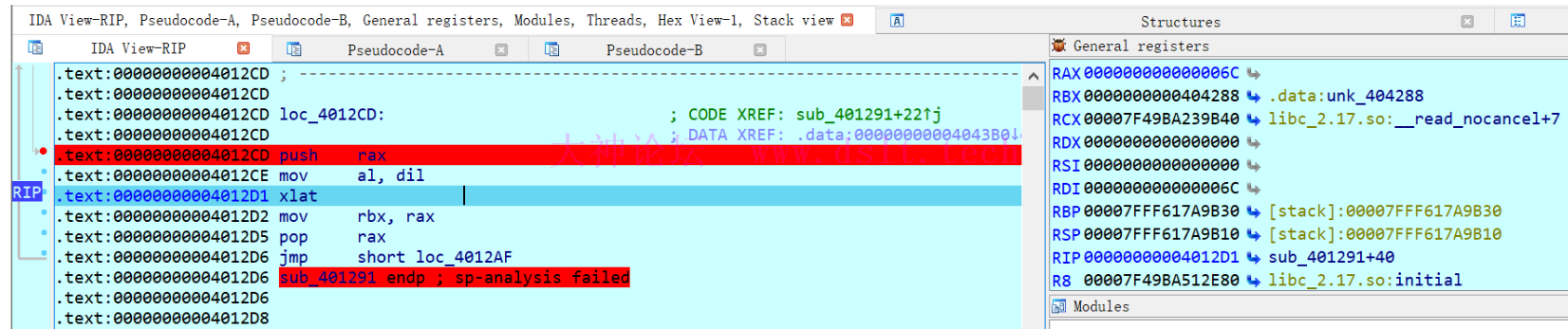
按照 xlat 的计算式子,看一下 ebx+al 对应的内容 404288 + 6c = 4042F4 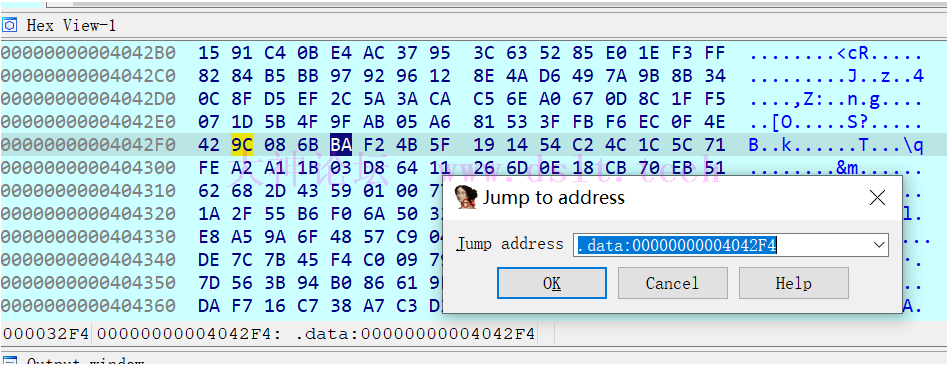
对应的值为 BA
xlat 执行后,mov rbx,rax 执行前 可以看到 RAX 果然变为了 BA ,和推断的一致 
后面的 mov rbx,rax 以及 pop rax 很简单,就不再贴图了 归纳一下 loc_4012CD 这个函数的作用 将 rbx 设置为:unk_404288 这个数组里对应我们输入文件内容的偏移的数,即:rbx = unk_404288[buf]
第七个函数:loc_40129A 在第二个函数里分析过了,啥都没做,略过
第八个函数:loc_4012C1 loc_4012C1:
mov rax, rbx
pop rbx
retn
将 rax 作为返回值返回,在这里下个断点看下此时的 rax 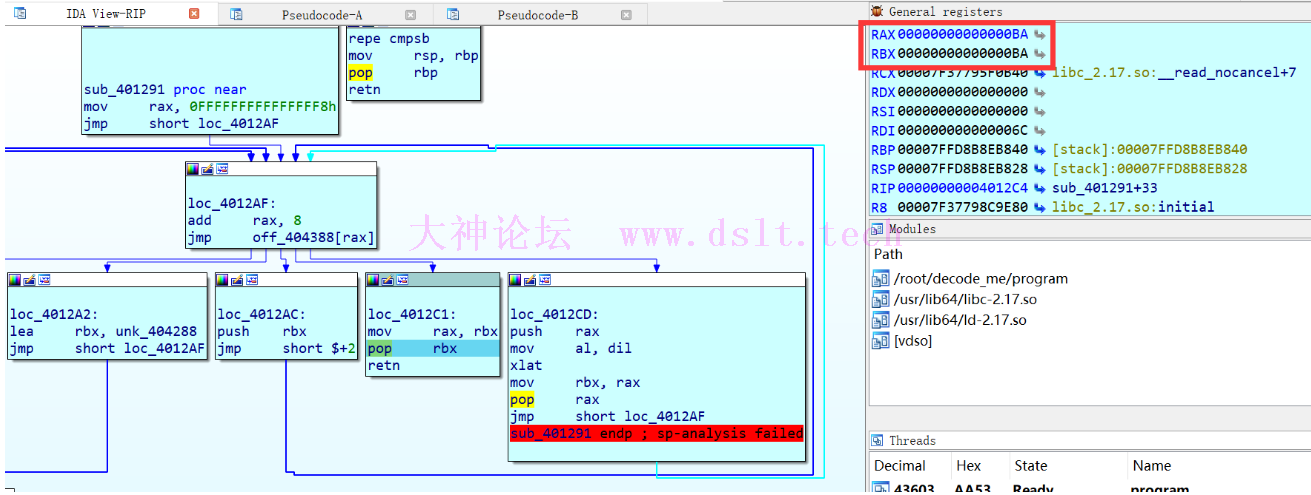
可以发现这里的 rax 就是前面计算得到的 BA
综合上面函数的分析,可以得出这里的逻辑就是从 unk_404288 这个数组里找传入参数偏移的对应的数据返回 可以写出对应的伪代码: //传入的参数为从文件中读出来的字符
int sub_401291(char buf){
return unk_404288[buf];
}
所以这里再保存一下 unk_404288 这个数组,后面逆推要用到: 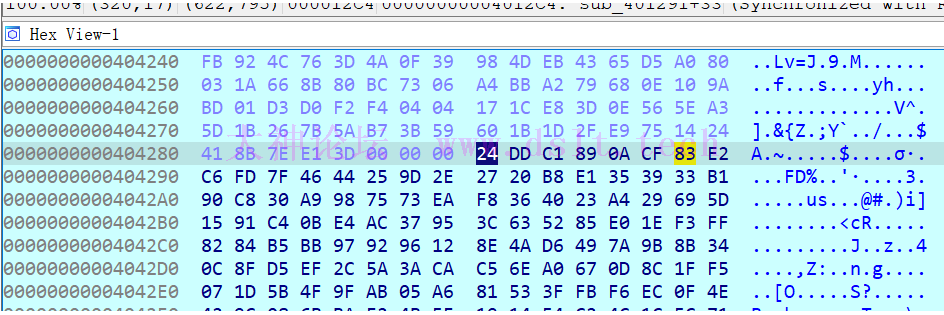
PS:这里用的是十进制,上图是十六进制 unk_404288 = [36, 221, 193, 137, 10, 207, 131, 226, 198, 253, 127, 70, 68, 37, 157, 46, 39, 32, 184, 225, 53, 57, 51, 177, 144, 200, 48, 169, 152, 117, 115, 234, 248, 54, 64, 35, 164, 41, 105, 93, 21, 145, 196, 11, 228, 172, 55, 149, 60, 99, 82, 133, 224, 30, 243, 255, 130, 132, 181, 187, 151, 146, 150, 18, 142, 74, 214, 73, 122, 155, 139, 52, 12, 143, 213, 239, 44, 90, 58, 202, 197, 110, 160, 103, 13, 140, 31, 245, 7, 29, 91, 79, 159, 171, 5, 166, 129, 83, 63, 251, 246, 236, 15, 78, 66, 156, 8, 107, 186, 242, 75, 95, 25, 20, 84, 194, 76, 28, 92, 113, 254, 162, 161, 27, 3, 216, 100, 17, 38, 109, 14, 24, 203, 112, 235, 81, 98, 104, 45, 67, 89, 1, 0, 119, 88, 170, 189, 230, 49, 238, 135, 223, 26, 47, 85, 