本帖最后由 kay2kay 于 2021-03-14 23:27 编辑
本文为本人的滴水逆向破解脱壳学习笔记之一,为本人对以往所学的回顾和总结,可能会有谬误之处,欢迎大家指出。
陆续将不断有笔记放出,希望能对想要入门的萌新有所帮助,一起进步
所有笔记链接:
大神论坛 逆向脱壳分析基础学习笔记一 进制篇
大神论坛 逆向脱壳分析基础学习笔记二 数据宽度和逻辑运算
大神论坛 逆向脱壳分析基础学习笔记三 通用寄存器和内存读写
大神论坛 逆向脱壳分析基础学习笔记四 堆栈篇
大神论坛 逆向脱壳分析基础学习笔记五 标志寄存器
大神论坛 逆向脱壳分析基础学习笔记六 汇编跳转和比较指令
大神论坛 逆向脱壳分析基础学习笔记七 堆栈图(重点)(需登录才能访问)
大神论坛 逆向脱壳分析基础学习笔记八 反汇编分析C语言
大神论坛 逆向脱壳分析基础学习笔记九 C语言内联汇编和调用协定
大神论坛 逆向脱壳分析基础学习笔记十 汇编寻找C程序入口(需登录才能访问)
大神论坛 逆向脱壳分析基础学习笔记十一 汇编C语言基本类型
大神论坛 逆向脱壳分析基础学习笔记十二 汇编 全局和局部 变量(需登录才能访问)
大神论坛 逆向脱壳分析基础学习笔记十三 汇编C语言类型转换(需登录才能访问)
大神论坛 逆向脱壳分析基础学习笔记十四 汇编嵌套if else(需登录才能访问)
大神论坛 逆向脱壳分析基础学习笔记十五 汇编比较三种循环(需登录才能访问)
大神论坛 逆向脱壳分析基础学习笔记十六 汇编一维数组(需登录才能访问)
大神论坛 逆向脱壳分析基础学习笔记十七 汇编二维数组 位移 乘法(需登录才能访问)
大神论坛 逆向脱壳分析基础学习笔记十八 汇编 结构体和内存对齐(需登录才能访问)
大神论坛 逆向脱壳分析基础学习笔记十九 汇编switch比较if else(需登录才能访问)
大神论坛 逆向脱壳分析基础学习笔记二十 汇编 指针(一)(需登录才能访问)
大神论坛 逆向脱壳分析基础学习笔记二十一 汇编 指针(二)(需登录才能访问)
大神论坛 逆向脱壳分析基础学习笔记二十二 汇编 指针(三)(需登录才能访问)
大神论坛 逆向脱壳分析基础学习笔记二十三 汇编 指针(四)(需登录才能访问)
大神论坛 逆向脱壳分析基础学习笔记二十四 汇编 指针(五) 系列完结(需登录才能访问) 更多逆向脱壳资源,请访问 大神论坛Switch语句先前在逆向基础笔记十四 汇编嵌套if else中讲了分支结构的if else形式,除此之外还有一种分支结构:switch 此次就来以反汇编的角度研究switch语句,并与if else进行比较
Switch语句的使用有关Switch语句在vc++6.0中生成的反汇编可分为4种情况,这4种情况的区分在于case的不同 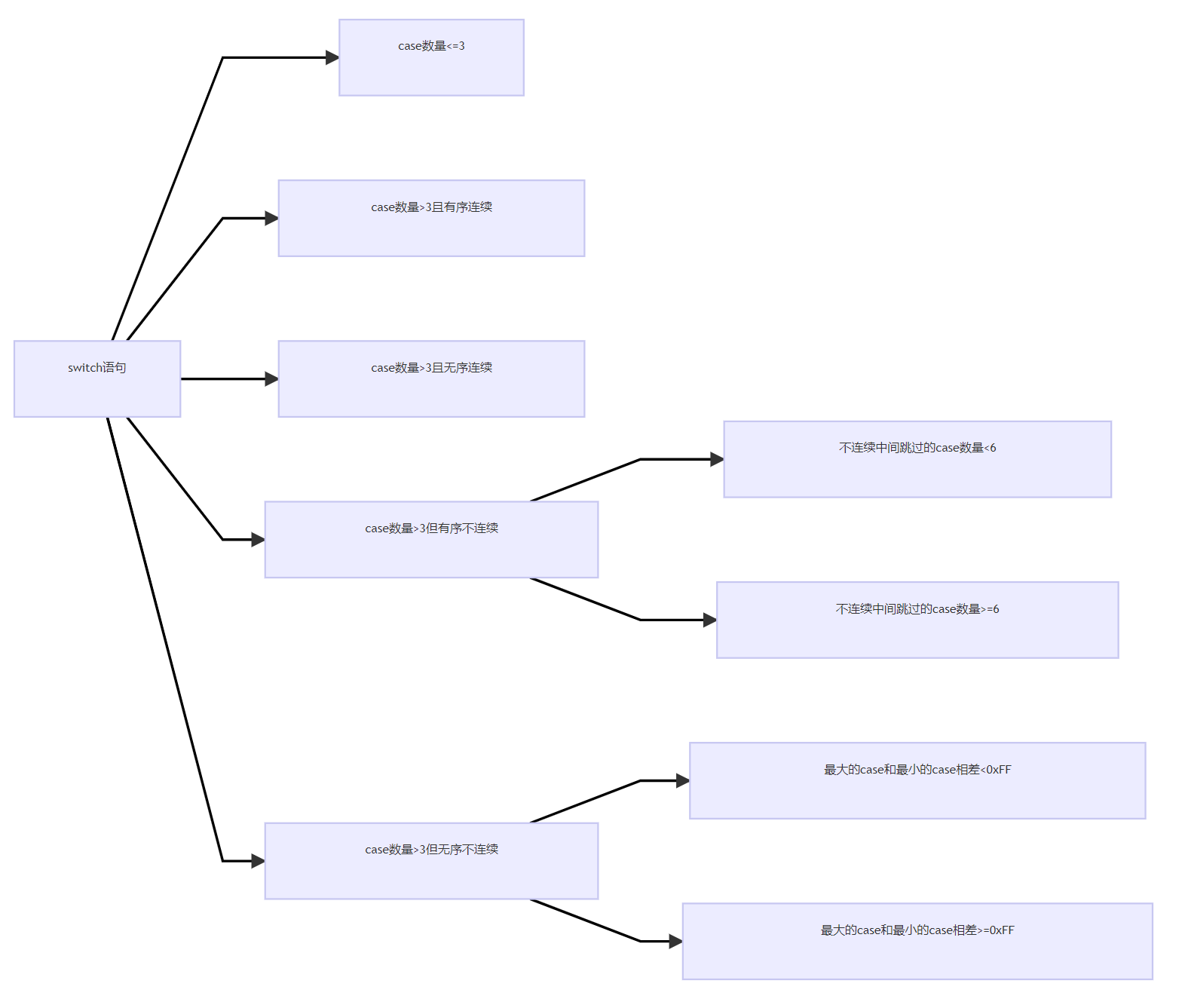
case数量<=3代码#include "stdafx.h"
void MySwitch(int x){
switch(x) {
case 1:
printf("num is 1\n");
break;
case 2:
printf("num is 2\n");
break;
case 3:
printf("num is 3\n");
break;
default:
printf("no cases match\n");
break;
}
}
int main(int argc, char* argv[])
{
MySwitch(2);
return 0;
}
switch(表达式)中,表达式应该为整数类型:char short int long,其它类型诸如:float、double等类型均不可以 switch搭配case使用,case里如果没有添加break语句则会继续向下执行下面的case default语句可以没有,如果所有case都不匹配会默认执行default语句
上面的代码为,判断参数是否为1或2或3,如果是则输出对应语句 运行结果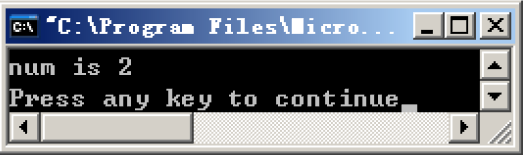
能够正确判断出所给参数为2
反汇编代码10: switch(x) {
0040D7A8 mov eax,dword ptr [ebp+8]
0040D7AB mov dword ptr [ebp-4],eax
0040D7AE cmp dword ptr [ebp-4],1
0040D7B2 je MySwitch+32h (0040d7c2)
0040D7B4 cmp dword ptr [ebp-4],2
