本帖最后由 阿拉灯神丁 于 2025-12-29 22:52 编辑
声明本文章中所有内容仅供学习交流使用,不用于其他任何目的,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!若有侵权,请联系作者删除。 前言分析网站是官网接口,网址:https://tianyu.360.cn/#/global/details/sliding-puzzle 接口分析auth接口获取图片信息,跟校验接口绑定的信息 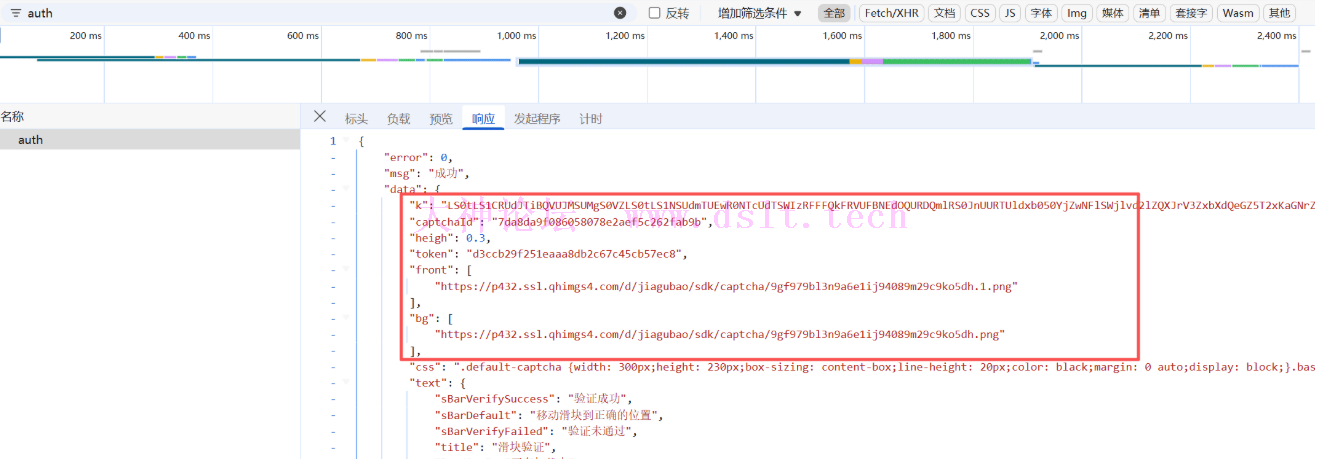
第一个接口有有效性校验,接口失效返回值如下: {"error":302,"msg":"参数错误","data":"请求时间间隔过大"}
check接口需要从前面auth接口获取参数,加密的参数只有report 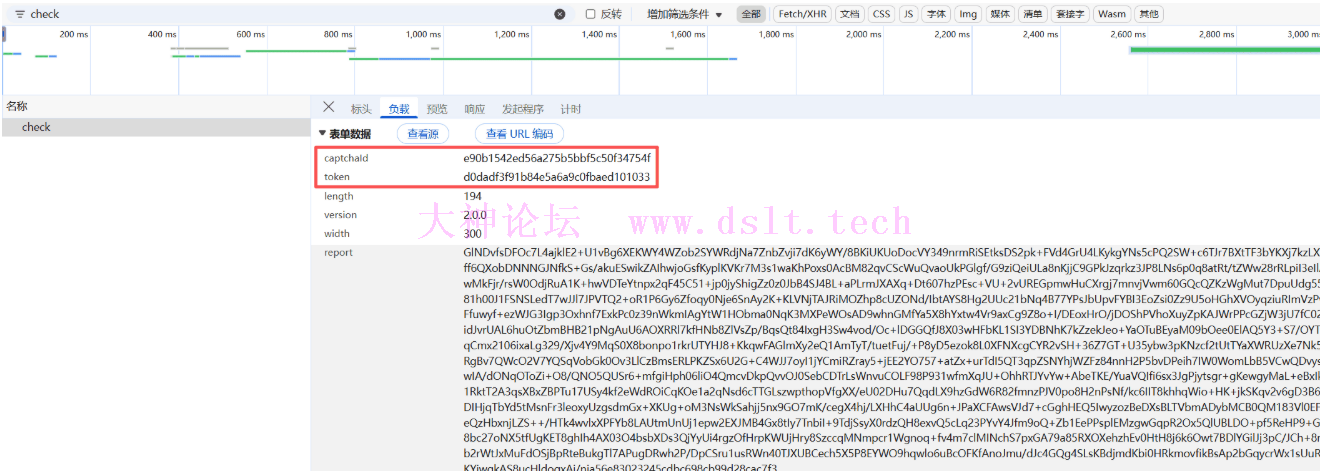
校验成功返回值 {
"error": 0,
"msg": "成功",
"data": {
"result": true,
"token": "d0dadf3f91b84e5a6a9c0fbaed101033"
}
}
校验失败返回值 {
"error": 0,
"msg": "成功",
"data": {
"result": false,
"token": "6acc453ec9b0f9e1dea29d8323906dac"
}
}
成功与失败的区别在于result 反调试分析无限debugger总共出现了两次,第一次是在quc7.js文件,这是在进入网站的时候出现的debugger 
第二次而是在打开验证码jgbCaptcha.js的时候出现,可以直接删除无限debugger代码也可以去hook掉 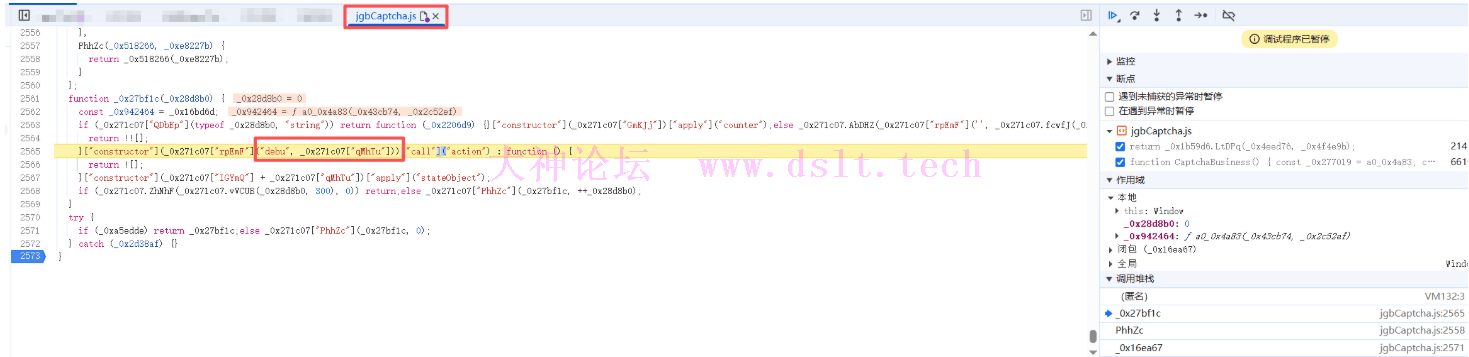
我比较懒,直接禁用断点(电脑比较好,不会卡死) 
解混淆打开代码调试都是清一色的混淆 混淆会将解混淆函数进行链式赋值 ,后续ast解的时候也需要去进行反向数据流分析 
解密函数分析 打断点进行解混淆函数内部,a0_0x4a83函数进去之后就会执行a0_0x3bf0函数返回一个大数组。 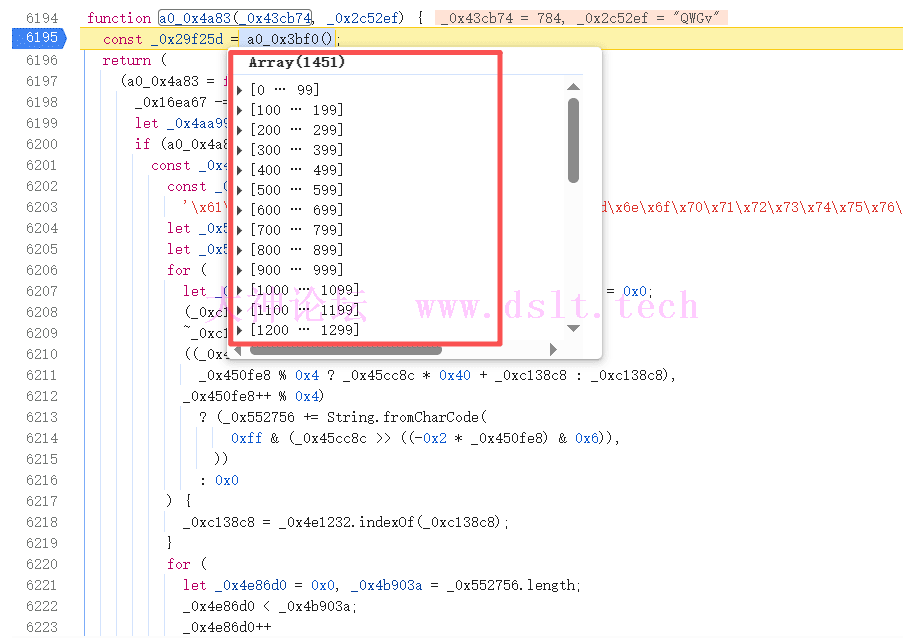
扣下来进行解混淆,跟网页上解的一致 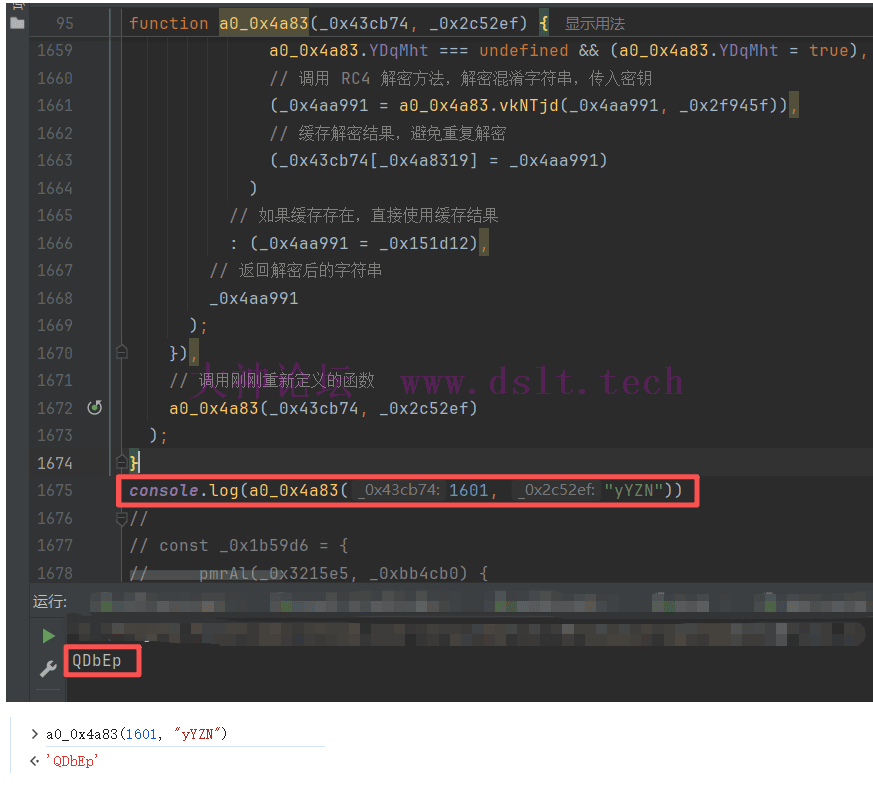
a0_0x4a83函数分析 function a0_0x4a83(_0x43cb74, _0x2c52ef) {
// 调用 a0_0x3bf0 函数,通常返回一个字符串数组,用于混淆字符串查找
const _0x29f25d =['大数组'];
// 重新定义 a0_0x4a83 函数,覆盖外层定义,实现字符串解密逻辑
return (
(a0_0x4a83 = function (_0x16ea67, _0x2f945f) {
// _0x16ea67 减去 0x125 (293 十进制),得到字符串数组的索引
_0x16ea67 -= 0x125;
// 从混淆字符串数组中取出对应的字符串
let _0x4aa991 = _0x29f25d[_0x16ea67];
// 如果函数属性 WHfHdj 未定义,表示首次调用,需要初始化解密相关函数
if (a0_0x4a83.WHfHdj === undefined) {
// 定义 Base64 解码函数
const _0x42c61e = function (_0x1bbdbc) {
// Base64 字符表
const _0x4e1232 =
'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789+/=';
let _0x552756 = ''; // 用于存放解码后的二进制字符串
let _0x506698 = ''; // 用于存放经过 URI 编码的字符串
// 遍历输入字符串,做 Base64 解码
for (
let _0x450fe8 = 0x0, _0x45cc8c, _0xc138c8, _0x495cc0 = 0x0;
(_0xc138c8 = _0x1bbdbc.charAt(_0x495cc0++));
~_0xc138c8 &&
((_0x45cc8c =
_0x450fe8 % 0x4 ? _0x45cc8c * 0x40 + _0xc138c8 : _0xc138c8),
_0x450fe8++ % 0x4)
? (_0x552756 += String.fromCharCode(
0xff & (_0x45cc8c >> ((-0x2 * _0x450fe8) & 0x6)),
))
: 0x0
) {
// 获取当前字符在 Base64 字符表中的索引
_0xc138c8 = _0x4e1232.indexOf(_0xc138c8);
}
// 把解码后的每个字符转换成 %xx 格式的 URI 编码字符串
for (
let _0x4e86d0 = 0x0, _0x4b903a = _0x552756.length;
_0x4e86d0 < _0x4b903a;
_0x4e86d0++
) {
_0x506698 += `%${`00${_0x552756
.charCodeAt(_0x4e86d0)
.toString(16)}`.slice(-2)}`;
}
// 用 decodeURIComponent 解码还原成原始字符串
return decodeURIComponent(_0x506698);
};
// 定义 RC4 解密函数,参数是要解密的字符串和密钥
const _0x9ab465 = function (_0x3614d5, _0x3f6c1) {
const _0x535bee = []; // 256字节S盒
let _0x37a0ac = 0x0;
let _0x19c8f6;
let _0x16b8c5 = ''; // 存放解密结果
// 先用 Base64 解码函数解码密文
_0x3614d5 = _0x42c61e(_0x3614d5);
let _0x20fcb3;
// 初始化 S 盒为 [0,1,2,...255]
for (_0x20fcb3 = 0x0; _0x20fcb3 < 0x100; _0x20fcb3++) {
_0x535bee[_0x20fcb3] = _0x20fcb3;
}
// 用密钥对 S 盒进行置换,KSA 算法阶段
for (_0x20fcb3 = 0x0; _0x20fcb3 < 0x100; _0x20fcb3++) {
_0x37a0ac =
(_0x37a0ac +
_0x535bee[_0x20fcb3] +
_0x3f6c1.charCodeAt(_0x20fcb3 % _0x3f6c1.length)) %
0x100;
_0x19c8f6 = _0x535bee[_0x20fcb3];
_0x535bee[_0x20fcb3] = _0x535bee[_0x37a0ac];
_0x535bee[_0x37a0ac] = _0x19c8f6;
}
// 初始化 i, j 指针为 0,准备 PRGA 随机输出阶段
_0x20fcb3 = 0x0;
_0x37a0ac = 0x0;
// 遍历输入字符串进行异或解密
for (let _0x1d322f = 0x0; _0x1d322f < _0x3614d5.length; _0x1d322f++) {
_0x20fcb3 = (_0x20fcb3 + 1) % 0x100;
_0x37a0ac = (_0x37a0ac + _0x535bee[_0x20fcb3]) % 0x100;
// 交换 S 盒两个值
_0x19c8f6 = _0x535bee[_0x20fcb3];
_0x535bee[_0x20fcb3] = _0x535bee[_0x37a0ac];
_0x535bee[_0x37a0ac] = _0x19c8f6;
// 生成伪随机字节,与密文对应字符异或,得到明文字符