182, 240, 106, 80, 50, 101, 6, 180, 118, 217, 34, 108, 190, 232, 165, 154, 111, 72, 87, 201, 4, 249, 205, 212, 219, 33, 233, 43, 174, 222, 124, 123, 69, 244, 192, 9, 121, 147, 250, 229, 77, 163, 206, 191, 179, 125, 86, 59, 148, 176, 134, 97, 158, 227, 252, 208, 138, 42, 102, 128, 183, 218, 247, 22, 199, 56, 167, 195, 211, 209, 94, 71, 141, 168, 16, 65, 220, 96, 136, 120, 61, 237, 188, 62, 241, 173, 175, 114, 23, 2, 126, 215, 185, 153, 40, 116, 204, 178, 231, 210, 19]
分析完 sub_401291 接着向下分析 避免上翻,再贴一遍: //buf 从文件中读出来的字符
//index 当前读取文件的对应偏移(下标)
__int64 __fastcall sub_4012D8(char buf, __int64 index)
{
__int64 ret; // rax
//已经分析完的函数,传入参数 buf 返回 unk_404288[buf]
ret = sub_401291(buf);
//把前面返回的结果和另一个函数得到的结果做 xor 运算返回
//这个函数传入当前下标,返回一个结果
return ret ^ sub_401240(index);
}
于是接下来分析 sub_401240 这个函数 __int64 __fastcall sub_401240(__int64 a1, __int64 a2, __int64 a3, __int64 a4, __int64 a5)
{
__int128 v6; // rax
v6 = 0LL;
BYTE8(v6) = 1;
return off_4043C8(a1, a2, *((_QWORD *)&v6 + 1), a4, a5);
}
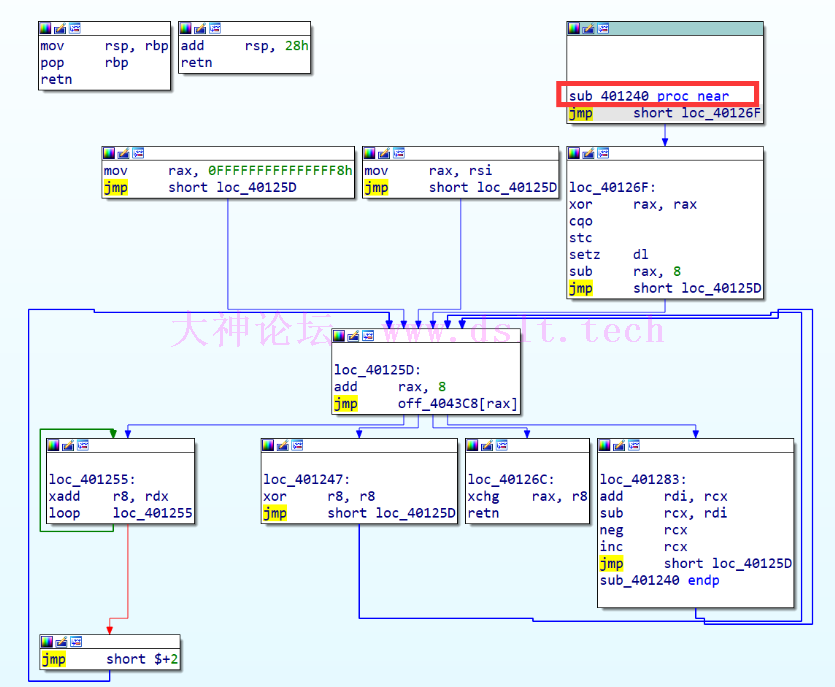
看起来很前面分析完的函数有点类似,都是某个地址里存储着函数的地址,然后一个个跳转到对应的函数
如法炮制,先看前半部分: sub_401240 proc near
# 直接跳转
jmp short loc_40126F
loc_40126F:
# rax = 0,同时 ZF = 1
xor rax, rax
# 将 64 位的有符号整数从 RAX 寄存器扩展到 128 位
# 并存储在 RDX 和 RAX 寄存器中,使 RDX 包含高 64 位,RAX 包含低 64 位
#这样,RDX:RAX 寄存器对可以用于进行 128 位整数运算
cqo
#将CF(Carry Flag,进位标志位)设置为 1
#这个指令的作用是将进位标志位设置为指定的值,通常用于进行二进制加法中的进位操作
stc
#如果 ZF 标志位为 1,则将 DL 寄存器设置为 1 ;否则设置为0
#结合前面 ZF = 1 的操作,这里为 DL = 1
setz dl