0040D7B8 je MySwitch+41h (0040d7d1)
0040D7BA cmp dword ptr [ebp-4],3
0040D7BE je MySwitch+50h (0040d7e0)
0040D7C0 jmp MySwitch+5Fh (0040d7ef)
11: case 1:
12: printf("num is 1\n");
0040D7C2 push offset string "num is 1\n" (00422fc4)
0040D7C7 call printf (00401060)
0040D7CC add esp,4
13: break;
0040D7CF jmp MySwitch+6Ch (0040d7fc)
14: case 2:
15: printf("num is 2\n");
0040D7D1 push offset string "num is 2\n" (00422fb8)
0040D7D6 call printf (00401060)
0040D7DB add esp,4
16: break;
0040D7DE jmp MySwitch+6Ch (0040d7fc)
17: case 3:
18: printf("num is 3\n");
0040D7E0 push offset string "num is 3\n" (00422fac)
0040D7E5 call printf (00401060)
0040D7EA add esp,4
19: break;
0040D7ED jmp MySwitch+6Ch (0040d7fc)
20: default:
21: printf("no cases match\n");
0040D7EF push offset string "Hello World!\n" (0042201c)
0040D7F4 call printf (00401060)
0040D7F9 add esp,4
22: break;
23: }
24: }
反汇编分析1.反汇编代码为将参数x的值赋给eax 0040D7A8 mov eax,dword ptr [ebp+8]
2.将eax的值放入堆栈中 0040D7AB mov dword ptr [ebp-4],eax
3.将前面放入堆栈中的eax拿出来和第1个case中的条件进行比较(也就是比较参数x和case) 0040D7AE cmp dword ptr [ebp-4],1
4.判断是否要跳转,je:jump equal,前面比较的两个数相同则跳转,跳转的地址为case 1对应的地址 0040D7B2 je MySwitch+32h (0040d7c2)
5.如果没有跳转则继续将参数和第2个case中的条件进行比较 0040D7B4 cmp dword ptr [ebp-4],2
6.依旧是根据比较的结果判断是否要跳转,跳转的地址为case 2对应的地址 0040D7B8 je MySwitch+41h (0040d7d1)
7.如果没有跳转则继续将参数和第3个case中的条件进行比较 0040D7BA cmp dword ptr [ebp-4],3
8.依旧是根据比较的结果判断是否要跳转,跳转的地址为case 3对应的地址 0040D7BE je MySwitch+50h (0040d7e0)
9.如果没有跳转则绝对跳转到default: 0040D7C0 jmp MySwitch+5Fh (0040d7ef)
default: 20: default:
21: printf("no cases match\n");
0040D7EF push offset string "Hello World!\n" (0042201c)
0040D7F4 call printf (00401060)
0040D7F9 add esp,4
22: break;
下面的内容就是 case 1,case 2,case 3了 可以注意到,case里面的break都对应为跳出switch,而default里的break因为下面就已经是退出switch所以没有生成对应的汇编代码 case1里的break 13: break;
0040D7CF jmp MySwitch+6Ch (0040d7fc)
case2里的break 16: break;
0040D7DE jmp MySwitch+6Ch (0040d7fc)
case3里的break 19: break;
0040D7ED jmp MySwitch+6Ch (0040d7fc)