_0x16b8c5 += String.fromCharCode(
_0x3614d5.charCodeAt(_0x1d322f) ^
_0x535bee[
(_0x535bee[_0x20fcb3] + _0x535bee[_0x37a0ac]) % 0x100
],
);
}
// 返回解密后的字符串
return _0x16b8c5;
};
// 把 RC4 解密函数保存到 a0_0x4a83 的 vkNTjd 属性,方便后续调用
a0_0x4a83.vkNTjd = _0x9ab465;
// 保存当前函数调用的参数对象到 _0x43cb74
_0x43cb74 = arguments;
// 标记初始化已完成,避免重复定义函数
a0_0x4a83.WHfHdj = true;
}
// 取混淆字符串数组第一个元素(一般是一个整数字符或偏移量)
const _0x3bf02c = _0x29f25d[0x0];
// 计算缓存键值,索引 + 第一个元素的值
const _0x4a8319 = _0x16ea67 + _0x3bf02c;
// 取缓存结果(如果之前解密过,会存在 arguments 对象中)
const _0x151d12 = _0x43cb74[_0x4a8319];
return (
// 如果缓存不存在,进行解密并缓存
!_0x151d12
? (
// 初始化标记,表示进行了解密
a0_0x4a83.YDqMht === undefined && (a0_0x4a83.YDqMht = true),
// 调用 RC4 解密方法,解密混淆字符串,传入密钥
(_0x4aa991 = a0_0x4a83.vkNTjd(_0x4aa991, _0x2f945f)),
// 缓存解密结果,避免重复解密
(_0x43cb74[_0x4a8319] = _0x4aa991)
)
// 如果缓存存在,直接使用缓存结果
: (_0x4aa991 = _0x151d12),
// 返回解密后的字符串
_0x4aa991
);
}),
// 调用刚刚重新定义的函数
a0_0x4a83(_0x43cb74, _0x2c52ef)
);
}
然后除了这个字符串解混淆之外还有对象方法混淆 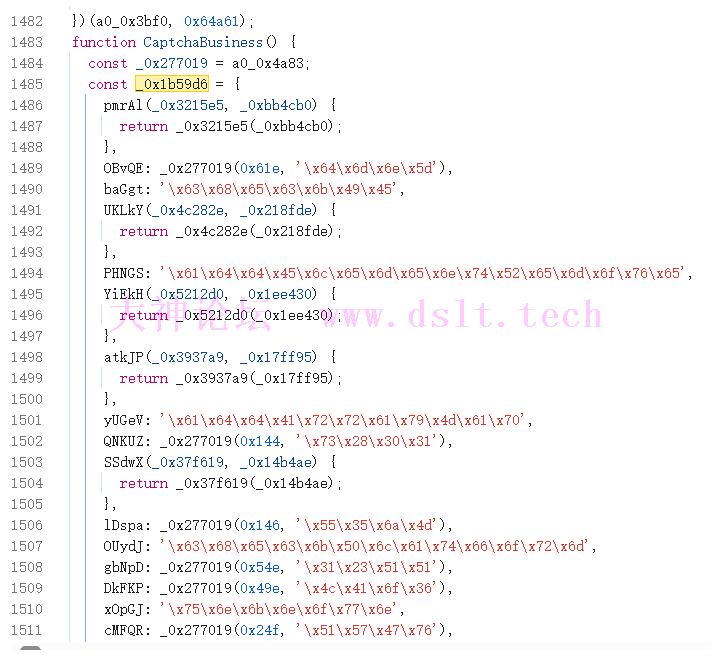
具体哪些混淆都已经分析完毕,接下来开始解混淆 不清楚各位ast大佬的思路是怎么解的,我的思路比较愚笨可能不是最优解不是很好,不过暂且能用,望多多指教!目前我的思路如下: - 收集所有混淆用的对象和函数映射
- 创建安全的沙箱环境执行解密函数
- 遍历AST,将混淆调用替换为实际值
- 处理链式别名,确保所有变体都能被识别
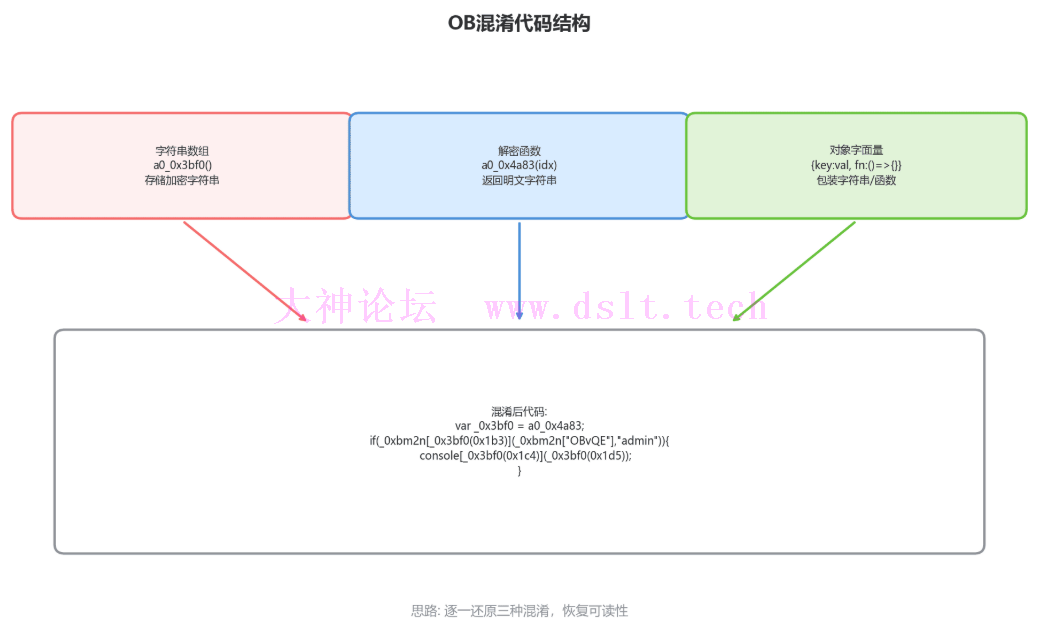
混淆代码主要特征: - 存在一个大数组存储所有字符串
- 存在解密函数
a0_0x4a83 用于从数组中取值 - 存在多个对象字面量,属性值为字符串或函数包装
- 代码中大量使用十六进制数字
文件说明: jie.js: 解密函数/_0x1b59d6对象文件demo.js: 混淆的源文件decodeResult.js: 输出文件
整体解混淆流程如下: 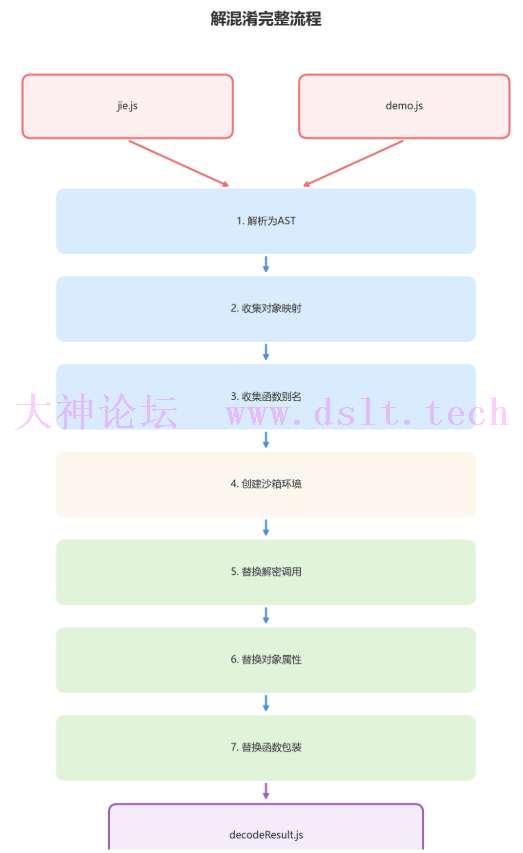
第一步:收集对象字面量映射混淆代码中存在大量对象字面量,用于存储字符串和函数包装: var _0xbm2n = {
"OBvQE": "admin", // 字符串字面量
"pQrSt": "123456", // 字符串字面量
"uVwXy": function(a, b) { // 比较函数包装
return a === b;
},
"eFgHi": function(fn, x) { // 函数调用包装
return fn(x);
}
};
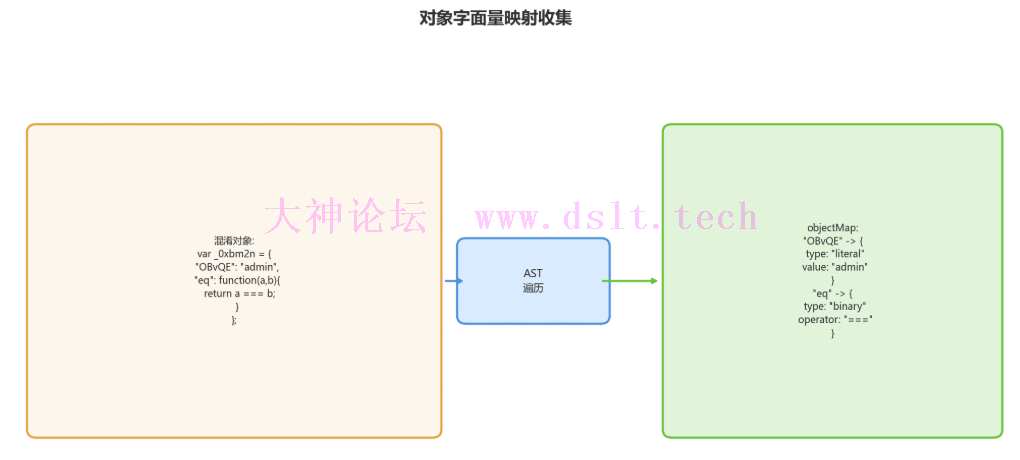
AST代码实现: let objectMap = new Map(); // objName -> { propName -> value }
traverse(decryptAst, {
VariableDeclarator(path) {
const {id, init} = path.node;
if (!types.isIdentifier(id) || !types.isObjectExpression(init)) return;
const objName = id.name;
const props = {};
let hasValidProps = false;
for (const prop of init.properties) {
if (prop.computed || types.isSpreadElement(prop)) continue;
let keyName;
if (types.isIdentifier(prop.key)) {
keyName = prop.key.name;
} else if (types.isStringLiteral(prop.key)) {
keyName = prop.key.value;
} else {
continue;
}
// 字符串字面量
if (types.isStringLiteral(prop.value)) {
props[keyName] = { type: 'literal', value: prop.value.value };
hasValidProps = true;
}
// 数字字面量
else if (types.isNumericLiteral(prop.value)) {
props[keyName] = { type: 'literal', value: prop.value.value };
hasValidProps = true;
}
// 函数包装处理
}
if (hasValidProps) {
objectMap.set(objName, props);
}
}
});
第二步:收集解密函数别名混淆代码中解密函数会被多次赋值给不同变量,形成别名链: var a0_0x4a83 = function(i) { ... }; // 原始解密函数
var a0l = a0_0x4a83; // 一级别名
function test() {
var bd = a0l; // 二级别名
var bT = bd; // 三级别名
console.log(bT(0x100)); // 实际调用
}
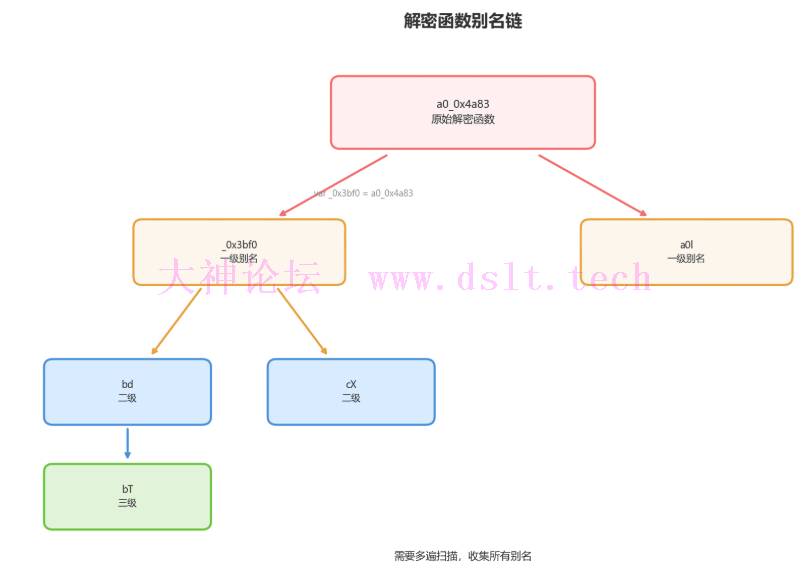
需要多遍扫描才能收集完整的别名链: let aliasMap = new Map();
// 先从 jie.js 找一级别名
traverse(decryptAst, {
VariableDeclarator(path) {
const {id, init} = path.node;
if (init && init.type === 'Identifier' && init.name === 'a0_0x4a83') {
if (id && id.type === 'Identifier') {
aliasMap.set(id.name, 'a0_0x4a83');
}
}
}
});
// 再从 demo.js 找
traverse(ast, {
VariableDeclarator(path) {
const {id, init} = path.node;
if (init && init.type === 'Identifier' && init.name === 'a0_0x4a83') {
if (id && id.type === 'Identifier') {
console.log(`找到一级别名: ${id.name} = a0_0x4a83`);
aliasMap.set(id.name, 'a0_0x4a83');
}
}
}
});
// 多遍扫描链式别名
let foundNew = true;
let round = 1;
while (foundNew) {
