本帖最后由 pringzl 于 2024-03-09 08:57 编辑
0 更简单的方法
直接f12之后在控制台输入下列代码之后打印即可。 document.body.innerHTML = document.querySelector(".tpl_main").innerHTML
1 前言
写简历找工作啦,百度随便搜索了一个简历制作网站。一顿编辑简历突然发现这个网站导出为任何一个简历为pdf居然需要vip,网站上面写着免费制作但是下载收费是吧,实属吃相有点难看了。
点击下载简历会提示开vip 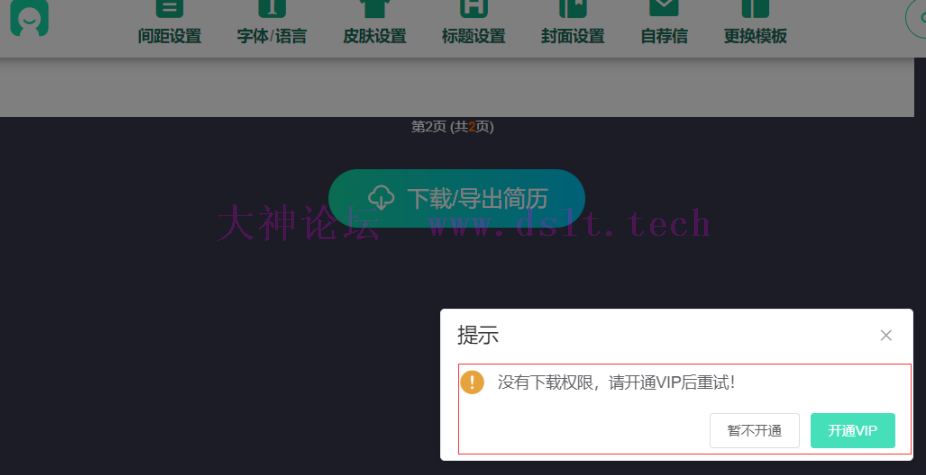
2 逆向分析
在没有vip的情况下通过fiddler抓包发现下载时会先发送请求获取vip信息
所有链接关键字符已替换
获取vip信息请求链接:https://——————/xxxx/resume/getVipInfo?userId=xxx&loginCode=xxxx&t=xxxxx
获取vip信息响应结果:{"code":1,"status":"success","data":[{"id":xxxxx,"vip":0,"resumeList":"","downNum":0,"aiNum":0,"vipTime":null}]}
直观上感觉vip为1时就代表有vip,然后vipTime代表vip到期时间。
