本帖最后由 dhdajun 于 2024-01-17 22:16 编辑
声明本文章中所有内容仅供学习交流使用,不用于其他任何目的,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关! 本文章未经许可禁止转载,禁止任何修改后二次传播,擅自使用本文讲解的技术而导致的任何意外,作者均不负责,若有侵权,请联系作者立即删除! 孪生神经网络简介简单来说,孪生神经网络(Siamese network)就是“连体的神经网络”,神经网络的“连体”是通过共享权值来实现的,如下图所示 : 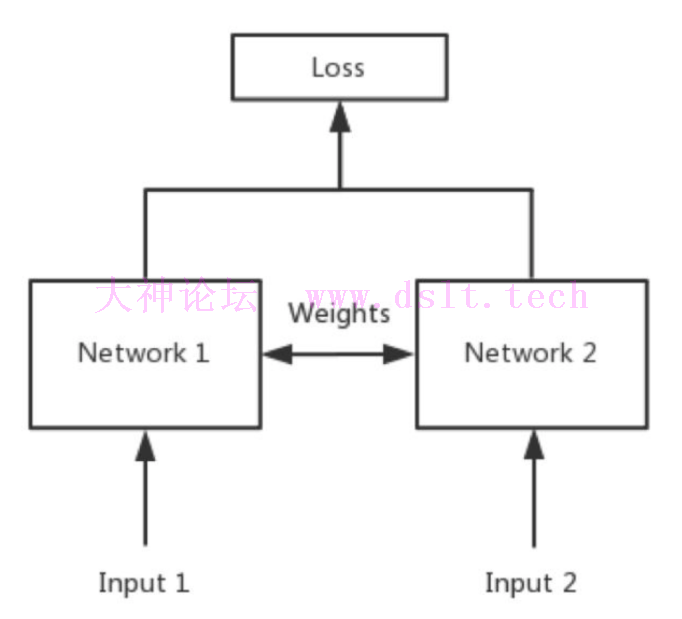
孪生神经网络是一种特殊的神经网络结构,由两个或多个相同的子网络组成,这些子网络共享相同的权重和参数。其设计灵感来源于孪生兄弟或姐妹之间的相似性。孪生神经网络主要用于解决比较和相似性度量的问题。它可以将两个输入进行比较,并输出一个度量值,表示它们之间的相似性或差异程度。通俗来说,就是不同的人写了同一个汉字,将其中随机的二者拿出来进行对比,判断他们写的是不是同一个汉字,原理就是通过一个神经网络进行特征提取再进行比较, 通过 Loss 的计算,评价两个输入的相似度 。大家可以简单了解一下它的大致过程: 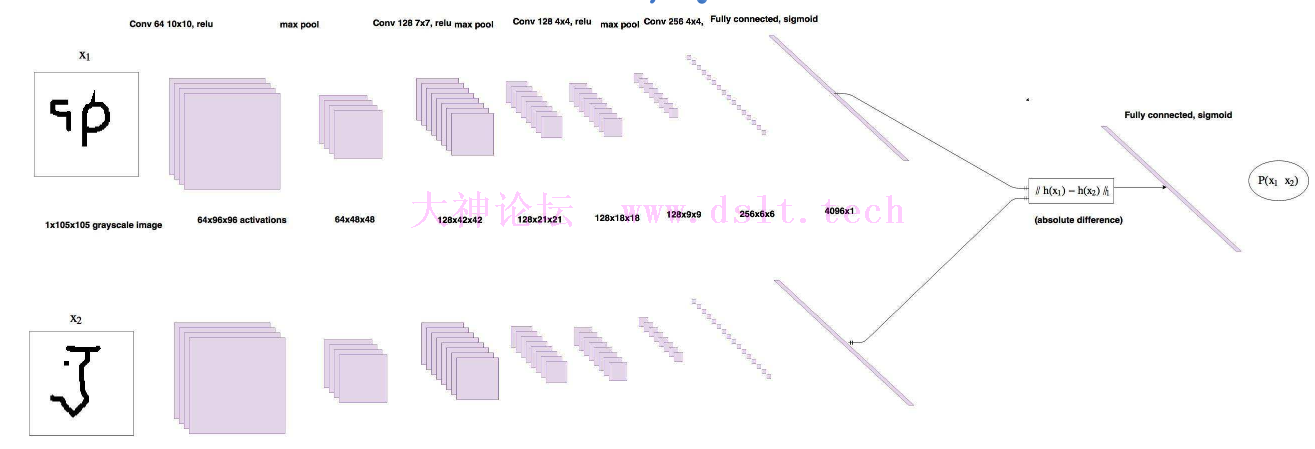
孪生网络中的 LOSS 计算对于孪生神经网络而言,其具有两个输入。 当两个输入指向同一个类型的图片时,此时标签为 1。 当两个输入指向不同类型的图片时,此时标签为 0。 然后将网络的输出结果和真实标签进行交叉熵运算,就可以作为最终的 loss 了。 比如,当我们输入下面俩个的时候,我们希望网络给我们输出 1: 
当我们输入以下俩个的时候,我们希望网络给我们输出 0: 
当输出 0 或者 1 的时候,我们将会与预测结果求交叉熵,进而输出相似度,这便是孪生神经网络的奇妙之处。 YOLO目标检测YOLO 是目标检测模型。 目标检测是计算机视觉中比较简单的任务,用来在一张图篇中找到某些特定的物体。附上一张图,让大家直观的感受一下: 
YOLO 检测速度非常快。因为检测问题是回归问题,所以不需要复杂的管道。它比 “R-CNN” 快 1000 倍,比 “Fast R-CNN” 快 100 倍。 YOLO 能够处理实时视频,延迟非常小,连 25 毫秒都不到。精度也是以前实时系统的 2 倍多。更为重要的是 YOLO 遵循“端到端深度学习”的实践。 CNN 图像分类在计算机视觉中,我们有一个卷积神经网络,它非常适用于计算机视觉任务,例如图像分类、对象检测、图像分割等等。卷积神经网络 (CNN)是一种用于处理图像的神经网络,这种类型的神经网络从图像中获取输入并从图像中提取特征,并提供可学习的参数以有效地进行分类、检测和更多任务。 我们使用称为“过滤器”的东西从图像中提取特征,我们使用不同的过滤器从图像中提取不同的特征。让我们举个例子,你正在构建一个分类模型来检测图像是猫还是非猫。因此,我们有不同的过滤器用于从图像中提取不同的特征,从而识别他是什么。所以大家可以把他理解成 OCR,输入一张图像,返回图像类别。 好了,大家对这 3 个东西相信也有一定的了解了,怎么使用,那我们就用实例来给大家讲解一下他们怎么使用。 点选验证码处理思路我们附上几张,我们常见点选类验证码: 
背景图的话千篇一律,没有什么区分,相比而言,对于点选问题,不同站点的验证码是不同的,基本有以下几类,我们通过不同的类别,来浅谈以下不同类型的点选我们应该如何处理。 类型一:yolo+CNN① 有些网站的题目是在接口中返回,例如 wordList': ['并', '细', '什'] 这样的话,就很简单,我们把他从数组中取出来,就可以得到问题的答案。现在我们已经拿到了问题,就需要在图片中找到对应文字的坐标。我们这里采用 yolo+CNN(ddddocr),利用 labelimg 标注数据集生成 yolo 格式,labelimg 的安装: pip install labelimg
新建 2 个文件夹:一个是存放图片的目录,另一个存放标签 class 的目录。 cmd 继续输入 labelimg 即可进入标注首页,按照下图片进行设置: 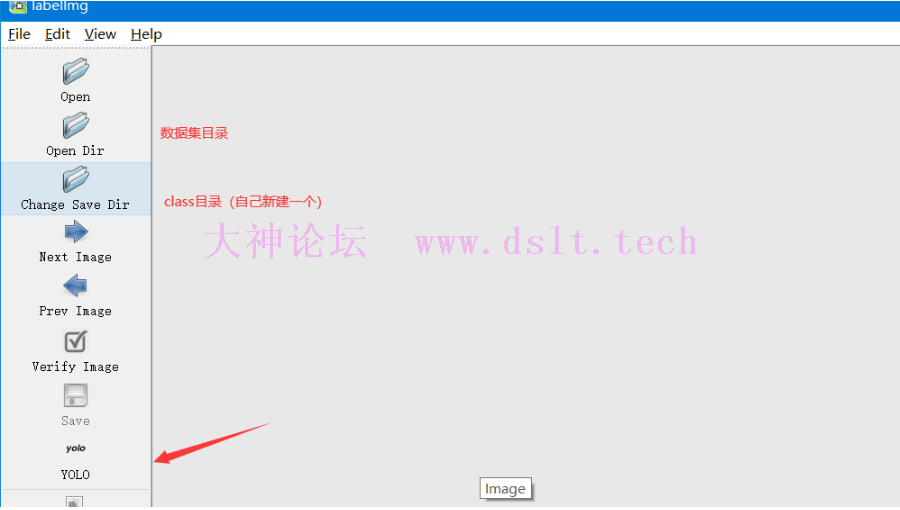
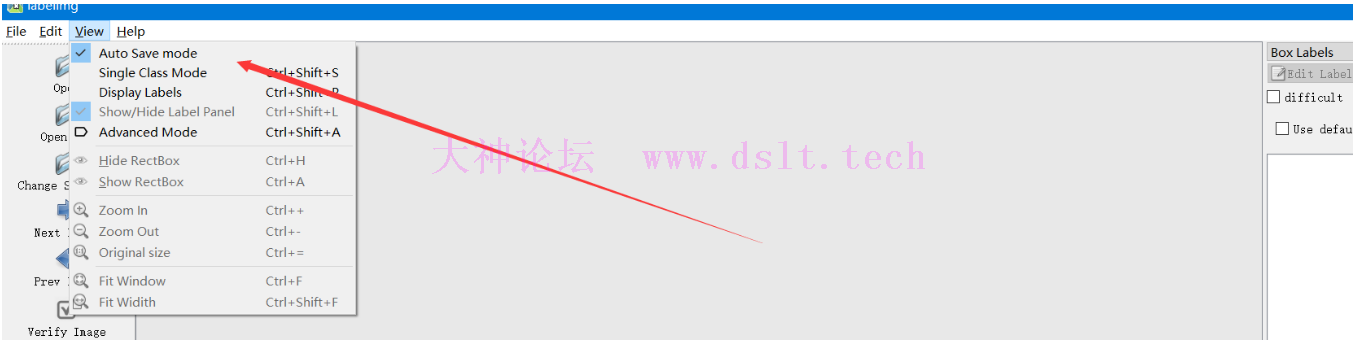
标注的类名用英文,或者数字,这里我们只需要做文字检测,所以类名都写成 1 就可以了。标注完成会在你新建的目录下生成 class.txt 文件。 yolov5 下载地址: https://codeload.github.com/ultralytics/yolov5/zip/refs/heads/master
下载好以后,导入 pycharm,打开 train.py,找到 data 这个位置,这是训练集的配置文件,上面显示 data/coco128.yaml: 
按照指定要求放我们的数据集: 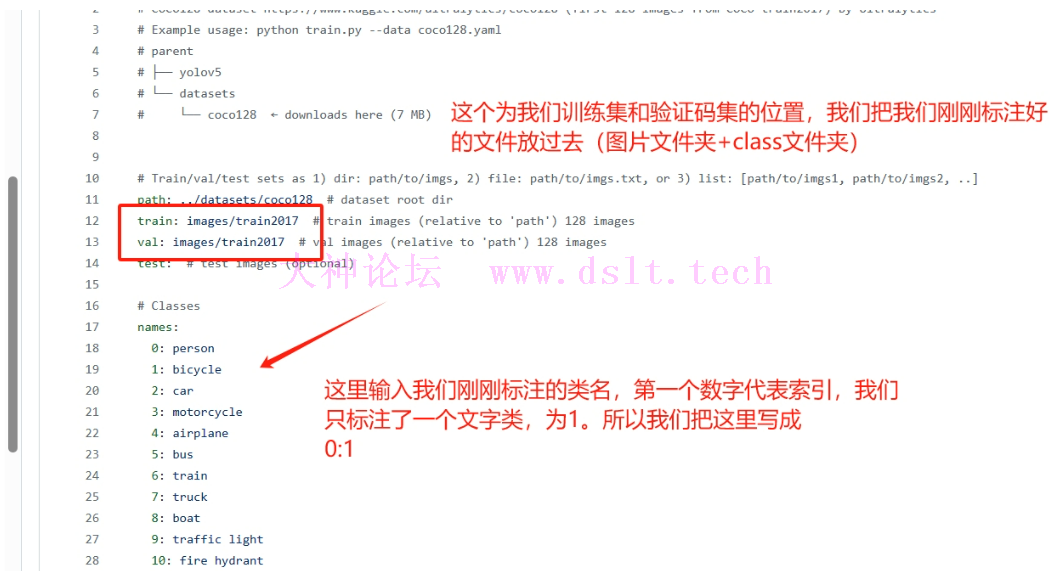