foundNew = false;
traverse(ast, {
VariableDeclarator(path) {
const {id, init} = path.node;
if (init && init.type === 'Identifier') {
if (aliasMap.has(init.name) && id && id.type === 'Identifier' && !aliasMap.has(id.name)) {
console.log(`找到${round + 1}级别名: ${id.name} = ${init.name}`);
aliasMap.set(id.name, 'a0_0x4a83');
foundNew = true;
}
}
}
});
round++;
if (round > 10) break; // 防止死循环
}
console.log(`\n共找到 ${aliasMap.size} 个解密函数别名\n`);
第三步:创建沙箱执行环境为了安全地执行解密函数,需要创建一个沙箱环境: 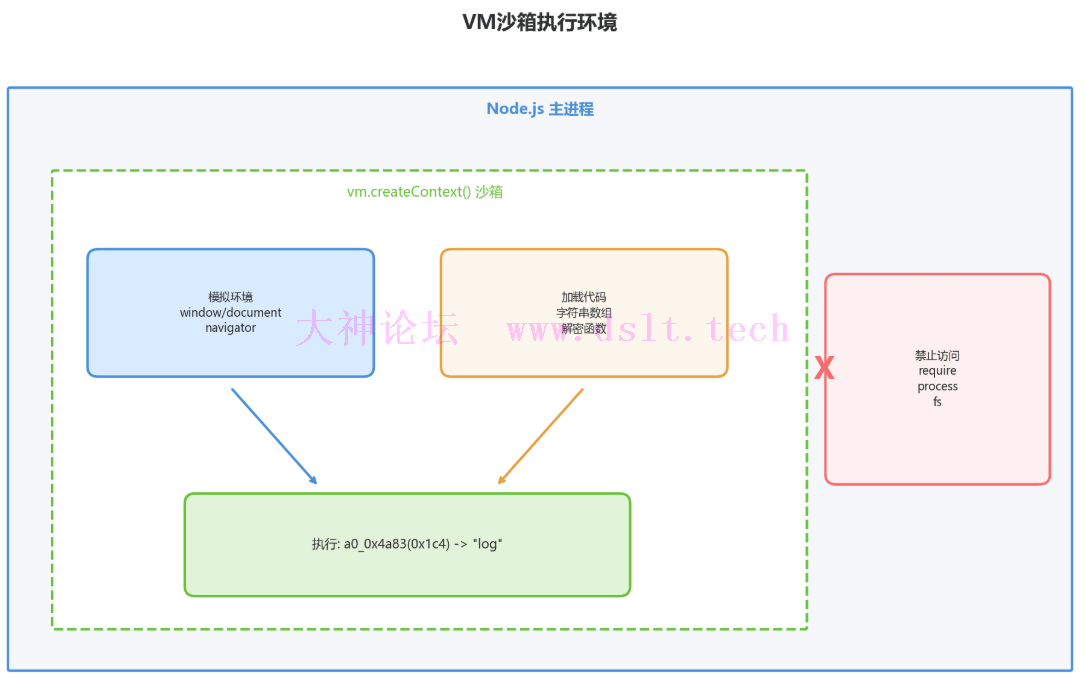
const vm = require('vm');
// 模拟浏览器环境
const sandbox = {
console,
window: {},
document: {
createElement: () => ({}),
getElementsByTagName: () => [],
head: { appendChild: () => {} }
},
navigator: { userAgent: '' },
location: { href: '', hostname: '' },
setTimeout: () => {},
setInterval: () => {},
clearTimeout: () => {},
clearInterval: () => {}
};
sandbox.window = sandbox;
sandbox.self = sandbox;
sandbox.global = sandbox;
vm.createContext(sandbox);
try {
vm.runInContext(decryptCode, sandbox, { timeout: 5000 });
console.log('✓ 解密函数已加载\n');
} catch (e) {
console.log('⚠ 加载解密函数警告:', e.message);
}
第四步:替换解密函数调用这是最核心的一步,将所有解密函数调用替换为实际字符串: 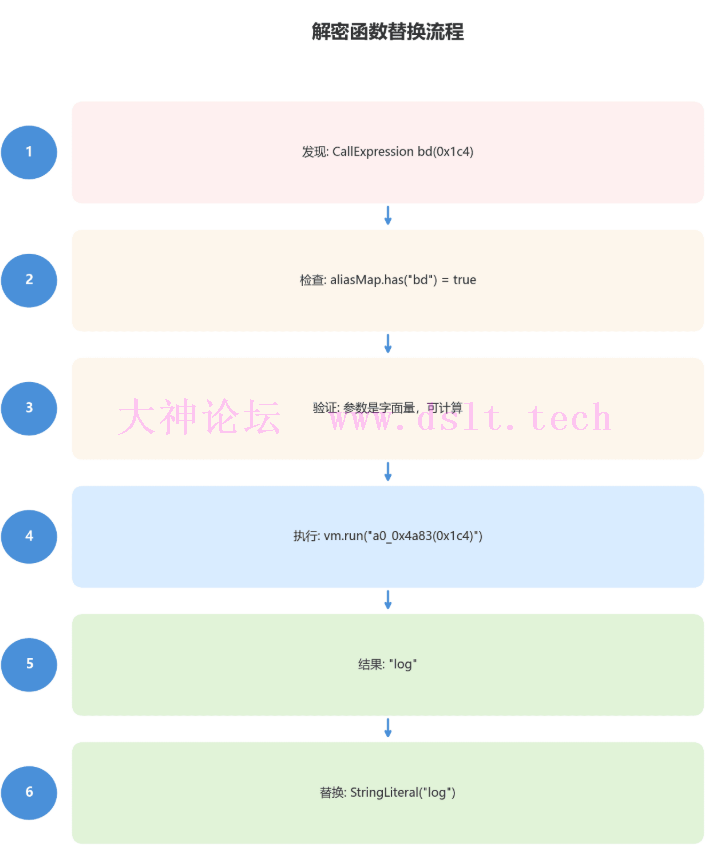
function isNodeLiteral(node) {
if (Array.isArray(node)) return node.every(ele => isNodeLiteral(ele));
if (types.isLiteral(node)) return node.value != null;
if (types.isBinaryExpression(node)) return isNodeLiteral(node.left) && isNodeLiteral(node.right);
if (types.isUnaryExpression(node, {"operator": "-"}) || types.isUnaryExpression(node, {"operator": "+"})) {
return isNodeLiteral(node.argument);
}
return false;
}
let decryptSuccess = 0, decryptFail = 0;
traverse(ast, {
CallExpression(path) {
let {callee, arguments: args} = path.node;
if (!types.isIdentifier(callee)) return;
const funcName = callee.name;
// 检查是否是解密函数或其别名
if (funcName !== 'a0_0x4a83' && !aliasMap.has(funcName)) return;
// 检查参数是否都是字面量
if (!isNodeLiteral(args)) return;
try {
const originalCode = generator(path.node, {compact: true}).code;
// 将别名替换为原始函数名
let codeToEval = funcName !== 'a0_0x4a83'? originalCode.replace(funcName, 'a0_0x4a83'): originalCode;
// 在沙箱中执行
let value = vm.runInContext(codeToEval, sandbox, { timeout: 1000 });
// 替换节点
path.replaceWith(types.valueToNode(value));
decryptSuccess++;
} catch (e) {
decryptFail++;
}
}
});
console.log(`解密函数替换: 成功 ${decryptSuccess}, 失败 ${decryptFail}\n`);
第五步:替换对象属性访问将对象属性访问替换为实际值: // 混淆代码
obj["OBvQE"] // → "admin"
obj.pQrSt // → "123456"
AST代码实现: let objLiteralSuccess = 0;
traverse(ast, {
MemberExpression(path) {
const {object, property, computed} = path.node;
if (!types.isIdentifier(object)) return;
const objName = object.name;
if (!objectMap.has(objName)) return;
const props = objectMap.get(objName);
let propName;
if (computed && types.isStringLiteral(property)) {
propName = property.value;
} else if (!computed && types.isIdentifier(property)) {
propName = property.name;
} else {
return;
}
if (!props[propName]) return;
const propInfo = props[propName];
// 只替换字面量,不替换函数
if (propInfo.type === 'literal') {
// 确保不是被调用的
if (path.parentPath && types.isCallExpression(path.parentPath.node) &&
path.parentPath.node.callee === path.node) {
return;
}
path.replaceWith(types.valueToNode(propInfo.value));
objLiteralSuccess++;
}
}
});
console.log(`对象字面量替换: ${objLiteralSuccess} 个\n`);
第六步:替换对象函数调用对象中的函数包装有两种类型: 
1. 函数调用包装// 定义
wrapper: function(a, b, c) { return a(b, c); }
// 调用
obj.wrapper(myFunc, x, y) // → myFunc(x, y)
2. 二元运算包装// 定义
eq: function(a, b) { return a === b; }