小总结通过上面的分析,发现此时(switch 中的case数量≤3时)的反汇编代码和if else并无本质上的区别,都是要依次比较判断条件 此时的流程图为: 
前面的switch case中 case的数量只有3个,看起来和if else并无太大区别,接下来看看当case数量大于3时的情况 case数量>3且有序连续代码void MySwitch(int x){
switch(x) {
case 1:
printf("num is 1\n");
break;
case 2:
printf("num is 2\n");
break;
case 3:
printf("num is 3\n");
break;
case 4:
printf("num is 4\n");
break;
default:
printf("no cases match\n");
break;
}
}
代码并没有太大的改动,只是简单得为上面的代码再添加一个case 4的情形即可,运行结果自然没有变化,也就不再贴出
反汇编代码10: switch(x) {
0040D7A8 mov eax,dword ptr [ebp+8]
0040D7AB mov dword ptr [ebp-4],eax
0040D7AE mov ecx,dword ptr [ebp-4]
0040D7B1 sub ecx,1
0040D7B4 mov dword ptr [ebp-4],ecx
0040D7B7 cmp dword ptr [ebp-4],3
0040D7BB ja $L539+0Fh (0040d803)
0040D7BD mov edx,dword ptr [ebp-4]
0040D7C0 jmp dword ptr [edx*4+40D821h]
11: case 1:
12: printf("num is 1\n");
0040D7C7 push offset string "num is 1\n" (00422fd0)
0040D7CC call printf (00401060)
0040D7D1 add esp,4
13: break;
0040D7D4 jmp $L539+1Ch (0040d810)
14: case 2:
15: printf("num is 2\n");
0040D7D6 push offset string "num is 2\n" (00422fc4)
0040D7DB call printf (00401060)
0040D7E0 add esp,4
16: break;
0040D7E3 jmp $L539+1Ch (0040d810)
17: case 3:
18: printf("num is 3\n");
0040D7E5 push offset string "num is 3\n" (00422fb8)
0040D7EA call printf (00401060)
0040D7EF add esp,4
19: break;
0040D7F2 jmp $L539+1Ch (0040d810)
20: case 4:
21: printf("num is 4\n");
0040D7F4 push offset string "num is 4\n" (00422fac)
0040D7F9 call printf (00401060)
0040D7FE add esp,4
22: break;
0040D801 jmp $L539+1Ch (0040d810)
23: default:
24: printf("no cases match\n");
0040D803 push offset string "Hello World!\n" (0042201c)
0040D808 call printf (00401060)
0040D80D add esp,4
25: break;
26: }
27: }
很明显地观察到先前开头的一串比较语句不见了,接下来开始分析 反汇编分析1.头两条语句和先前没有什么不同,都是将参数x赋值给eax,然后将eax保存到堆栈中;总得来看就是把参数先保存到堆栈里 0040D7A8 mov eax,dword ptr [ebp+8]
0040D7AB mov dword ptr [ebp-4],eax
2.第三条语句就开始和之前不同了,这里是将前面保存到堆栈里的参数x再赋值给ecx 0040D7AE mov ecx,dword ptr [ebp-4]