整体的路径框架就是下图这个样子,保存 yaml 配置文件与数据集存放位置一致就可以了: 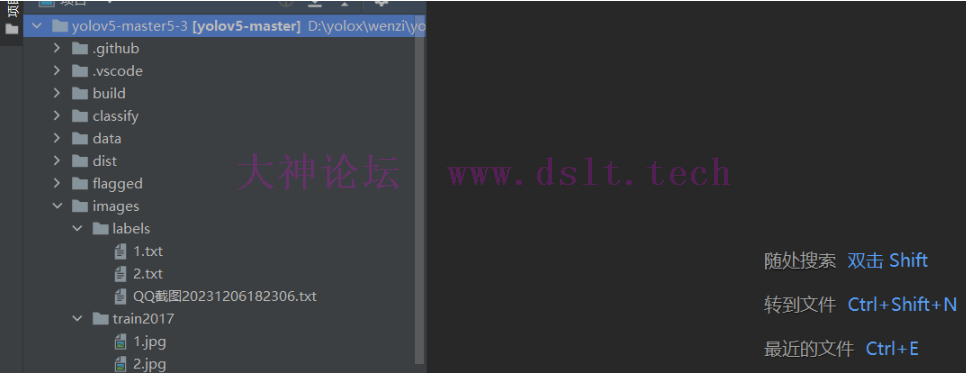
走到这一步,我们的数据准备工作就完成了,接下来我们把我们 yolo 总文件夹打包,然后上传到 Auto 算力云平台(地址:https://www.autodl.com)去租用 gpu 去训练,(也自己本地可以安装 conda,安装 pytorch 去配置环境去训练,如何配置环境网上有教程,但是对电脑性能有一定要求,且很多框架要求必须是 N 卡),这里笔者为了所有人都可以训练,选择算力云平台去训练,这也是笔者平时为了节省效率采用的方式。 模型训练进入以后,我们选择 T 卡即可,环境配置如下: 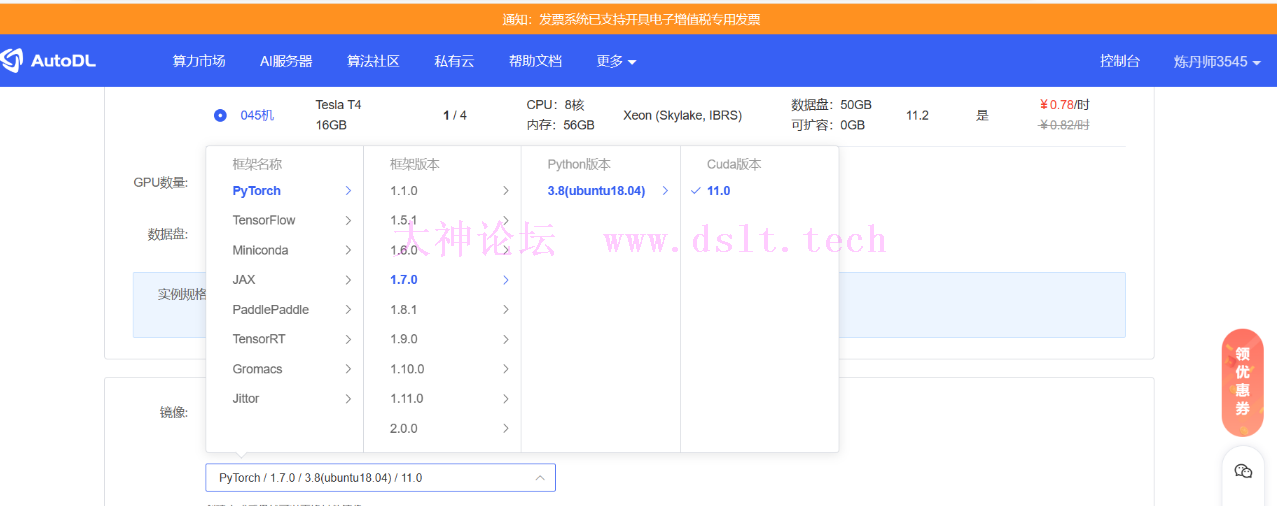
选择 1.x 的版本都可以,推荐 1.7.0,创建以后我们进入即可,进入以后选择终端,输入 source /etc/network_turbo 回车进行镜像加速,然后输入指令,pip install -r requirements.txt 进行相关库的安装,如果遇上安装不上的,手动安装即可,和 win 的操作基本一致,我们所需的库安装完以后,敲入 python3 train.py 即可开始训练,训练完成会导出 pt 模型。 我们自己编写代码进行预测,这里咱已经贴心的写成接口形式了: # 实例化 flask
app = Flask(__name__)
docr = solve()
# 设置路由和处理函数(异步处理)
@app.route("/ocr", methods=["POST"])
def shibie():
data = request.get_data().decode("utf-8")
data = json.loads(data)
# BASE64 图片
beijing_data = data["beijing"]
beijing_bytes = base64.b64decode(beijing_data)
beijing_image = Image.open(BytesIO(beijing_bytes))
results = model(beijing_image)
boxes = results.xyxy[0][:, :4].tolist()
output = []
for box in boxes:
x1, y1, x2, y2 = box
output.append([int(x1), int(y1), int(x2), int(y2)])
return output
if __name__ == "__main__":
# 导入 yolov5 模型定义和权重
# 加载 yolo 模型
luansheng = Siamese()
model = torch.hub.load("./", "custom", path="best2.pt", source="local")
model.conf = 0.5
app.run(host="0.0.0.0", threaded=True, processes=1)
上面代码会给你一组数组,是图片上每个检测对象的左上坐标和左下坐标,你可以用它来求中心坐标~ 当然,网上很多人会教你转成 onnx 去运行,下面教大家如何转成 onnx 模型,并且推理: pt 模型转 onnx 模型代码 1(网传) from ultralytics import YOLO
model = YOLO(r"suixin.pt")
model.export(format="onnx",imgsz=320,simplify=True)
pt 模型转 onnx 模型代码 2(本人在用的方式) yolo 官方其他给我们已经准备好了转换的文件,我们进入我们下载的 yolo5 文件夹中,找到 export.pt: 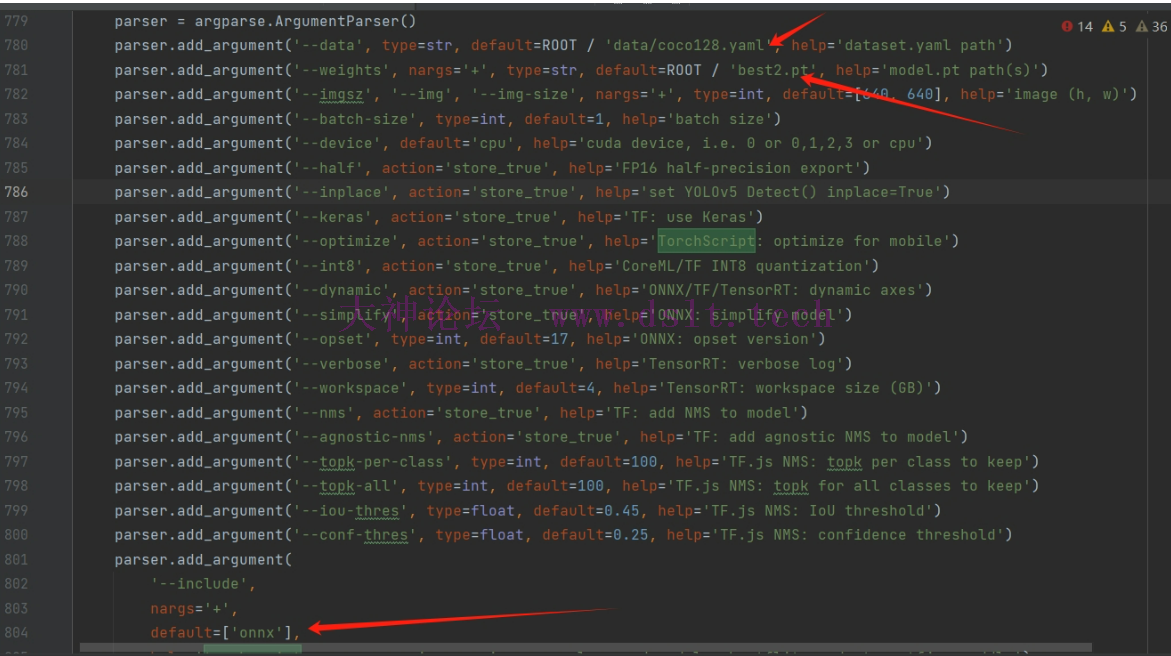
找到这三个位置,第一个位置一定不陌生,就是我们训练的时候已经配置好的那个文件,第二个就是我们训练结束以后的 pt 模型,第三个是选择导出的类型,我们这里输入 onnx 模型就行。 onnx 模型预测代码 1(网传,自测,大部分人跑不起来,可能第一步用别人的代码转就没转好): from ultralytics import YOLO
model = YOLO(r"best2.onnx")
res = model.predict(source=r"bg1.jpg",show=False,save=True,imgsz=300)
onnx 模型预测代码 2(笔者本人在用的方式)这里如果要接口调用,自己仿照上面的格式去修改即可: import os
import cv2
import time
import numpy as np
import onnxruntime
# coco80 类别
CLASSES = ['1']
class YOLOV5:
def __init__(self,onnxpath):