# rax = rax - 8 结合前面的 xor eax,eax 运算结果为 -8
sub rax, 8
# 直接跳转
jmp short loc_40125D
loc_40125D:
# rax = rax + 8 ,第一次运行时为 -8 + 8 = 0
add rax, 8
# 跳转到 4043C8 这个数组里偏移为 rax 的数据对应的地址
# 根据上面的图,可以看出来一共有 4 个地址可跳转(分出来了 4 个分支)
jmp off_4043C8[rax]
看一下 off_4043C8 里存储的内容: 
得到: .data:00000000004043C8 off_4043C8 dq offset loc_401283 ; DATA XREF: sub_401240+21↑r
.data:00000000004043D0 dq offset loc_401247
.data:00000000004043D8 dq offset loc_401255
.data:00000000004043E0 dq offset loc_40126C
.data:00000000004043E0 _data ends
结合下半部分的逻辑 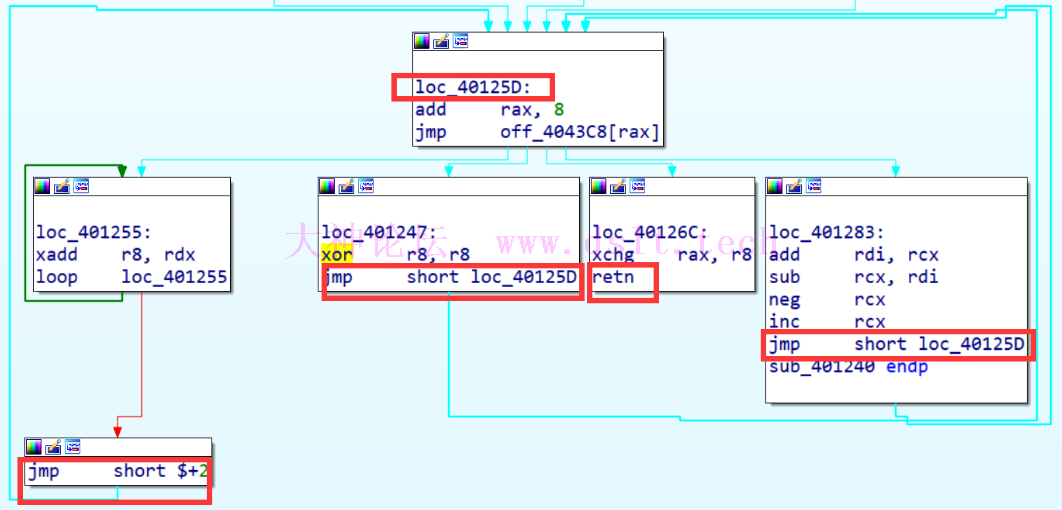
只有 loc_40126C 的逻辑有 retn,其他部分都是跳转回去继续执行 可以推断出这部分的逻辑是按顺序执行 off_4043C8 这个数组里的存储的函数地址,直到执行完 loc_40126C retn 返回 按数组里的顺序依次分析对应的函数: .data:00000000004043C8 off_4043C8 dq offset loc_401283 ; DATA XREF: sub_401240+21↑r
.data:00000000004043D0 dq offset loc_401247
.data:00000000004043D8 dq offset loc_401255
.data:00000000004043E0 dq offset loc_40126C
.data:00000000004043E0 _data ends
第一个函数:loc_401283 loc_401283:
# rdi = rdi + rcx
add rdi, rcx
# rcx = rcx - rdi = rcx - (原 rdi + rcx) = - 原 rdi
sub rcx, rdi
# 取反 rcx
#再结合前面的 rcx = - 原 rdi , 取反后就变成 rcx = 原 rdi
neg rcx
# rcx = rcx +1
# 结合前面得到 rcx = 原 rdi + 1
inc rcx
# 跳回去
jmp short loc_40125D
sub_401240 endp
这里可以下断点跟踪一下 rdi 表示的是什么,结合这个函数传入的参数,不难推断出 rdi = index 就是当前下标 这里就是将 rcx = 原 rdi + 1 = index + 1
第二个函数:loc_401247 .text:0000000000401247 loc_401247:
# r8 = 0
.text:0000000000401247 xor r8, r8
# 跳回去
.text:000000000040124A jmp short loc_40125D