3.这里将ecx减少1 为什么要减1?是为了后面的比较,后面会说明 为什么减的是1?要注意到这里减的1实则是case中的最小值,在此次案例中就是min{1,2,3,4}=1 0040D7B1 sub ecx,1
4.将前面的ecx,也就是参数x-1的值覆盖前面保存的参数 0040D7B4 mov dword ptr [ebp-4],ecx
5.将参数x-1的值和3进行比较 0040D7B7 cmp dword ptr [ebp-4],3
6.ja指令:jump above,大于时跳转(无符号),也就是比较参数x-1和3(case中的最大差值),最大差值就是最大值减最小值,此案例中就是4-1=3 如果x-1>3则跳转,如果前面参数没有减1的话,就变成了直接判断x>3,如果此时x=4也会产生跳转,不符合程序的逻辑(原本x=4应该对应跳转到case 4) 注意到这里采用的是无符号比较,而不采用有符号比较指令jg:jump greater,大于时跳转(有符号),为什么? 这里的比较代码其实就是判断参数是否在(case中的最小值,case中的最大值)这个区间内 当参数小于case中的最小值时,前面的sub ecx,case中的最小值就后就会产生下溢,此时将其看作无符号数就会相当大,一定会大于case中的最大差值,举个简单的例子,假如此时的参数为0,0-1 = -1对应的是十六进制为FFFF FFFF,将其看作无符号数就是4294967295 0040D7BB ja $L539+0Fh (0040d803)
跳转的地址为:0040d803,对应为default的地址 23: default:
24: printf("no cases match\n");
0040D803 push offset string "Hello World!\n" (0042201c)
0040D808 call printf (00401060)
0040D80D add esp,4
25: break;
7.如果前面没有跳转,这里则又将前面保存的参数-1的值取了出来,并赋值给edx 0040D7BD mov edx,dword ptr [ebp-4]
8.这条语句就是拉开与if else性能的关键,绝对跳转语句 0040D7C0 jmp dword ptr [edx*4+40D821h]
先不看语句中的edx*4,先看看40D821h里存储的内容是什么 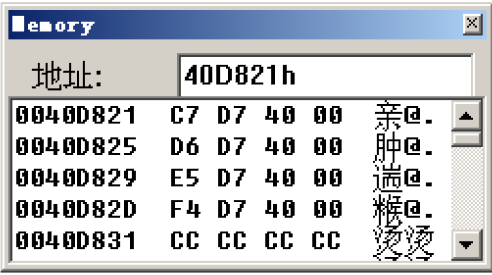
可以观察到从这个地址开始,依次存储了四个地址: | 地址 | 地址里存储的内容 | 存储内容对应地址含义 | 对应偏移 |
|---|
| 0040D821 | 0040D7C7 | case 1的首地址 | 0 | | 0040D821+4=0040D825 | 0040D825 | case 2的首地址 | 1*4 | | 0040D821+8=0040D829 | 0040D829 | case 3的首地址 | 2*4 | | 0040D821+12=0040D82D | 0040D82D | case 4的首地址 | 3*4 |
可以将这里的40D821h看作一个表的首地址,这个表中存储了各个case对应的地址,并且每个地址之前的间距为4
现在结合前面的edx*4就不难判断出这里是通过jmp [存储case地址表的首地址+偏移×4]来跳转到对应的case,因此也减少了cmp的比较次数,提高了效率;这里就要说明前面将参数减1的真正原因了,当x为1时对应的case1首地址的偏移为0,所以需要让edx=x-1=0才能准确跳转到对应的位置,所以将参数减1是为了配合偏移寻址
剩下对应case的代码和上面并没有什么区别,就不再赘述 小总结通过上面的分析,发现此时(switch 中的case数量>3时)的反汇编代码和if else的差别就体现出来了 有一点要重点强调的是这里关于switch中case数量>3中的这个3只针对当前使用的vc++6.0编译器,不同的编译器对于switch产生的汇编指令可能不大相同,但到达一定条件后一般都会采用到case地址表首地址+偏移的方法 此时是将参数的值减case中的最小值,然后判断这个减完的数值是否大于case中的最大差值 如果大于则直接跳转到default 如果小于或等于则通过jmp [存储case地址表的首地址+偏移×4]的方式直接跳转到对应case的地址,而不再像if else中那样依次比较来判断是否要跳转 此时的流程图为: 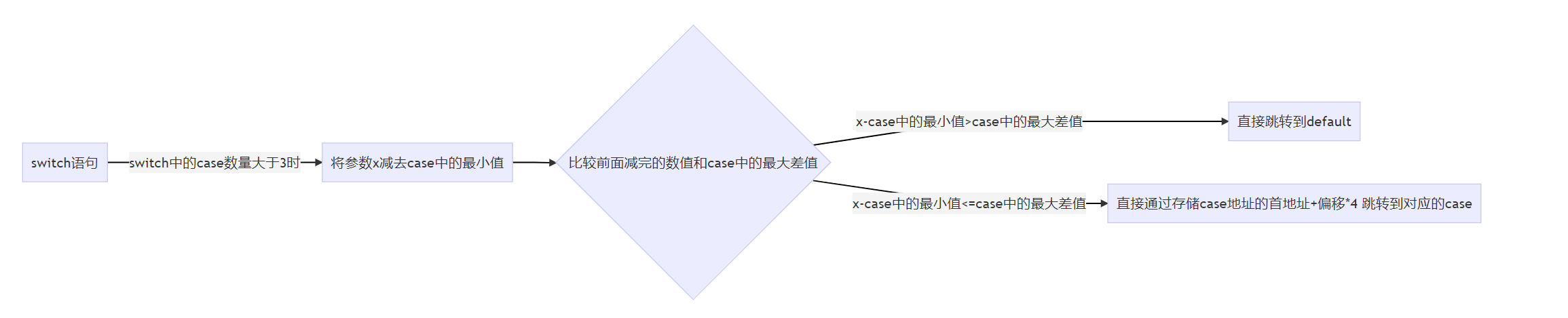