self.onnx_session = onnxruntime.InferenceSession(onnxpath)
self.input_name = self.get_input_name()
self.output_name = self.get_output_name()
#-------------------------------------------------------
# 获取输入输出的名字
#-------------------------------------------------------
def get_input_name(self):
input_name = []
for node in self.onnx_session.get_inputs():
input_name.append(node.name)
return input_name
def get_output_name(self):
output_name = []
for node in self.onnx_session.get_outputs():
output_name.append(node.name)
return output_name
#-------------------------------------------------------
# 输入图像
#-------------------------------------------------------
def get_input_feed(self,img_tensor):
input_feed = {}
for name in self.input_name:
input_feed[name] = img_tensor
return input_feed
#-------------------------------------------------------
# 1.cv2 读取图像并 resize
# 2.图像转 BGR2RGB 和 HWC2CHW
# 3.图像归一化
# 4.图像增加维度
# 5.onnx_session 推理
#-------------------------------------------------------
def inference(self,img_path):
img = cv2.imread(img_path)
or_img = cv2.resize(img,(640,640))
img = or_img[:,:,::-1].transpose(2,0,1) # BGR2RGB 和 HWC2CHW
img = img.astype(dtype=np.float32)
img /= 255.0
img = np.expand_dims(img,axis=0)
input_feed = self.get_input_feed(img)
pred = self.onnx_session.run(None,input_feed)[0]
return pred,or_img
# dets: array [x,6] 6 个值分别为 x1,y1,x2,y2,score,class
# thresh: 阈值
def nms(dets, thresh):
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
#-------------------------------------------------------
# 计算框的面积
# 置信度从大到小排序
#-------------------------------------------------------
areas = (y2 - y1 + 1) * (x2 - x1 + 1)
scores = dets[:, 4]
keep = []
index = scores.argsort()[::-1]
while index.size > 0:
i = index[0]
keep.append(i)
#-------------------------------------------------------
# 计算相交面积
# 1.相交
# 2.不相交
#-------------------------------------------------------
x11 = np.maximum(x1[i], x1[index[1:]])
y11 = np.maximum(y1[i], y1[index[1:]])
x22 = np.minimum(x2[i], x2[index[1:]])
y22 = np.minimum(y2[i], y2[index[1:]])
w = np.maximum(0, x22 - x11 + 1)
h = np.maximum(0, y22 - y11 + 1)
overlaps = w * h
#-------------------------------------------------------