第三个函数:loc_401255 .text:0000000000401255
.text:0000000000401255 loc_401255:
# rdx = r8 r8 = 原 rdx + r8
.text:0000000000401255 xadd r8, rdx
# 看 rcx 是否为 0 ,不为 0 则循环, 每次循环 rcx = rcx - 1
# 结合前面的 rcx = index ,这里就是以 index 为次数循环进行 xadd 操作
.text:0000000000401259 loop loc_401255
# 跳回去
.text:000000000040125B jmp short $+2
第四个函数:loc_40126C .text:000000000040126C loc_40126C:
# 交换 rax 和 r8 的值
# 后面没有再用到 r8,而 rax 是作为返回值返回
# 所以可以看作是 rax = r8
.text:000000000040126C xchg rax, r8
# 返回
.text:000000000040126E retn
结合这前面几个函数的分析,可以推断出这个函数的伪代码: int sub_401240(int index){
int rdx = 1;
int r8 = 0;
for(int i = 0;i < index + 1;i++){
int temp = rdx
rdx = r8
r8 = temp + r8
}
return r8;
}
尝试还原至此,所有的算法都已经开朗,总结一下: key = byte_404060[index];
flag |= (key ^ sub_4012D8((unsigned int)buf, index++));
int sub_4012D8(char buf,int index){
int ret = sub_401291(buf);
return ret ^ sub_401240(index);
}
int sub_401291(char buf){
return unk_404288[buf];
}
int sub_401240(int index){
int rdx = 1;
int r8 = 0;
for(int i = 0;i < index + 1;i++){
int temp = rdx
rdx = r8
r8 = temp + r8
}
return r8;
}
有了算法就可以逆运算尝试还原了 已知 flag == 0 则 key ^ sub_4012D8((unsigned int)buf, index++) == 0 任何数异或本身才为 0,得到:key == sub_4012D8((unsigned int)buf, index++) key = byte_404060[index] 可以直接从数组里取,是已知的 因此 sub_4012D8((unsigned int)buf, index++) == key 也已知了
sub_4012D8((unsigned int)buf, index++) 等价于 ret ^ sub_401240(index) sub_401240 算法是已知的,所以可以求出 ret ret = sub_4012D8((unsigned int)buf, index++) ^ sub_401240(index)