case数量>3且无序连续前面的代码中,case是按照1、2、3、4有序下来的,如果将1、2、3、4改为2、3、4、1或其他连续但顺序不同的情况时会如何? 下面以2、3、4、1为例进行分析 代码switch(x) {
case 2:
printf("num is 2\n");
break;
case 3:
printf("num is 3\n");
break;
case 4:
printf("num is 4\n");
break;
case 1:
printf("num is 1\n");
break;
default:
printf("no cases match\n");
break;
}
简单地调换了一下case语句的顺序,观察其反汇编 反汇编代码10: switch(x) {
0040D7A8 mov eax,dword ptr [ebp+8]
0040D7AB mov dword ptr [ebp-4],eax
0040D7AE mov ecx,dword ptr [ebp-4]
0040D7B1 sub ecx,1
0040D7B4 mov dword ptr [ebp-4],ecx
0040D7B7 cmp dword ptr [ebp-4],3
0040D7BB ja $L539+0Fh (0040d803)
0040D7BD mov edx,dword ptr [ebp-4]
0040D7C0 jmp dword ptr [edx*4+40D821h]
11: case 2:
12: printf("num is 2\n");
0040D7C7 push offset string "num is 1\n" (00422fd0)
0040D7CC call printf (00401060)
0040D7D1 add esp,4
13: break;
0040D7D4 jmp $L539+1Ch (0040d810)
14: case 3:
15: printf("num is 3\n");
0040D7D6 push offset string "num is 2\n" (00422fc4)
0040D7DB call printf (00401060)
0040D7E0 add esp,4
16: break;
0040D7E3 jmp $L539+1Ch (0040d810)
17: case 4:
18: printf("num is 4\n");
0040D7E5 push offset string "num is 3\n" (00422fb8)
0040D7EA call printf (00401060)
0040D7EF add esp,4
19: break;
0040D7F2 jmp $L539+1Ch (0040d810)
20: case 1:
21: printf("num is 1\n");
0040D7F4 push offset string "num is 271\n" (00422fac)
0040D7F9 call printf (00401060)
0040D7FE add esp,4
22: break;
0040D801 jmp $L539+1Ch (0040d810)
23: default:
24: printf("no cases match\n");
0040D803 push offset string "no cases match\n" (0042201c)
0040D808 call printf (00401060)
0040D80D add esp,4
25: break;
26: }
27: }
反汇编分析10: switch(x) {
0040D7A8 mov eax,dword ptr [ebp+8]
0040D7AB mov dword ptr [ebp-4],eax
0040D7AE mov ecx,dword ptr [ebp-4]
0040D7B1 sub ecx,1
0040D7B4 mov dword ptr [ebp-4],ecx
0040D7B7 cmp dword ptr [ebp-4],3
0040D7BB ja $L539+0Fh (0040d803)
0040D7BD mov edx,dword ptr [ebp-4]
0040D7C0 jmp dword ptr [edx*4+40D821h]