# 计算该框与其它框的 IOU,去除掉重复的框,即 IOU 值大的框
# IOU 小于 thresh 的框保留下来
#-------------------------------------------------------
ious = overlaps / (areas[i] + areas[index[1:]] - overlaps)
idx = np.where(ious <= thresh)[0]
index = index[idx + 1]
return keep
def xywh2xyxy(x):
# [x, y, w, h] to [x1, y1, x2, y2]
y = np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2
y[:, 1] = x[:, 1] - x[:, 3] / 2
y[:, 2] = x[:, 0] + x[:, 2] / 2
y[:, 3] = x[:, 1] + x[:, 3] / 2
return y
# 过滤掉无用的框
def filter_box(org_box,conf_thres,iou_thres):
#-------------------------------------------------------
# 删除为 1 的维度
# 删除置信度小于 conf_thres 的 BOX
#-------------------------------------------------------
org_box = np.squeeze(org_box)
conf = org_box[..., 4] > conf_thres
box = org_box[conf == True]
#-------------------------------------------------------
# 通过 argmax 获取置信度最大的类别
#-------------------------------------------------------
cls_cinf = box[..., 5:]
cls = []
for i in range(len(cls_cinf)):
cls.append(int(np.argmax(cls_cinf[i])))
all_cls = list(set(cls))
#-------------------------------------------------------
# 分别对每个类别进行过滤
# 1.将第 6 列元素替换为类别下标
# 2.xywh2xyxy 坐标转换
# 3.经过非极大抑制后输出的 BOX 下标
# 4.利用下标取出非极大抑制后的 BOX
#-------------------------------------------------------
output = []
for i in range(len(all_cls)):
curr_cls = all_cls[i]
curr_cls_box = []
curr_out_box = []
for j in range(len(cls)):
if cls[j] == curr_cls:
box[j][5] = curr_cls
curr_cls_box.append(box[j][:6])
curr_cls_box = np.array(curr_cls_box)
# curr_cls_box_old = np.copy(curr_cls_box)
curr_cls_box = xywh2xyxy(curr_cls_box)
curr_out_box = nms(curr_cls_box,iou_thres)
for k in curr_out_box:
output.append(curr_cls_box[k])
output = np.array(output)
return output
def draw(image,box_data):
#-------------------------------------------------------
# 取整,方便画框
#-------------------------------------------------------
boxes = box_data[...,:4].astype(np.int32)
scores = box_data[...,4]
classes = box_data[...,5].astype(np.int32)
for box, score, cl in zip(boxes, scores, classes):
top, left, right, bottom = box
print('class: {}, score: {}'.format(CLASSES[cl], score))
print('box coordinate left,top,right,down: [{}, {}, {}, {}]'.format(top, left, right, bottom))