ret 又等于 sub_401291(buf) ,sub_401291算法是已知的,所以可以求出 buf
用 python 编写以下代码: byte_404060 = [0x7b, 0xed, 0x51, 0x57, 0xfd, 0x11, 0x5e, 0x41, 0x6e, 0xab, 0xa2, 0x0c, 0xf0, 0x2a, 0x29, 0x97, 0xd9, 0x67, 0x2a, 0x24, 0x9d, 0x64, 0xbf, 0x74, 0x42, 0x7d, 0x80, 0x8b, 0xea, 0x63, 0x25, 0x4b, 0x0e, 0xab, 0x85, 0x2c, 0x32, 0x67, 0x5a, 0x87, 0x2f, 0xa4, 0x67, 0x25, 0x8d, 0x0c, 0xb5, 0xa4, 0xd9, 0xee, 0xce, 0xbe, 0xa7, 0xb0, 0xf9, 0x19, 0xf1, 0x2d, 0x83, 0x72, 0xf1, 0x1b, 0xb1, 0xf7, 0x01, 0x9a, 0xfa, 0xef, 0xde, 0xc4, 0x9f, 0x98, 0x7d, 0xce, 0x3a, 0x91, 0xf9, 0x84, 0x85, 0xfc, 0x8e, 0x18, 0xb0, 0x4a, 0x75, 0x71, 0x6c, 0x47, 0x81, 0x34, 0xd9, 0xf6, 0x4c, 0x47, 0x8f, 0xdf, 0x1e, 0x37, 0xfa, 0x8f, 0x29, 0x73, 0x0f, 0x9e, 0xbe, 0x0c, 0x4a, 0xaa, 0xd1, 0xfb, 0x09, 0x07, 0x47, 0x22, 0x57, 0x1a, 0xbd, 0x90, 0xbc, 0xe2, 0xcd, 0x33, 0xba, 0xc8, 0x37, 0xfb, 0xa7, 0x7f, 0x0e, 0xec, 0xc7, 0xdc, 0x41, 0x98, 0xf1, 0x49, 0xd5, 0x54, 0xb6, 0x5f, 0x20, 0xfb, 0x59, 0xb1, 0x32, 0xe3, 0xc9, 0xfe, 0x69, 0x30, 0x71, 0xf9, 0xb0, 0xaf, 0xc6, 0x4c, 0x05, 0x61, 0x40, 0x24, 0x41, 0x20, 0xf7, 0x41, 0xde, 0xf5, 0x2b, 0x18, 0x83, 0x02, 0x89, 0x40, 0x9b, 0x04, 0x4b, 0x5d, 0x2e, 0x58, 0x91, 0xca, 0x35, 0x1a, 0x76, 0x20, 0x75, 0xa7, 0xce, 0x91, 0xfa, 0x34, 0x6d, 0x71, 0x79, 0xcd, 0x40, 0x1f, 0xce, 0x46, 0x75, 0xca, 0x76, 0x4f, 0x95, 0xe1, 0x36, 0x1d, 0x9a, 0x17, 0xff, 0x84, 0x17, 0x15, 0x5e, 0x6d, 0x89, 0x6c, 0x33, 0xa8, 0xde, 0x08, 0x66, 0x92, 0xe7, 0x27, 0x1a, 0x95, 0xeb, 0x48, 0xb7, 