将这里的反汇编代码与先前的反汇编代码进行对比,发现并没有差别,也就是说当case连续时顺序并不影响其反汇编代码的生成结果 case数量>3但有序不连续因为前面的案例中case的特点为都为连续(都是从1到4)中间没有间隔其它数字,现在来个讲讲不连续的例子 这里将原本的1~4改为1~10,并且在中间跳过一个case 5,使其不连续 注意此时只跳过了一个case,属于跳过数较少的情况 代码switch(x) {
case 1:
printf("num is 1\n");
break;
case 2:
printf("num is 2\n");
break;
case 3:
printf("num is 3\n");
break;
case 4:
printf("num is 4\n");
break;
//这里少了case 5
case 6:
printf("num is 6\n");
break;
case 7:
printf("num is 7\n");
break;
case 8:
printf("num is 8\n");
break;
case 9:
printf("num is 9\n");
break;
case 10:
printf("num is 10\n");
break;
default:
printf("no cases match\n");
break;
}
反汇编代码因为后面case的代码和之前并无不同,所以这里只给出了前面的关键语句 10: switch(x) {
0040D7A8 mov eax,dword ptr [ebp+8]
0040D7AB mov dword ptr [ebp-4],eax
0040D7AE mov ecx,dword ptr [ebp-4]
0040D7B1 sub ecx,1
0040D7B4 mov dword ptr [ebp-4],ecx
0040D7B7 cmp dword ptr [ebp-4],9
0040D7BB ja $L549+0Fh (0040d855)
0040D7C1 mov edx,dword ptr [ebp-4]
0040D7C4 jmp dword ptr [edx*4+40D873h]
省略了中间的case的代码
0040D853 jmp $L549+1Ch (0040d862)
38: default:
39: printf("no cases match\n");
0040D855 push offset string "Hello World!\n" (0042201c)
0040D85A call printf (00401060)
0040D85F add esp,4
40: break;
41: }
42: }
反汇编分析可以看到此时的代码依旧符合先前的小总结,但是这里就有了个问题,在case地址表中对应的空缺的case 5里存储的是什么? 这里的case地址表首地址为40D873h 0040D7C4 jmp dword ptr [edx*4+40D873h]
查看40D873h中存储的内容: 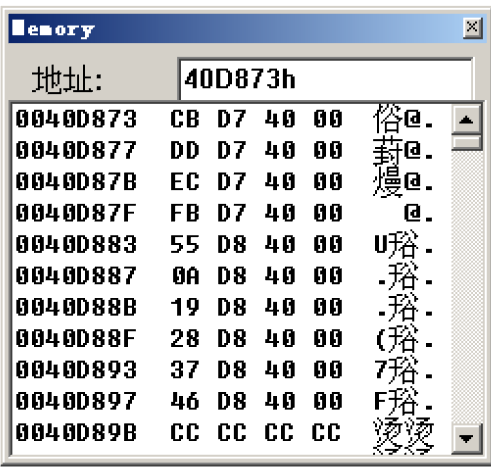
可以看到从地址表开始连续存储了10个case对应的地址,和代码中的case数相匹配 按顺序找下来,查看对应case 5的地址存储的是什么: 对应的地址为40D873+4(5-1)=40D883,这里的计算是根据上面的edx\4+40D873h所得 0040D883这个地址里存储的数据是0040D855 而0040D855这个地址对应的则是default的地址 38: default:
39: printf("no cases match\n");
0040D855 push offset string "Hello World!\n" (0042201c)
小总结当case有序,但中间跳过了较少的case情况时,依旧会按照前面有序连续的模式进行处理,只不过期间会浪费缺少的case的空间,这些被浪费的空间会被default的地址填充,即被跳过的case在case地址表中的地址会被设置为default的地址
代码二前面的例子是只跳过了一个case的情况,于是也只浪费了一个case的空间,那么当跳过了很多case的情况下,也就意味着会浪费很多的空间,但是实际上,编译器并没有那么愚蠢,当跳过的case超过了一定限度,或者说是浪费的空间到达一定的限度后,就会采取另一种方式生成对应的反汇编代码 修改前面的代码,跳过3、4、5、6、7、8,共6个case switch(x) {
case 1:
printf("num is 1\n");
break;
case 2:
printf("num is 2\n");
break;
//这里跳过了3、4、5、6、7、8,共6个case
case 9:
printf("num is 9\n");
break;
case 10:
printf("num is 10\n");
break;
default:
printf("no cases match\n");
break;
}
反汇编代码二10: switch(x) {
0040D7A8 mov eax,dword ptr [ebp+8]
0040D7AB mov dword ptr [ebp-4],eax
0040D7AE mov ecx,dword ptr [ebp-4]
0040D7B1 sub ecx,1
0040D7B4 mov dword ptr [ebp-4],ecx
0040D7B7 cmp dword ptr [ebp-4],9
0040D7BB ja $L539+0Fh (0040d80b)
0040D7BD mov eax,dword ptr [ebp-4]
0040D7C0 xor edx,edx
0040D7C2 mov dl,byte ptr (0040d83d)[eax]
0040D7C8 jmp dword ptr [edx*4+40D829h]
省略了中间case的代码
27: printf("no cases match\n");
0040D80B push offset string "Hello World!\n" (0042201c)
0040D810 call printf (00401060)
0040D815 add esp,4
28: break;
29: }
30: }
反汇编分析二前面的反汇编代码与先前一致,不同之处在于判断完参数x是否在(case中的最小值,case中的最大值)这个区间内后 0040D7BD mov eax,dword ptr [ebp-4]
0040D7C0 xor edx,edx
0040D7C2 mov dl,byte ptr (0040d83d)[eax]
0040D7C8 jmp dword ptr [edx*4+40D829h]
1.首先是将先前参数x-1的值赋值给eax 0040D7BD mov eax,dword ptr [ebp-4]
2.然后是将edx清零 0040D7C0 xor edx,edx
3.接下来这句就比较关键了,是将0040d83d+eax对应地址里的内容取出byte赋值给dl 0040D7C2 mov dl,byte ptr (0040d83d)[eax]
这里的语句貌似不符合汇编代码的规范,实际上是VC6的编译器为了方便我们查看所生成的 实际的代码对应为: mov dl,byte ptr ds:[eax+0040d83d]
这个形式是不是似曾相识,都是一个地址+偏移来取得数据 这里就要引入第二个表的概念了,先前的那个表是用来存储所有case所对应的地址的,可以将其称之为大表 这里的第二个表可以将其称为小表,来查看小表中存储的数据: 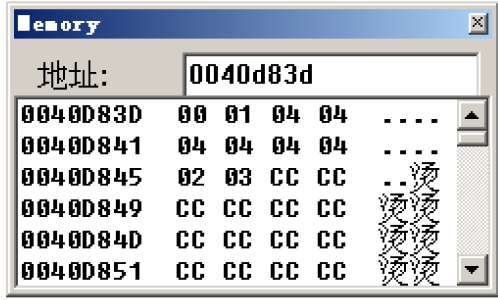
因为前面对应的代码为mov dl,byte ptr .... 所以这里的每项的长度为byte:8字节对应2个十六进制数,在图中就是对应每一小格 可以观察到图中共有10格是有数值的(不为CC),正好对应case的1~10 并且可以观察到从第三格开始一直到第八格存储的数字都是04(对应了跳过的case) | 地址 | 数据 | 含义 |
|---|
| 0040D83D | 00 | case1对应偏移 | | 0040D83D+1=0040D83E | 01 | case2对应偏移 | | 0040D83D+2~0040D83D+7即0040D83F~0040D844 | 04 | default对应偏移 | | 0040D83D+8=0040D845 | 02 | case9对应偏移 | | 0040D83D+9=0040D846 | 03 | case10对应偏移 |
看到这里想必就明白了这个表的作用:存储每个case对应的偏移,每个偏移的宽度为byte,也就是最大为FF
4.这里和先前一样,通过存储case地址表的首地址+偏移×4(查询大表)来跳转到对应的case地址,不同之处在于偏移是从小表中取出的 0040D7C8 jmp dword ptr [edx*4+40D829h]
此时再观察大表中的内容: 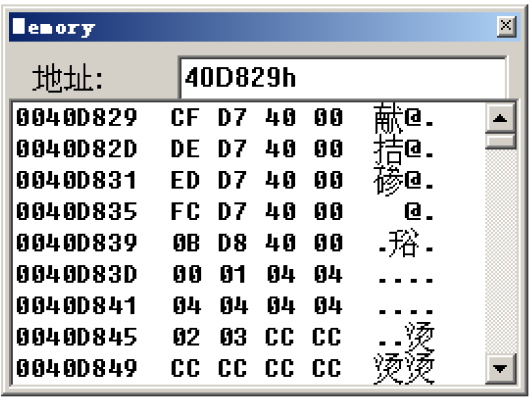