cv2.rectangle(image, (top, left), (right, bottom), (255, 0, 0), 2)
cv2.putText(image, '{0} {1:.2f}'.format(CLASSES[cl], score),
(top, left ),
cv2.FONT_HERSHEY_SIMPLEX,
0.6, (0, 0, 255), 2)
if __name__=="__main__":
onnx_path = 'best2.onnx'
model = YOLOV5(onnx_path)
output, or_img = model.inference('bg1.jpg')
outbox = filter_box(output,0.5,0.5)
draw(or_img,outbox)
cv2.imwrite('res.jpg',or_img)
class: 1, score: 0.9501548409461975
box coordinate left,top,right,down: [439, 128, 549, 277]
class: 1, score: 0.9403117895126343
box coordinate left,top,right,down: [253, 288, 359, 434]
class: 1, score: 0.9271262884140015
box coordinate left,top,right,down: [103, 67, 215, 224]
上面代码运行输出结果:没错,就是我们需要的坐标,本地调试没问题,可以仿照我上面的写法,写成接口的形式。 类型识别上面我们已经拿到了图片背景中的坐标,我们只需按照上面的坐标将图片进行切割下来即可。那么我们应该如何识别他到底是什么文字,或者这个图标呢? 这里的话我推荐 ddddocr 或者飞浆,也可以自己写一个网络去识别,这里我们选择 ddddocr 也是效率最高的去做就行。地址: GitHub - sml2h3/dddd_trainer: ddddocr 训练工具,和 yolo 训练教程一样,也是直接打包 zip,上传到算力云,控制台进入项目主目录。 第一步,创建项目: python app.py create {project_name}
or
python app.py create {project_name} --single
如果想要创建一个 CNN 的项目,则可以加上 --single 参数,CNN 项目识别比如图片类是什么分类的情况,比如图片上只有一个字,识别这张图是什么字(图上有多个字的不要用 CNN 模式),又比如分辨图片里是狮子还是兔子用 CNN 模式比较合适,大多数 OCR 需求请不要使用 --single。一句话总结:能看出文字内容的就不用 single,图像类别请用 single,例如腾讯六宫格图片,图标等。 例子: python app.py create tubiao --single(这里演示的是图标的训练,当然就用 single 了,如果是文字点选,那就没必要加) 第二步,准备数据: 图片均在同一个文件夹中,且命名为类似,其中 D:\img\ 文件夹为标注好的图片所在目录,可以为任意目录地址,这里是自己的图片目录,命名格式如下图。这里演示的是图标数据集,类名的话由自己去起: 
第三步,缓存数据: 这里以刚刚创建的 tubiao 项目和图片路径做演示,具体用的时候自己去替换自己的项目名就行了: python app.py cache tubiao D:\img\
第四步,开始训练: python app.py train tubiao
训练完成,将会导出 onnx 模型和 json 文件,按照官网的案例去导入模型去识别就行,这里附上使用案例: import ddddocr
ocr = ddddocr.DdddOcr(det=False, ocr=False, import_onnx_path="图标模型.onnx", charsets_path="charsets.json")
with open('888e28774f815b01e871d474e5c84ff2.jpg', 'rb') as f:
image_bytes = f.read()
res = ocr.classification(image_bytes)
print(res)
####1##### 输出结果1 也就是我们标注的1
好了,至此我们的分类识别就完毕了,我们只需将目标检测返回的坐标在原图切割以后,传入这里去识别即可。这里附上完整流程代码: import json
import torch
import base64
import ddddocr
from PIL import Image
from io import BytesIO
from flask import Flask, request, jsonify