0xf6, 0xf1, 0xf1, 0x15, 0x37, 0x71, 0x02, 0x70, 0x27, 0x8d, 0x1c, 0x4d, 0xb5, 0x20, 0x9b, 0x1e, 0x0a, 0x7e, 0xcf, 0x18, 0xfb, 0xf2, 0x9e, 0x65, 0xa1, 0x6d, 0xc3, 0x81, 0xaa, 0x6c, 0x77, 0xae, 0xfd, 0xbd, 0x2b, 0xfd, 0xe9, 0xcd, 0x8c, 0xc1, 0x90, 0xb4, 0x68, 0xe9, 0x3f, 0xd2, 0xaf, 0x52, 0x45, 0xce, 0xe9, 0x01, 0xba, 0x21, 0xc5, 0x4e, 0x7d, 0xad, 0xd4, 0x2d, 0xb9, 0x9e, 0x81, 0xbd, 0xc3, 0x92, 0xad, 0x3b, 0x28, 0x05, 0x5b, 0xe5, 0x41, 0xfe, 0x50, 0x85, 0x04, 0xe7, 0xb4, 0x78, 0x83, 0xc3, 0x4c, 0x9a, 0x3d, 0xde, 0xf8, 0xbb, 0x50, 0xce, 0xbd, 0x19, 0x73, 0x5a, 0xcb, 0x52, 0x9b, 0x4e, 0xf3, 0x31, 0xf3, 0x9d, 0xbd, 0x9e, 0x5d, 0x6d, 0x38, 0xb2, 0xea, 0x74, 0xdb, 0xf6, 0x3e, 0x9b, 0xa9, 0xe9, 0x99, 0x81, 0x49, 0x9a, 0xe2, 0x89, 0x17, 0x89, 0x1a, 0x4d, 0x37, 0xde, 0xa4, 0xfd, 0x18, 0xfc, 0x93, 0x2e, 0x61, 0xc9, 0x1e, 0x6e, 0xdd, 0x3d, 0xd3, 0x11, 0x6f, 0x03, 0x0c, 0x76, 0xb4, 0x41, 0x14, 0xfe, 0xb1, 0xe6, 0x07, 0x9d, 0x4c, 0xf9, 0xf3, 0x51, 0x68, 0xe9, 0xca, 0xf5, 0x59, 0x60, 0xdb, 0xa1, 0x6b, 0xab, 0x2a, 0xd8, 0x61, 0xd1, 0x53, 0x1b, 0x81, 0x3a, 0x6d, 0xa2, 0x74, 0xe7, 0xd5, 0xba, 0x4c, 0xa9, 0x64, 0x25, 0x4e, 0xbd, 0xab, 0x31, 0xfb, 0x95, 0xd2, 0x4e, 0x09, 0xaf, 0x6b, 0xf1, 0x41, 0x38, 0xfd, 0x19, 0x1f, 0x2e, 0x99, 0xcc, 0xbc, 0x3a, 0xbe, 0x55, 0xe1, 0xbe, 0xc4, 0x83, 0x4c, 0x45, 0x7b, 0xd5, 0xc4, 0xe2, 0x92, 0xb7, 0xb5, 0x11, 0xc4, 0x27, 0x98, 0xbe, 0x69, 0xcd, 0x0c, 0x41, 0x26, 0x22, 0xa9, 0x86, 0xbf, 0xeb, 0x1c, 0xcd, 0x65, 0xda, 0x37, 