// 调用
obj.eq(user, "admin") // → user === "admin"
AST代码实现: let objFuncSuccess = 0;
traverse(ast, {
CallExpression(path) {
const {callee, arguments: args} = path.node;
if (!types.isMemberExpression(callee)) return;
const {object, property, computed} = callee;
if (!types.isIdentifier(object)) return;
const objName = object.name;
if (!objectMap.has(objName)) return;
const props = objectMap.get(objName);
let propName;
if (computed && types.isStringLiteral(property)) {
propName = property.value;
} else if (!computed && types.isIdentifier(property)) {
propName = property.name;
} else {
return;
}
if (!props[propName]) return;
const propInfo = props[propName];
// 函数调用包装:obj.func(fn, a, b) -> fn(a, b)
if (propInfo.type === 'call') {
const { argIndices } = propInfo;
if (args.length > 0) {
const realCallee = args[0];
const realArgs = argIndices.map(idx => args[idx]).filter(a => a !== undefined);
const newCall = types.callExpression(realCallee, realArgs);
path.replaceWith(newCall);
objFuncSuccess++;
}
}
// 二元运算:obj.func(a, b) -> a + b
else if (propInfo.type === 'binary') {
const { operator, leftIdx, rightIdx } = propInfo;
if (args[leftIdx] && args[rightIdx]) {
const newExpr = types.binaryExpression(operator, args[leftIdx], args[rightIdx]);
path.replaceWith(newExpr);
objFuncSuccess++;
}
}
}
});
console.log(`对象函数调用替换: ${objFuncSuccess} 个\n`);
第七步:简化字面量格式将十六进制数字和Unicode字符串转为可读格式: // 0x100 → 256
// "\x68\x65\x6c\x6c\x6f" → "hello"
traverse(ast, {
NumericLiteral({node}) {
if (node.extra && /^0[obx]/i.test(node.extra.raw)) {
node.extra = undefined;
}
},
StringLiteral({node}) {
if (node.extra && /\\[ux]/gi.test(node.extra.raw)) {
node.extra = undefined;
}
},
});
解混淆效果对比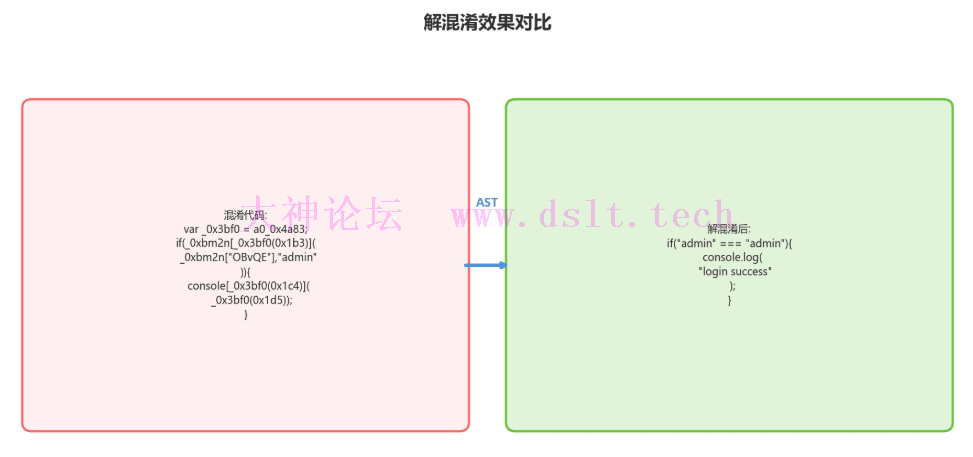
混淆前var _0x3bf0 = a0_0x4a83;
var _0xbm2n = {
"OBvQE": _0x3bf0(0x1a2),
"pQrSt": function(_0x1a2b, _0x3c4d) {
return _0x1a2b === _0x3c4d;
}
};
if (_0xbm2n[_0x3bf0(0x1b3)](_0xbm2n["OBvQE"], "admin")) {
console[_0x3bf0(0x1c4)](_0x3bf0(0x1d5));
}
解混淆后var _0xbm2n = {
"OBvQE": "admin",
"pQrSt": function(_0x1a2b, _0x3c4d) {
return _0x1a2b === _0x3c4d;
}
};
if ("admin" === "admin") {
console.log("login success");
}
auth接口auth接口只有一个sign参数加密 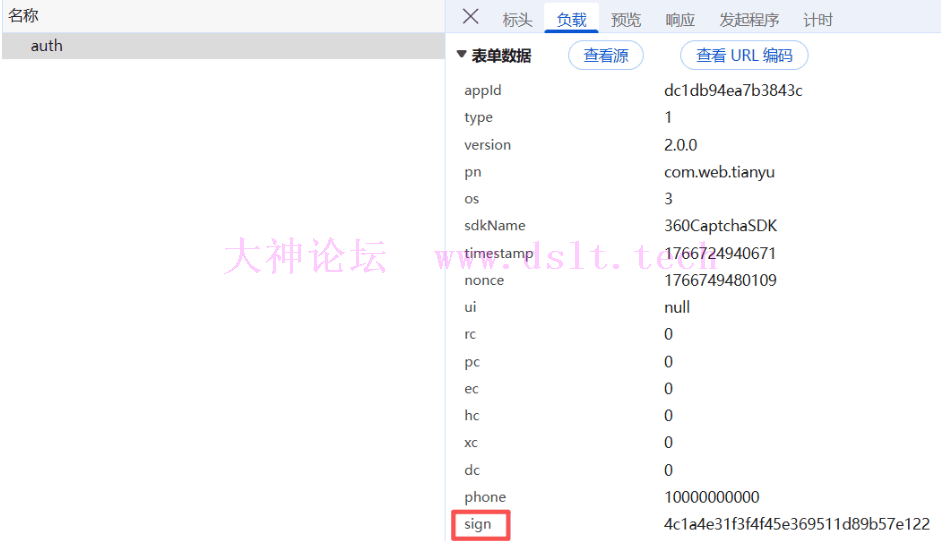
进入堆栈搜索sign关键词打断点刷新图片 
代码扣下来分析,函数名字俺命名为sign函数 function sign(_0x392c78) {
const _0x2639ff = _0x5354ca;
const _0x18ee40 = {
appId: _0x392c78["aid"],
type: 1,
version: _0x392c78["version"],
pn: _0x392c78.pn,
os: _0x392c78.os,
sdkName: _0x392c78["sdkName"],
timestamp: Math.round(new Date()["getTime"]()),
nonce: Math["round"](new Date()["getTime"]()) + Math["floor"](100000000 * Math["random"]()),
ui: null,
rc: 0,
pc: 0,
ec: 0,
hc: 0,
xc: 0,
dc: 0,
phone: _0x392c78["phone"]
};
let _0x3ca1de = '';
const _0x2a4d77 = Object["keys"](_0x18ee40).sort();
for (let _0x1ee694 = 0; _0x1ee694 < _0x2a4d77["length"]; _0x1ee694++) {
_0x3ca1de += String(_0x2a4d77[_0x1ee694]) + String(_0x18ee40[_0x2a4d77[_0x1ee694]]);
}
return _0x18ee40["sign"] = md5(_0x3ca1de), _0x18ee40;
};
传参_0x392c78经分析是不变化的一个对象 _0x392c78 ={
"obj": "_jg", // 对象名或模块标识,可能是“Jiagu”的缩写
"aid": "aid", // 应用ID或授权标识,用于识别应用
"prefix": "jg_captcha", // 资源或变量前缀,用于命名区分
"version": "2.0.0", // SDK或接口版本号
"sdkName": "***CaptchaSDK", // SDK名称,表明是***验证码SDK
"type": 1, // 验证码类型,数字编码
"pic_cdn": "", // 图片CDN地址,空字符串表示未配置
"typeMap": { // 类型映射表,数字类型对应字符串名称
"0": "basic", // 0表示基础验证码
"1": "clickword" // 1表示点击文字验证码
},
"captchaTypeMap": { // 类型常量映射,方便代码中使用常量名称
"TYPE_BASIC": 0, // 基础验证码常量值为0
"TYPE_CLICK": 1 // 点击验证码常量值为1
},
"noserverImgSrc": "https://cdn.jiagu.com/images/default.jpg", // 验证码加载失败时显示的默认图片地址