################################DDDDDDDDDDDDDDDD###################################################
class Ddddocr:
def __init__(self):
self.ocr = ddddocr.DdddOcr(
det=False,
ocr=False,
import_onnx_path="2023-8-25/A1_0.984375_202_356000_2023-08-25-16-04-37.onnx",
charsets_path="2023-8-25/charsets.json",
)
self.xy_ocr = ddddocr.DdddOcr(det=False, show_ad=False)
def result_ocr(self, content, xy_list):
img = Image.open(BytesIO(content))
words = []
for row in xy_list:
x1, y1, x2, y2 = row
crop = img.crop(row)
img_byte = BytesIO()
crop.save(img_byte, "png")
word = self.ocr.classification(img_byte.getvalue())
words.append(word)
return dict(
zip(words, xy_list))
def resultocr(self, con, xylist):
click_identify_result = self.result_ocr(
con, xylist
)
img_xy = {}
for key, xy in click_identify_result.items(): # 将字典中的结果和位置信息遍历
img_xy[key] = (
int((xy[0] + xy[2]) / 2),
int((xy[1] + xy[3]) / 2),
)
return img_xy
######################################flask#################################################
# 实例化 flask
app = Flask(__name__)
docr = Ddddocr()
# 设置路由和处理函数(异步处理)
@app.route("/ocr", methods=["POST"])
def shibie():
data = request.get_data().decode("utf-8")
data = json.loads(data)
beijing_data = data["beijing"]
# 将字节流转换为 PIL 图像对象
beijing_bytes = base64.b64decode(beijing_data)
beijing_image = Image.open(BytesIO(beijing_bytes))
results = model(beijing_image)
boxes = results.xyxy[0][:, :4].tolist()
output = []
for box in boxes:
x1, y1, x2, y2 = box
output.append([int(x1), int(y1), int(x2), int(y2)])
bg_results = docr.resultocr(beijing_bytes, output)
response_data = {"data": bg_results}
return jsonify(response_data)
if __name__ == "__main__":
# 导入 yolov5 模型定义和权重
# 加载 yolo 模型
model = torch.hub.load("./", "custom", path="best.pt", source="local")
# 定义权重文件
model.conf = 0.5
app.run(host="0.0.0.0", threaded=True, processes=1)
这里附上接口测试代码(多线程): import time
import json
import base64
import requests
import threading
from PIL import Image
from io import BytesIO
url = "http://127.0.0.1:5000/ocr"
beijing_image = Image.open("8209bg.png")
beijing_bytes = BytesIO()
beijing_image.save(beijing_bytes, format="PNG")
beijing_data = base64.b64encode(beijing_bytes.getvalue()).decode("utf-8")
data = {
"beijing": beijing_data