替换后响应如下: 
然后手动修改了一下响应体之后再次点击下载简历,果然点击下载简历的时候,开始进行pdf的下载请求。
下载请求:https://---------/online/downpdf HTTP/1.1 
但是故事到这里还没有结束,请求接口会发现响应为{"code":2,"status":"error","data":"您不是会员,没有下载权限!"},无法下载。显然后端验证了vip权限,此时无解。
但是我们的目的是得到pdf文件。而不是一定需要通过接口去得到pdf文件
观察了下载链接的请求,请求体为: {
"userId": xxxxx,
"loginCode": "xxxx",
"resumeId": "xxxx",
"cssStr": "css样式",
"htmlDom": "html元素",
"type": "pdf"
}
通过观察可以知道简历文件由请求体的cssStr与htmlDom共同构成最终由html样板代码代码加上这两个字符串,保存为一个html文件,之后在浏览器打开之后在利用浏览器自带的pdf打印即可打印出来简历
如下所示: <!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<style type="text/css">
cssStr
</style>
<body>
htmlDom(注意这里需要取出转义字符"\")
</body>
</html>
3 最终结果
网页端编辑结果为: 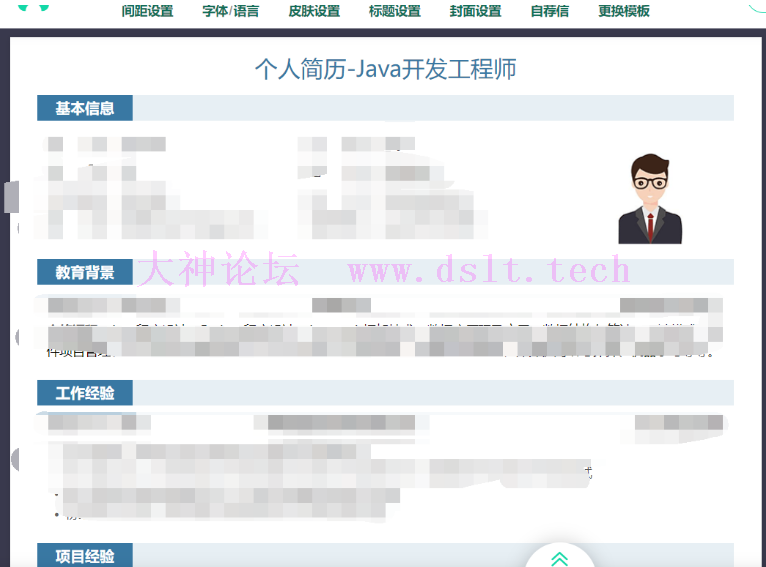
最终通过浏览器打印出来的pdf如下,可以看出是一致的: 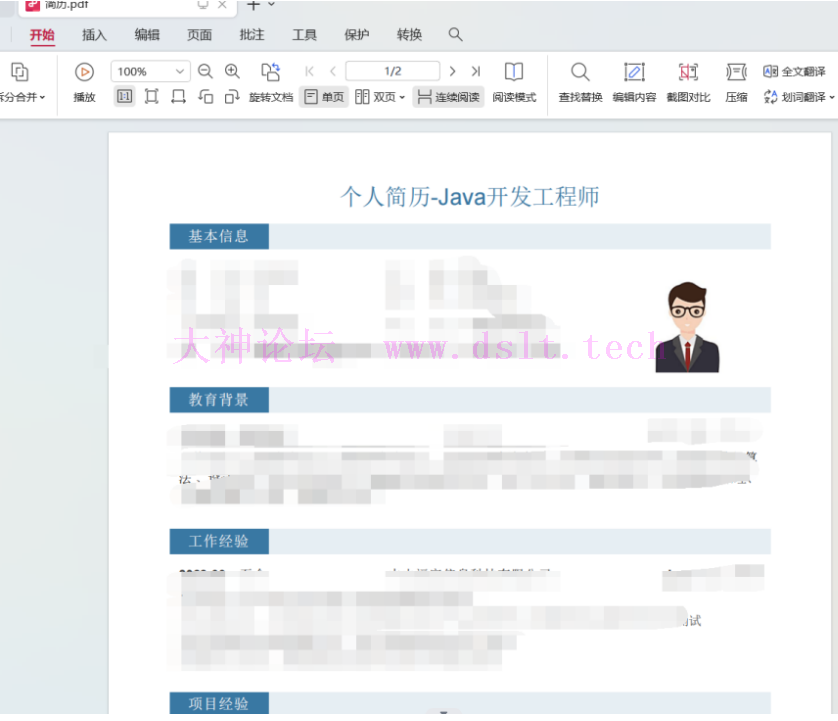
4 后续部分问题处理
浏览器打印需要进行如下设置才能正确打印出需要的简历 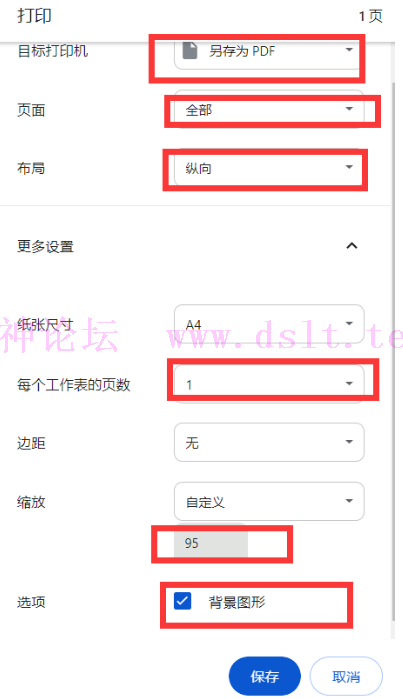
经回复反映确实存在图标缺失的问题。经过排查是因为没有导入字体文件的原因,按照图示即可找到引入字体文件的css,只需要导入css以及字体文件,就会有图标了 
我整理好了如果出现技能条缺失或者出现图表缺失导入下列css代码即可
字体css链接:https://www.alipan.com/s/M8BJifghQ4P
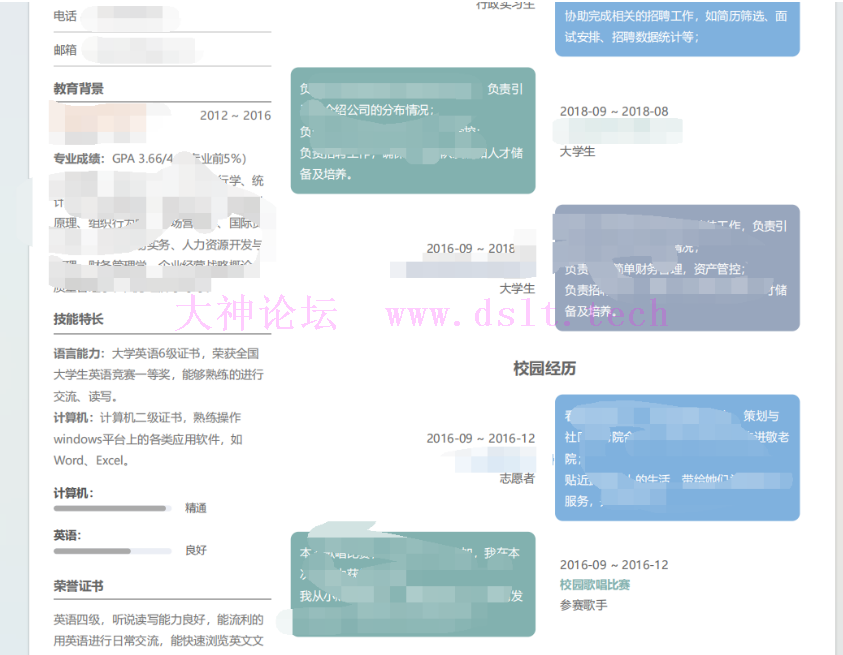
5 补充图标的pdf 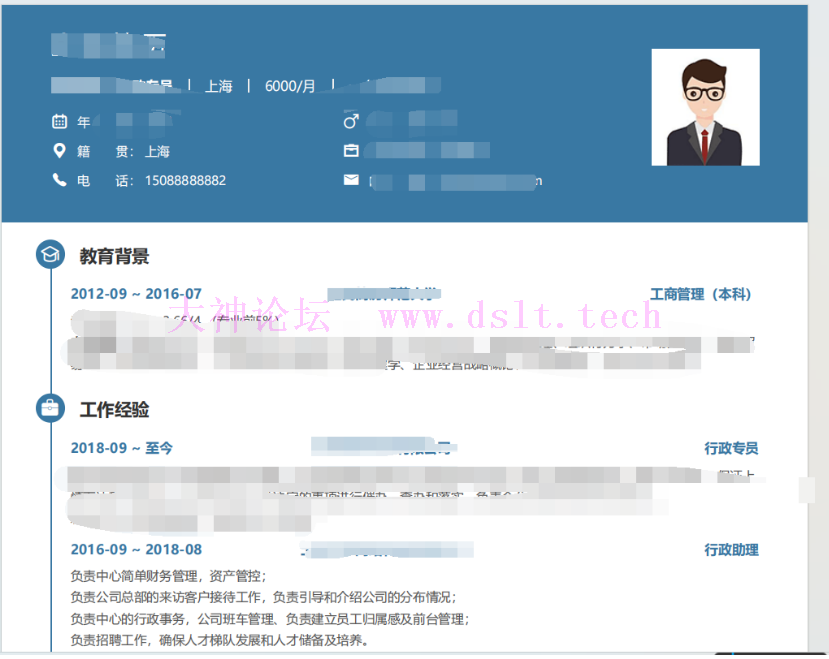
注:若转载请注明大神论坛来源(本贴地址)与作者信息。
|


 发表于 2024-03-09 08:57
发表于 2024-03-09 08:57





 评分
评分 顶
顶 踩
踩 扫码赞助
扫码赞助