"api_server": "https://captcha.jiagu.***.cn", // ***加固验证码API服务器基础地址
"api_auth": "https://captcha.jiagu.***.cn/api/v3/auth", // 验证码认证接口地址,用于获取授权信息
"api_verify": "https://captcha.jiagu.***.cn/api/v3/check", // 验证接口地址,用于提交验证码结果验证
"height": 150, // 验证码图片或组件高度,单位像素
"os": 3, // 操作系统编号,具体含义需参考SDK文档(一般3可能代表Web)
"pn": "com.web.tianyu", // 产品名或包名,标识调用此SDK的项目
"phone": 10000000000 // 手机号码示例,估计登录或者注册接口会获取吧(猜测)
}
这个sign函数就是将固定值对象_0x392c78取值进行生成签名,然后加密明文有时间戳,所以就有了接口的有效性校验。生成签名之后最后赋值给对象返回 function sign(_0x392c78) {
const _0x2639ff = _0x5354ca; // 混淆代码残留
// 构造一个对象,包含多种参数,用于生成签名
const _0x18ee40 = {
appId: _0x392c78["aid"], // 应用ID,从传入参数获取
type: 1, // 固定类型值,这里为1
version: _0x392c78["version"], // 版本号,从传入参数获取
pn: _0x392c78.pn, // 产品名或包名,从传入参数获取
os: _0x392c78.os, // 操作系统标识,从传入参数获取
sdkName: _0x392c78["sdkName"], // SDK名称,从传入参数获取
timestamp: Math.round(new Date()["getTime"]()),// 当前时间戳(毫秒),取整
// 生成一个随机数nonce,先取当前时间戳,后加一个0~1亿的随机整数
nonce: Math["round"](new Date()["getTime"]()) + Math["floor"](100000000 * Math["random"]()),
ui: null, // 未知参数,赋值null
rc: 0, // 计数参数,初始为0
pc: 0, // 计数参数,初始为0
ec: 0, // 计数参数,初始为0
hc: 0, // 计数参数,初始为0
xc: 0, // 计数参数,初始为0
dc: 0, // 计数参数,初始为0
phone: _0x392c78["phone"] // 手机号,从传入参数获取
};
// 用于拼接字符串以计算签名
let _0x3ca1de = '';
// 获取上面对象的所有键名并排序
const _0x2a4d77 = Object["keys"](_0x18ee40).sort();
// 遍历排序后的键,把“键名+键值”拼接成字符串
for (let _0x1ee694 = 0; _0x1ee694 < _0x2a4d77["length"]; _0x1ee694++) {
_0x3ca1de += String(_0x2a4d77[_0x1ee694]) + String(_0x18ee40[_0x2a4d77[_0x1ee694]]);
}
// 对拼接好的字符串进行MD5加密,得到签名,赋值给对象的 sign 属性
_0x18ee40["sign"] = md5(_0x3ca1de);
// 返回这个完整的参数对象(包含签名)
return _0x18ee40;
};
图片下载下来之后发现是乱序图片 
底图还原监听canvas事件 
刷新图片,断点断下来了,可以很清晰的看到代码有个decryptImage,_0x5080d6.onload函数扣下来逐行分析 
代码执行会操作一些dom元素,把关于dom元素的代码全部删掉 function onloadImg() {
// 设置画布宽度为图片宽度
_0x55ae6b.width = _0x5080d6["width"];
// 设置画布高度为图片高度
_0x55ae6b["height"] = _0x5080d6.height;
// 在画布上绘制原始图片,起点(0,0),宽高为图片宽高
_0x81f4b1["drawImage"](_0x5080d6, 0, 0, _0x5080d6.width, _0x5080d6.height);
// 从图片地址(imgSrc)中提取文件名(不含后缀)
// 先用 "/" 分割字符串,取倒数第一个元素,再用 "." 分割取第一个部分
const _0x251234 = imgSrc["split"]("/")[_0x18d30b["NfPti"](imgSrc["split"]("/")["length"], 1)]["split"](".")[0];
// 对文件名进行解密,得到一个数组或字符串(解密后的数据)
const _0x3e2bfc = decryptImage(_0x251234);
// 计算每个分块的宽度,等于图片宽度除以解密数组长度
const _0x519761 = Math.floor(_0x5080d6["width"] / _0x3e2bfc.length);
// 遍历解密后的数组,调用回调函数,参数为元素值和索引
convertArray(_0x3e2bfc, (_0x5ca950, _0x2f0818) => {
// 计算绘制时的x坐标,等于索引乘以单块宽度
const _0x5d28d3 = _0x41d868["POBxg"](_0x2f0818, _0x519761);
// 单块宽度
const _0x5bedd5 = _0x519761;
// 在画布上绘制图片的一部分
// 参数依次是:图片对象,
// 源图x坐标(_0x5d28d3),0(y坐标),
// 源图宽度(_0x5bedd5),源图高度(图片高度),
// 目标画布x坐标(_0x5ca950 * 单块宽度),0(y坐标),
// 目标画布宽度(_0x5bedd5),目标画布高度(图片高度)
_0x81f4b1["drawImage"](_0x5080d6, _0x5d28d3, 0, _0x5bedd5, _0x5080d6["height"], _0x5ca950 * _0x519761, 0, _0x5bedd5, _0x5080d6["height"]);
// 将画布内容导出为 PNG 格式的 buffer
const buffer = _0x55ae6b.toBuffer('image/png');
// 将 buffer 写入本地文件 'restored.png'
fs.writeFileSync('restored.png', buffer);
// 控制台输出提示信息,表明还原完成
console.log('还原完成: restored.png');
});
};
接下来就是缺啥补啥了。比较重要的两个函数decryptImage函数 function decryptImage(_0x121c70, _0x10dcdd) {
const _0x58b550 = {
uKQaL: "includes",
LRljw(_0x52e5da, _0x58ed7b) {
return _0x52e5da === _0x58ed7b;
}
};
function _0x1c18e2(_0x2a7547, _0x2daf7e) {
// 如果传入的数组有 includes 方法,直接调用 includes 判断
if (_0x2a7547[_0x58b550["uKQaL"]])
return _0x2a7547[_0x58b550["uKQaL"]](_0x2daf7e);
// 否则用 for 循环遍历数组进行比较判断