}
def send_request(url, data):
response = requests.post(url, json=data)
print(f"Response: {response.json()}")
threads = []
for i in range(1):
thread = threading.Thread(target=send_request, args=(url, data))
threads.append(thread)
thread.start()
# 等待所有线程结束
for thread in threads:
thread.join()
#### Response: {'data': {'方': [175, 95], '沙': [101, 80], '理': [47, 18], '轻': [207, 26]}}
类型二:yolo + 孪生 Siamese孪生就不介绍了,文章开头已经很明确了,刚刚我们第一种方式用的是 yolo + 分类识别,那么如果我们现在遇到题目是图片的我们应该怎么处理?当然我们也可以用类型一去处理他,既然他不给我题目文字,那么我们就用 ddddocr 去识别这个题目,那么就变成和类型一相同的处境了,我们拿到了题目和底图,自然就可以去识别这种情况的点选了。 这里我们讲第二种办法,用孪生去识别,就是用题目和切割出来的图像去匹配,看看哪个相似度高,我们就认为他俩是匹配的。 这里我们进入 git,克隆项目到本地:https://github.com/bubbliiiing/Siamese-pytorch 训练自己相似性比较的模型,将数据集按照如下格式进行摆放。 - image_background
- character01
- 0709_01.png
- 0709_02.png
- ……
- character02
- character03
- ……
这里附一张我的标注图,方便大家理解: 
- 按上述格式放置数据集,放在根目录下的 dataset 文件夹下;
- 之后将 train.py 当中的 train_own_data 设置成 True;
- 运行 train.py 开始训练;
- 训练结束以后,会导出 pth 文件,按照文档进行相关操作即可。
算力云平台配置我们选择 PyTorch 1.7.0 Python 3.8(ubuntu18.04) 依旧是本地配置好以后,上传到服务器,安库,开训即可: 
训练好以后,我们进入 siamese.py 进行修改模型路径,这里主要注意 model_path 改为训练导出的模型,input_shape 为图片的大小: class Siamese(object):
_defaults = {
#-----------------------------------------------------#
# 使用自己训练好的模型进行预测一定要修改 model_path
# model_path 指向 logs 文件夹下的权值文件
#-----------------------------------------------------#
"model_path" : 'model_data/jyicon2.pth',
#-----------------------------------------------------#
# 输入图片的大小。
#-----------------------------------------------------#
"input_shape" : [60, 60],
#--------------------------------------------------------------------#
# 该变量用于控制是否使用 letterbox_image 对输入图像进行不失真的 resize
# 否则对图像进行 CenterCrop
#--------------------------------------------------------------------#
"letterbox_image" : False,
#-------------------------------#
# 是否使用 Cuda
# 没有 GPU 可以设置成 False
#-------------------------------#
"cuda" : False
}
修改以后,打开 predict.py 输入图片路径,即可进行相似度对比。这里预测的操作,大家还是以 git 为主,讲的会比较详细。仿照上面的思路,接口传入图片以后,与分割的图片一一进行相似度匹配,拿出来即可,这里附上一段相似度比较代码。首先,需要在 simapy 将这个函数替换,以便可以返回相似度为整数: def detect_image(self, image_1, image_2):
#---------------------------------------------------------#