0x0f, 0x80, 0xe7, 0xe2, 0x1e, 0xeb, 0x39, 0x8f, 0xfb, 0x92, 0x4c, 0x76, 0x3d, 0x4a, 0x0f, 0x39, 0x98, 0x4d, 0xeb, 0x43, 0x65, 0xd5, 0xa0, 0x80, 0x03, 0x1a, 0x66, 0x8b, 0x80, 0xbc, 0x73, 0x06, 0xa4, 0xbb, 0xa2, 0x79, 0x68, 0x0e, 0x10, 0x9a, 0xbd, 0x01, 0xd3, 0xd0, 0xf2, 0xf4, 0x04, 0x04, 0x17, 0x1c, 0xe8, 0x3d, 0x0e, 0x56, 0x5e, 0xa3, 0x5d, 0x1b, 0x26, 0x7b, 0x5a, 0xb7, 0x3b, 0x59, 0x60, 0x1b, 0x1d, 0x2f, 0xe9, 0x75, 0x14, 0x24, 0x41, 0x8b, 0x7e, 0xe1, 0x3d ]
unk_404288 = [36, 221, 193, 137, 10, 207, 131, 226, 198, 253, 127, 70, 68, 37, 157, 46, 39, 32, 184, 225, 53, 57, 51, 177, 144, 200, 48, 169, 152, 117, 115, 234, 248, 54, 64, 35, 164, 41, 105, 93, 21, 145, 196, 11, 228, 172, 55, 149, 60, 99, 82, 133, 224, 30, 243, 255, 130, 132, 181, 187, 151, 146, 150, 18, 142, 74, 214, 73, 122, 155, 139, 52, 12, 143, 213, 239, 44, 90, 58, 202, 197, 110, 160, 103, 13, 140, 31, 245, 7, 29, 91, 79, 159, 171, 5, 166, 129, 83, 63, 251, 246, 236, 15, 78, 66, 156, 8, 107, 186, 242, 75, 95, 25, 20, 84, 194, 76, 28, 92, 113, 254, 162, 161, 27, 3, 216, 100, 17, 38, 109, 14, 24, 203, 112, 235, 81, 98, 104, 45, 67, 89, 1, 0, 119, 88, 170, 189, 230, 49, 238, 135, 223, 26, 47, 85, 182, 240, 106, 80, 50, 101, 6, 180, 118, 217, 34, 108, 190, 232, 165, 154, 111, 72, 87, 201, 4, 249, 205, 212, 219, 33, 233, 43, 174, 222, 124, 123, 69, 244, 192, 9, 121, 147, 250, 229, 77, 163, 206, 191, 179, 125, 86, 59, 148, 176, 134, 97, 158, 227, 252, 208, 138, 42, 102, 128, 183, 218, 247, 22, 199, 56, 167, 195, 211, 209, 94, 71, 141, 168, 16, 65, 220, 96, 136, 120, 61, 237, 188, 62, 241, 173, 175, 114, 23, 2, 126, 215, 185, 153, 40, 116, 204, 178, 231, 210, 19]