for (let _0x282371 = 0, _0xca62fe = _0x2a7547["length"]; _0x282371 < _0xca62fe; _0x282371++)
if (_0x58b550["LRljw"](_0x2a7547[_0x282371], _0x2daf7e))
return true;
return false;
}
// 这里用来遍历输入数组 _0x121c70 的元素,并根据条件处理
for (var _0x10dcdd = [], _0x66e9ff = 0; _0x187f8f["uKlOD"](_0x66e9ff, _0x121c70[_0x187f8f.dxGbO]); _0x66e9ff++) {
// 取当前索引元素
let _0x285e49 = _0x121c70[_0x187f8f["TuJhD"]](_0x66e9ff);
// 如果循环索引大于等于32,退出循环
if (_0x187f8f["hGfWD"](32, _0x66e9ff)) break;
// 当 _0x10dcdd 中包含 _0x285e49 - 32 时,_0x285e49 自增
while (_0x1c18e2(_0x10dcdd, _0x187f8f["hMfZz"](_0x285e49, 32))) {
_0x285e49++;
}
// 把 _0x285e49 - 32 的结果推入 _0x10dcdd 数组
_0x10dcdd.push(_0x187f8f.yMCrD(_0x285e49, 32));
}
// 返回处理后的数组
return _0x10dcdd;
};
convertArray函数: function convertArray(_0x8e4a4c, _0x1a03c8) {
// _0x8e4a4c: 输入的数组
// _0x1a03c8: 回调函数,参数通常是 (元素值, 索引)
// 初始化循环变量 _0x36c299 = 0,_0x1a01d8 是数组长度
// _0x1cd0cb 是新数组,用于存储转换后的结果
for (var _0x36c299 = 0, _0x1a01d8 = _0x8e4a4c["length"], _0x1cd0cb = []; _0x2dac90.GpUbe(_0x36c299, _0x1a01d8); _0x36c299++) {
// _0x2dac90.GpUbe 用于判断循环条件,类似于 (_0x36c299 < _0x1a01d8)
// 对数组的每个元素调用回调函数 _0x1a03c8,传入当前元素和索引
// 将回调函数返回值赋值给新数组对应位置
_0x1cd0cb[_0x36c299] = _0x2dac90["WyKvQ"](_0x1a03c8, _0x8e4a4c[_0x36c299], _0x36c299);
// _0x2dac90.WyKvQ 表示调用函数 _0x1a03c8,传入当前元素和索引
}
// 返回转换后的新数组
return _0x1cd0cb;
};
还原代码分析:
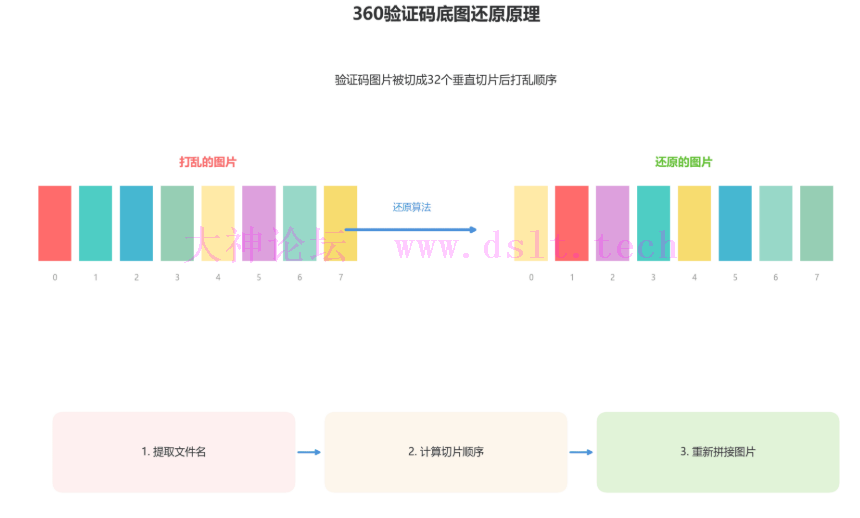
底图是被切成32个垂直切片后打乱顺序的,还原的关键在于: - 从图片URL中提取文件名
- 根据文件名计算出切片的正确顺序
- 按正确顺序重新拼接图片
环境初始化 // 引入 node-canvas 库,用于在 Node.js 环境中操作 canvas
const { createCanvas, loadImage } = require('canvas');
// 引入文件系统模块,用于保存还原后的图片
const fs = require('fs');
// 模拟浏览器中的 canvas 元素 <canvas width="544" height="284">
// _0x55ae6b 就是 canvas 元素
const _0x55ae6b = createCanvas(544, 284);
// 获取 canvas 的 2D 绑定上下文,用于绑制图像
const _0x81f4b1 = _0x55ae6b.getContext('2d');
// 图片对象,会被 loadImage 异步加载后赋值
_0x5080d6 = null;
// 验证码图片的 URL 地址
const imgSrc = '地址';
主函数 async function main() {
// 异步加载图片,返回 Image 对象
_0x5080d6 = await loadImage(imgSrc);
// 保留 src 属性(注意:node-canvas 中此赋值可能无效,需要直接使用 imgSrc)
_0x5080d6.src = imgSrc;
// 调用图片还原函数
onloadImg();
}
核心解密函数 - decryptImage 这是底图还原的核心算法,根据文件名计算切片顺序: 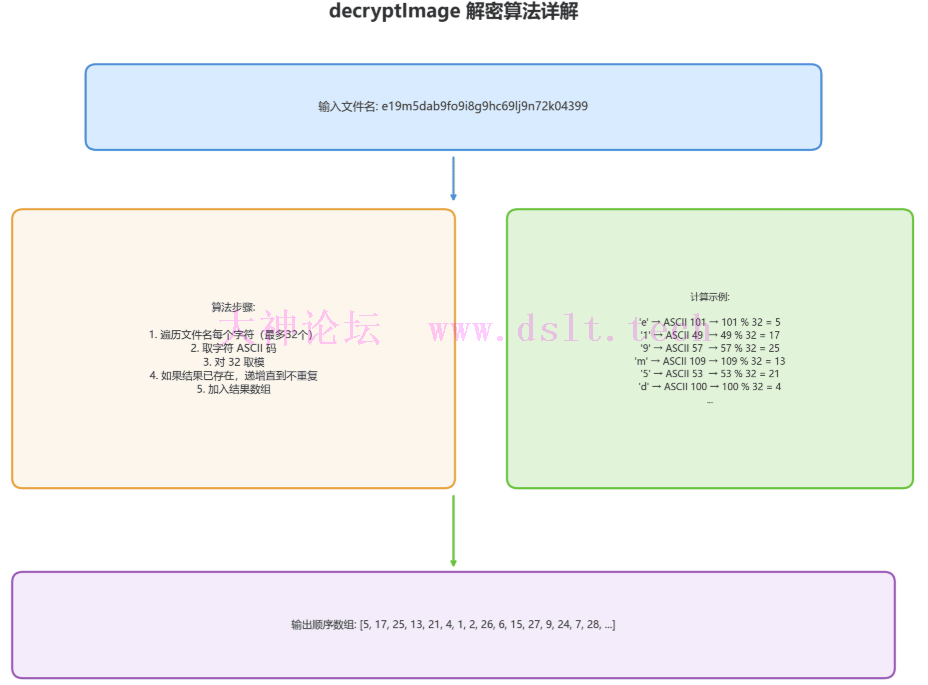
/**
* 解密图片切片顺序
* @Param {string} _0x121c70 - 图片文件名(不含扩展名)
* @returns {number[]} - 切片顺序数组,长度为32
*
* 算法原理:
* 1. 遍历文件名的每个字符(最多32个)
* 2. 取字符的 ASCII 码对 32 取模
* 3. 如果结果已存在于数组中,则递增直到不重复
* 4. 将结果加入数组
*/
function decryptImage(_0x121c70, _0x10dcdd) {
const _0x58b550 = {
uKQaL: "includes", // 字符串常量
// 严格相等比较
LRljw(_0x52e5da, _0x58ed7b) {
return _0x52e5da === _0x58ed7b;
}
};
/**
* 检查数组是否包含某个值(兼容旧浏览器的 includes 实现)
* @param {array} _0x2a7547 - 要检查的数组
* @param {*} _0x2daf7e - 要查找的值
* @returns {boolean} - 是否包含
*/
function _0x1c18e2(_0x2a7547, _0x2daf7e) {
// 如果数组有 includes 方法,直接使用
if (_0x2a7547[_0x58b550["uKQaL"]])
return _0x2a7547[_0x58b550["uKQaL"]](_0x2daf7e);
// 否则手动遍历查找
for (let _0x282371 = 0, _0xca62fe = _0x2a7547["length"]; _0x282371 < _0xca62fe; _0x282371++)
if (_0x58b550["LRljw"](_0x2a7547[_0x282371], _0x2daf7e))
return true;
return false;
}
// 初始化结果数组
// _0x10dcdd = []
// _0x66e9ff = 0 (循环索引)
for (var _0x10dcdd = [], _0x66e9ff = 0;
_0x187f8f["uKlOD"](_0x66e9ff, _0x121c70[_0x187f8f.dxGbO]); // _0x66e9ff < _0x121c70.length
_0x66e9ff++) {
// 获取当前字符的 ASCII 码
// _0x285e49 = _0x121c70.charCodeAt(_0x66e9ff)
let _0x285e49 = _0x121c70[_0x187f8f["TuJhD"]](_0x66e9ff);
// 如果索引等于 32,跳出循环(最多处理32个字符)
// if (32 === _0x66e9ff) break;
if (_0x187f8f["hGfWD"](32, _0x66e9ff)) break;
// 如果 _0x285e49 % 32 已存在于数组中,则递增 _0x285e49
// while (_0x10dcdd.includes(_0x285e49 % 32)) _0x285e49++;