# 在这里将图像转换成 RGB 图像,防止灰度图在预测时报错。
#---------------------------------------------------------#
image_1 = cvtColor(image_1)
image_2 = cvtColor(image_2)
#---------------------------------------------------#
# 对输入图像进行不失真的 resize
#---------------------------------------------------#
image_1 = letterbox_image(image_1, [self.input_shape[1], self.input_shape[0]], self.letterbox_image)
image_2 = letterbox_image(image_2, [self.input_shape[1], self.input_shape[0]], self.letterbox_image)
#---------------------------------------------------------#
# 归一化+添加上 batch_size 维度
#---------------------------------------------------------#
photo_1 = preprocess_input(np.array(image_1, np.float32))
photo_2 = preprocess_input(np.array(image_2, np.float32))
with torch.no_grad():
#---------------------------------------------------#
# 添加上 batch 维度,才可以放入网络中预测
#---------------------------------------------------#
photo_1 = torch.from_numpy(np.expand_dims(np.transpose(photo_1, (2, 0, 1)), 0)).type(torch.FloatTensor)
photo_2 = torch.from_numpy(np.expand_dims(np.transpose(photo_2, (2, 0, 1)), 0)).type(torch.FloatTensor)
if self.cuda:
photo_1 = photo_1.cuda()
photo_2 = photo_2.cuda()
#---------------------------------------------------#
# 获得预测结果,output 输出为概率
#---------------------------------------------------#
output = self.net([photo_1, photo_2])[0]
output = torch.nn.Sigmoid()(output)
# print(output)
# 将相似度值转换为整数类型
# similarity = round(output.item(), 2)
# similarity_integer = int(similarity * 100)
# 返回整数类型的相似度值
# return similarity_integer
return output
def case_demo(con, xy_list, q1data, q2data, q3data):
# 背景图
img = con
result = []
# 计算题目 1 的相似度
scores1 = []
for row in xy_list: # xylist 为 yolo 检测后的坐标
crop = img.crop(row)
img_byte = BytesIO()
crop.save(img_byte, "png")
img_data = Image.open(img_byte).resize((60, 60))
score = luansheng.detect_image(q1data, img_data)
scores1.append(score)
max_score_index1 = scores1.index(max(scores1))
max_score_row1 = xy_list[max_score_index1]
result.append(max_score_row1)
.......................................
.......................................
# 依次匹配题目答案即可
注:若转载请注明大神论坛来源(本贴地址)与作者信息。
|


 发表于 2024-01-17 22:16
发表于 2024-01-17 22:16





 评分
评分 顶
顶 踩
踩 扫码赞助
扫码赞助