def sub_401291(buf):
return unk_404288[buf]
def sub_401240(index):
rdx = 1
r8 = 0
for num in range(0,index+1):
temp = rdx
rdx = r8
r8 = temp + r8
return r8;
str = ""
# 和 main 函数一样,遍历下标
for index in range(0,0x224):
# 先求出 key
key = byte_404060[index]
# 再求出 ret
r8 = sub_401240(index)
ret = (r8 % 256) ^ (key % 256)
# 遍历 unk_404288 找到值为 ret 的下标,其下标就是 buf
for index,element in enumerate(unk_404288):
if(element == ret):
str = str + chr(index)
print(str)
最后输出结果: Dear participant,
Congrats on getting this far, It's really satisfying to see people getting good technical skills.
This challenge was easy, wasn't it? but you still managed to learn one new thing or two, this is typically my goal from every challenge I implement for CTF contests, there is no point in implementing a crackme in Rust and adding packers like Themida or VMProtect, it makes the challenge hard, but not necessarily of good quality.
Oh and I forgot, here is your flag: shellmates{x86_has_WA4AY_Too_M4nY_IN$TRUC710N$}
Best,
Redouane
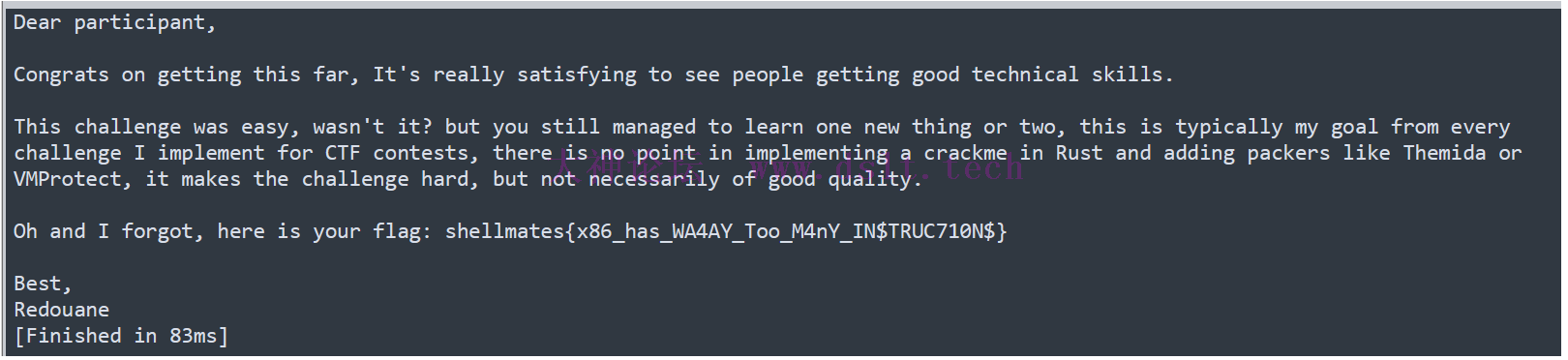
总结题目的核心在于 jmp [rax],即把要执行的函数存在一个数组里,然后按顺序依次执行,这导致了 IDA Pro 无法正确生成伪代码,需要动态分析 CTF 的源代码附下方链接中。
下方隐藏内容为本帖所有文件或源码下载链接:
游客你好,如果您要查看本帖隐藏链接需要登录才能查看,
请先登录
|


 发表于 2023-12-23 23:33
发表于 2023-12-23 23:33





 评分
评分 顶
顶 踩
踩 扫码赞助
扫码赞助