for (; _0x1c18e2(_0x10dcdd, _0x187f8f["hMfZz"](_0x285e49, 32));)
_0x285e49++;
// 将 _0x285e49 % 32 加入结果数组
// _0x10dcdd.push(_0x285e49 % 32);
_0x10dcdd.push(_0x187f8f.yMCrD(_0x285e49, 32));
}
// 返回切片顺序数组
return _0x10dcdd;
}
数组遍历函数 - convertArray function convertArray(_0x8e4a4c, _0x1a03c8) {
// 初始化循环变量和结果数组
// _0x36c299 = 0 (索引)
// _0x1a01d8 = _0x8e4a4c.length (数组长度)
// _0x1cd0cb = [] (结果数组)
for (var _0x36c299 = 0, _0x1a01d8 = _0x8e4a4c["length"], _0x1cd0cb = [];
_0x2dac90.GpUbe(_0x36c299, _0x1a01d8); // _0x36c299 < _0x1a01d8
_0x36c299++) {
// 调用回调函数,传入 (数组元素值, 索引)
// _0x1cd0cb[i] = callback(arr[i], i)
_0x1cd0cb[_0x36c299] = _0x2dac90["WyKvQ"](_0x1a03c8, _0x8e4a4c[_0x36c299], _0x36c299);
}
return _0x1cd0cb;
}
图片还原主函数 - onloadImg 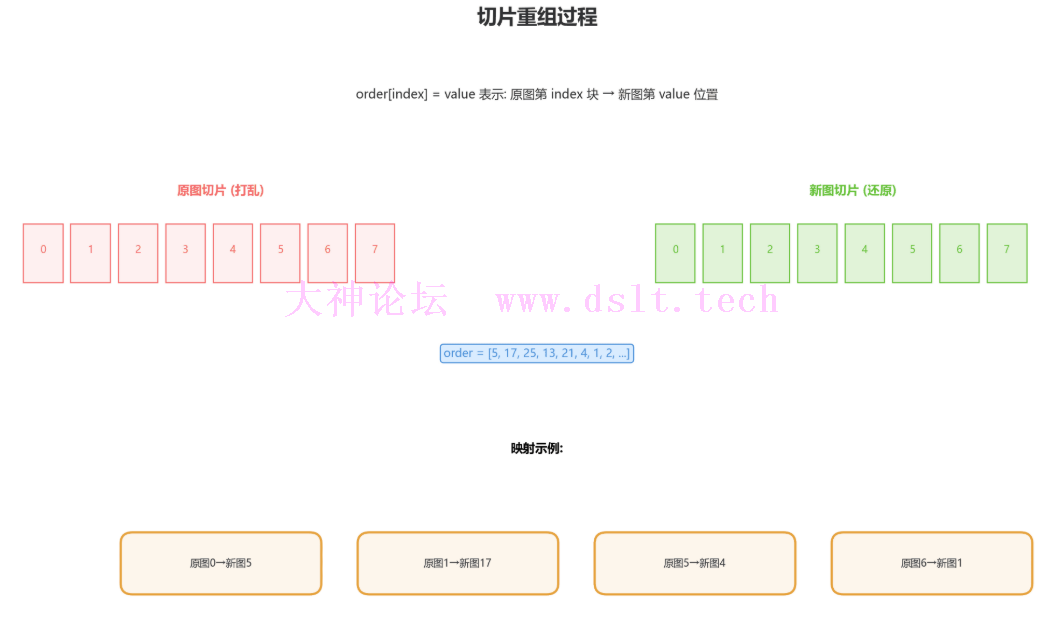
function onloadImg() {
// 设置 canvas 尺寸与图片一致
// _0x55ae6b.width = _0x5080d6.width
// _0x55ae6b.height = _0x5080d6.height
_0x55ae6b.width = _0x5080d6["width"],
_0x55ae6b["height"] = _0x5080d6.height,
// 先将原图绘制到 canvas 上(这一步会被后续的切片重绘覆盖)
_0x81f4b1["drawImage"](_0x5080d6, 0, 0, _0x5080d6.width, _0x5080d6.height);
// 从图片 URL 中提取文件名(不含扩展名)
// 例如:从 "https://xxx/e19m5dab9fo9i8g9hc69lj9n72k04399.png"
// 提取出 "e19m5dab9fo9i8g9hc69lj9n72k04399"
// imgSrc.split("/") 按 "/" 分割
// [length - 1] 取最后一个元素(文件名.png)
// .split(".")[0] 去掉扩展名
const _0x251234 = imgSrc["split"]("/")[_0x18d30b["NfPti"](imgSrc["split"]("/")["length"], 1)]["split"](".")[0];
// 调用解密函数,根据文件名计算切片顺序
// 返回一个长度为 32 的数组,如 [5, 17, 25, 13, 21, 4, 1, 2, ...]
const _0x3e2bfc = decryptImage(_0x251234);
// 计算每个切片的宽度
// 图片宽度 / 切片数量 = 544 / 32 = 17
const _0x519761 = Math.floor(_0x5080d6["width"] / _0x3e2bfc.length);
// 遍历切片顺序数组,重新绘制图片
// 回调参数:_0x5ca950 = 数组的值(目标位置),_0x2f0818 = 索引(源位置)
convertArray(_0x3e2bfc, (_0x5ca950, _0x2f0818) => {
// 计算源切片的 X 坐标
// srcX = index * sliceWidth
const _0x5d28d3 = _0x41d868["POBxg"](_0x2f0818, _0x519761);
// 切片宽度
const _0x5bedd5 = _0x519761;
// 核心绘制操作:
// drawImage(源图片, 源X, 源Y, 源宽, 源高, 目标X, 目标Y, 目标宽, 目标高)
// 从原图的第 index 个位置取切片,放到新图的第 value 个位置
// srcX = _0x2f0818 * _0x519761 (索引 * 切片宽度)
// dstX = _0x5ca950 * _0x519761 (值 * 切片宽度)
_0x81f4b1["drawImage"](
_0x5080d6, // 源图片
_0x5d28d3, 0, // 源起点 (srcX, 0)
_0x5bedd5, _0x5080d6["height"], // 源尺寸 (切片宽度, 图片高度)
_0x5ca950 * _0x519761, 0, // 目标起点 (dstX, 0)
_0x5bedd5, _0x5080d6["height"] // 目标尺寸 (切片宽度, 图片高度)
);
});
// 将还原后的图片导出为 PNG 格式
const buffer = _0x55ae6b.toBuffer('image/png');
// 保存到文件
fs.writeFileSync('restored.png', buffer);
console.log('还原完成: restored.png');
}
// 执行主函数
main();
算法流程图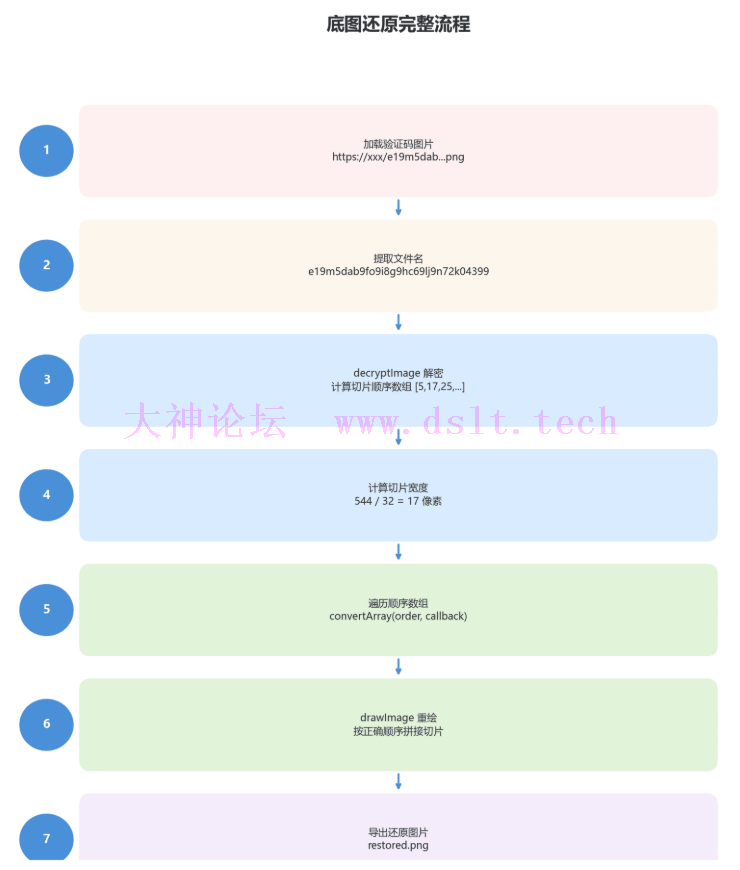
node底图还原遇到了个问题就是,在浏览器环境中,可以通过 img.src = url 来设置图片源,但在 node-canvas 中,loadImage 返回的 Image 对象不支持直接设置 src 属性。用py复现还原底图其实更为方便,后续也是可以转成py的,笔者太懒,不想转换了。 check接口搜索report参数,断点直接断住了 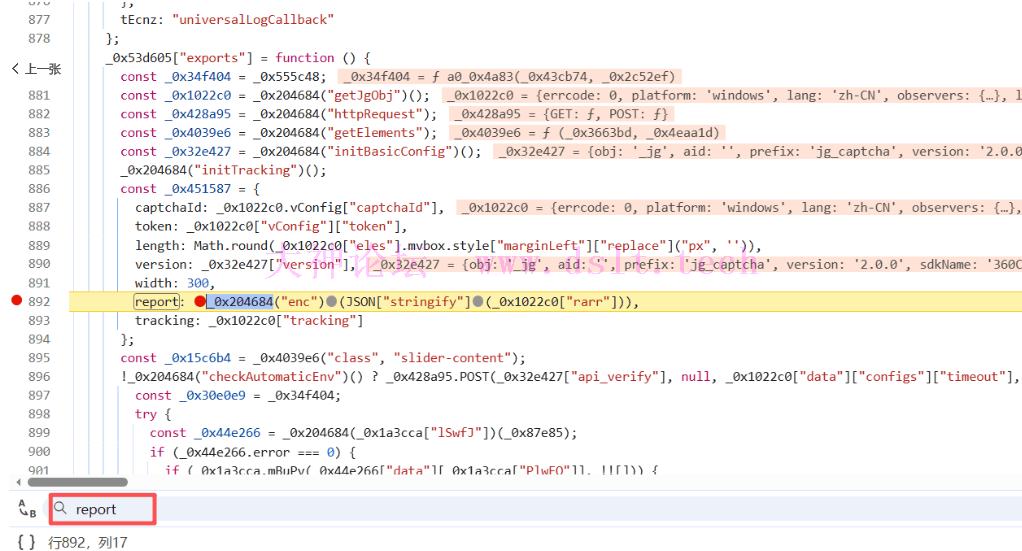
length就是滑块距离,重点分析report,report就是rarr传进enc函数返回的值 全局搜索rarr,分析代码。 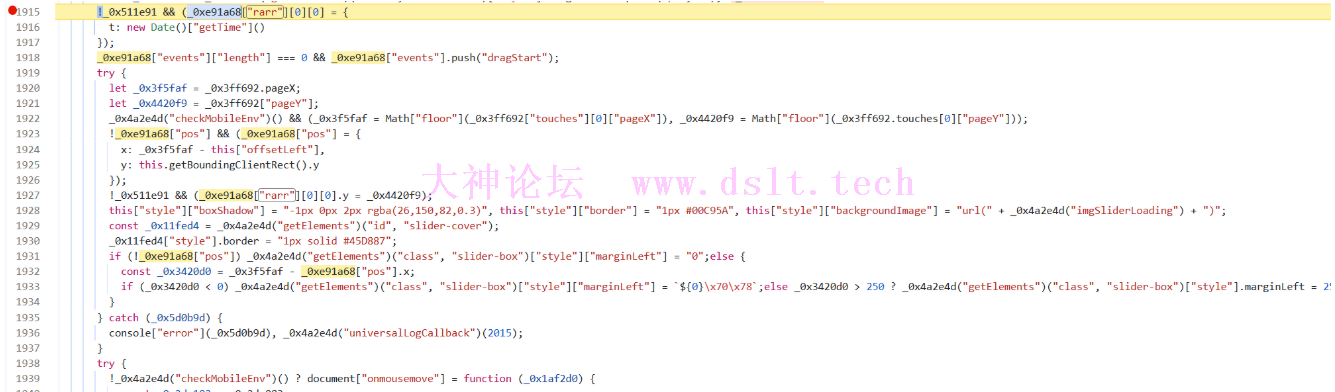
代码就是监听鼠标事件获取轨迹 try {
// 获取鼠标的横坐标 pageX
let _0x3f5faf = _0x3ff692.pageX;
// 获取鼠标的纵坐标 pageY
let _0x4420f9 = _0x3ff692["pageY"];
// 如果在移动端环境,则从 touches[0] 中读取 pageX 和 pageY,并向下取整
_0x4a2e4d("checkMobileEnv")() && (
_0x3f5faf = Math["floor"](_0x3ff692["touches"][0]["pageX"]),
_0x4420f9 = Math["floor"](_0x3ff692.touches[0]["pageY"])
);
// 如果 pos 属性还没有赋值,则赋值为本次事件的起点坐标(减去滑块的左偏移获得鼠标相对于滑块的 X 坐标,Y 坐标用 getBoundingClientRect().y)
!_0xe91a68["pos"] && (_0xe91a68["pos"] = {
x: _0x3f5faf - this["offsetLeft"],
y: this.getBoundingClientRect().y
});
// 如果之前 marginLeft 不存在,则给 rarr[0][0] 对象加上 y 坐标,记录下拖动开始的位置
!_0x511e91 && (_0xe91a68["rarr"][0][0].y = _0x4420f9);
// 给当前拖动对象设置样式:阴影、边框和 loading 背景图
this["style"]["boxShadow"] = "-1px 0px 2px rgba(26,150,82,0.3)";
this["style"]["border"] = "1px #00C95A";
this["style"]["backgroundImage"] = "url(" + _0x4a2e4d("imgSliderLoading") + ")";
// 获取 id 为 "slider-cover" 的元素,并设置其边框颜色
const _0x11fed4 = _0x4a2e4d("getElements")("id", "slider-cover");
_0x11fed4["style"].border = "1px solid #45D887";
// 如果 pos 还没有值,则将 slider-box 的 marginLeft 归零
if (!_0xe91a68["pos"]) {
_0x4a2e4d("getElements")("class", "slider-box")["style"]["marginLeft"] = "0";
} else {
// 计算当前鼠标/手指与初始点击点的横向距离
const _0x3420d0 = _0x3f5faf - _0xe91a68["pos"].x;
// 如果小于 0,则 marginLeft 赋值为 0px(不允许向左拖动)
if (_0x3420d0 < 0) {
_0x4a2e4d("getElements")("class", "slider-box")["style"]["marginLeft"] = `${0}px`;
}
// 如果大于 250,则 marginLeft 赋值为 250px(最大滑动距离)
else if (_0x3420d0 > 250) {
_0x4a2e4d("getElements")("class", "slider-box")["style"].marginLeft = 250 + "px";
}
// 如果是刚刚开始拖动,则 marginLeft 赋值为 0px
else if (_0xe91a68.events[0] === "dragStart") {
_0x4a2e4d("getElements")("class", "slider-box").style["marginLeft"] = 0 + "px";
}
// 否则,将 marginLeft 设置为当前拖动距离
else {
_0x4a2e4d("getElements")("class", "slider-box")["style"].marginLeft = `${_0x3420d0}px`;
}
}
} catch (_0x5d0b9d) {
// 如果 try 里面出错,则打印错误并调用 universalLogCallback 日志上报
console["error"](_0x5d0b9d);
_0x4a2e4d("universalLogCallback")(2015);
}
rarr解决之后直接进入enc函数分析,就是传入轨迹然后跟之前auth接口的返回值进行了各种加密拼接 
对轨迹进行的encryptLong加密经分析就是RSA加密,没有魔改,直接套库就行。 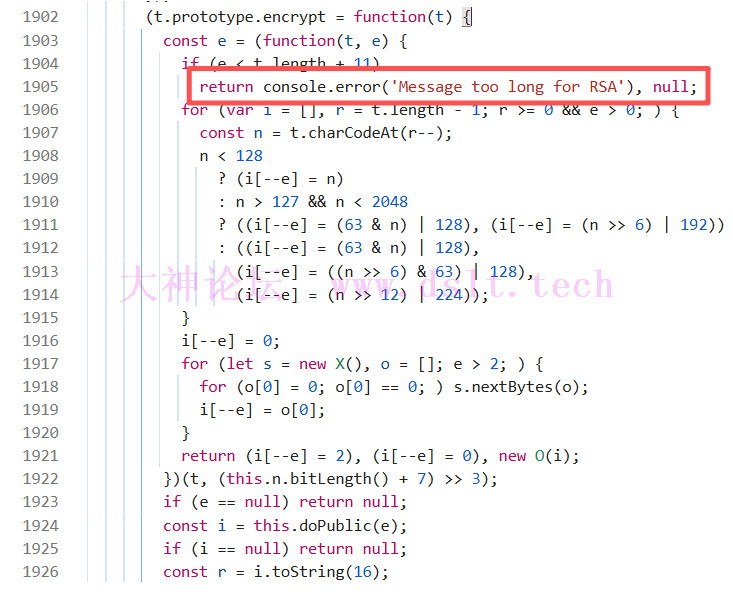
滑块识别代码def detect_slide_distance(bg_url: str, front_url: str) -> int:
"""
使用ddddocr识别滑块缺口位置
Args:
bg_url: 背景图URL
front_url: 滑块图URL
Returns:
滑动距离(px)
"""
# 下载图片
bg_image = requests.get(bg_url).content
front_image = requests.get(front_url).content
det = ddddocr.DdddOcr(det=False, ocr=False,show_ad=False)
result = det.slide_match(front_image, bg_image, simple_target=True)
return result['target'][0]
轨迹模拟代码轨迹代码只做参考,兄弟们可以去研究一下其他的轨迹,他这个就一个轨迹进行了加密,有可能对轨迹校验比较严格。 def generate_human_track(distance: int, start_y: int = 200, overshoot: bool = True) -> list:
"""
生成拟人轨迹
Args:
distance: 滑动距离(px)
start_y: 起始Y坐标
overshoot: 是否过冲
Returns:
轨迹列表 [{"0": {"t": timestamp, "y": y}}, ...]
"""
track = []
current_x = 0
current_y = start_y
start_time = int(time.time() * 1000)
current_time = start_time
overshoot_distance = random.uniform(3, 8) if overshoot else 0
target = distance + overshoot_distance
velocity = 0
# 起始点
track.append({"0": {"t": current_time, "y": current_y}})
# 前进阶段
while current_x < target:
if current_x < distance * 0.7:
acceleration = random.uniform(1.5, 3)
else:
acceleration = random.uniform(-1, 0.5)
velocity = max(0.5, velocity + acceleration * 0.1)
velocity = min(velocity, 15)
step = velocity * random.uniform(0.8, 1.2)
step = min(step, target - current_x)
current_x += step
current_y += random.uniform(-1.5, 1.5)
current_time += random.randint(10, 20)
track.append({str(len(track)): {"t": current_time, "y": round(current_y, 2)}})
# 回调阶段
if overshoot and current_x > distance:
while current_x > distance:
step = random.uniform(0.5, 2)
step = min(step, current_x - distance)
current_x -= step
current_y += random.uniform(-0.3, 0.3)
current_time += random.randint(20, 40)
track.append({str(len(track)): {"t": current_time, "y": round(current_y, 2)}})
return track
识别结果: 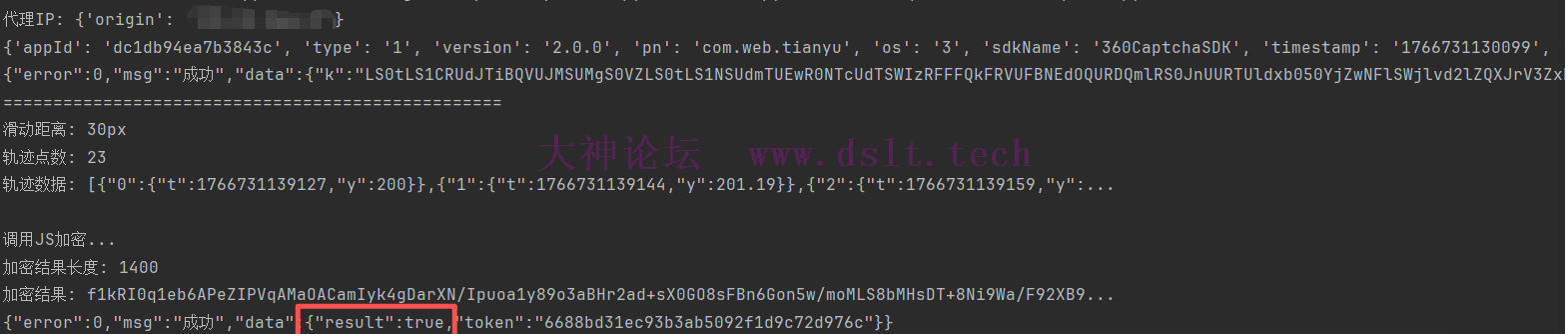
感觉成功率有点低哈,目前还不晓得问题出在哪里,可能是轨迹问题,也有可能还有风控吧(俺没找到),也没有说一定要上并发,毕竟只是练习题,练习练习能出值就行了。 结尾思考ing...
注:若转载请注明大神论坛来源(本贴地址)与作者信息。
|


 发表于 2025-12-29 22:52
发表于 2025-12-29 22:52





 评分
评分 顶
顶 踩
踩 扫码赞助
扫码赞助