可以发现大表中只存储了5个地址: | 地址 | 地址里存储的内容 | 存储内容对应地址含义 | 对应偏移 |
|---|
| 0040D829 | 0040D7CF | case 1的首地址 | 0 | | 0040D829+4=0040D82D | 0040D7DE | case 2的首地址 | 1*4 | | 0040D829+8=0040D831 | 0040D7ED | case 9的首地址 | 2*4 | | 0040D829+12=0040D835 | 0040D7FC | case 10的首地址 | 3*4 | | 0040D829+16=0040D839 | 0040D80B | default的首地址 | 4*4 |
并且会发现,大表(case地址表)之后紧跟着的就是小表(偏移表)
小总结二当case有序,但中间跳过了较多的case时,就会再使用一个小表(偏移表)来存储偏移以达到节省空间的目的,(每个偏移只占1个字节,但如果直接存储地址的话则要占用4个字节) 此时的流程图为: 
case数量>3但无序不连续前面的代码中是按照1、2、9、10有序地下来,将顺序打乱后再观察: 代码switch(x) {
case 9:
printf("num is 9\n");
break;
case 1:
printf("num is 1\n");
break;
case 10:
printf("num is 10\n");
break;
case 2:
printf("num is 2\n");
break;
default:
printf("no cases match\n");
break;
}
反汇编代码10: switch(x) {
0040D7A8 mov eax,dword ptr [ebp+8]
0040D7AB mov dword ptr [ebp-4],eax
0040D7AE mov ecx,dword ptr [ebp-4]
0040D7B1 sub ecx,1
0040D7B4 mov dword ptr [ebp-4],ecx
0040D7B7 cmp dword ptr [ebp-4],9
0040D7BB ja $L539+0Fh (0040d80b)
0040D7BD mov eax,dword ptr [ebp-4]
0040D7C0 xor edx,edx
0040D7C2 mov dl,byte ptr (0040d83d)[eax]
0040D7C8 jmp dword ptr [edx*4+40D829h]
省略了中间case的代码
24: default:
25: printf("no cases match\n");
0040D80B push offset string "Hello World!\n" (0042201c)
0040D810 call printf (00401060)
0040D815 add esp,4
26: break;
27: }
28: }
反汇编分析可以看到,和先前有序的代码并无差别,也就是说当case不连续时顺序也并不影响其反汇编代码的生成结果
代码二前面会注意到偏移表中最大取值为FF,也就是说最大偏移至多不能超过FF,同时也表明case中的最大差值不能超过FF 那么当最大差值为FF时反汇编代码又会如何? 修改原本case中的最大值10为256,使其最大差值正好为255,对应十六进制为FF switch(x) {
case 9:
printf("num is 9\n");
break;
case 1:
printf("num is 1\n");
break;
case 256:
printf("num is 256\n");
break;
case 2:
printf("num is 2\n");
break;
default:
printf("no cases match\n");
break;
}
反汇编代码二10: switch(x) {
0040D7A8 mov eax,dword ptr [ebp+8]
0040D7AB mov dword ptr [ebp-4],eax
0040D7AE cmp dword ptr [ebp-4],9
0040D7B2 jg MySwitch+38h (0040d7c8)
0040D7B4 cmp dword ptr [ebp-4],9
0040D7B8 je MySwitch+43h (0040d7d3)
0040D7BA cmp dword ptr [ebp-4],1
0040D7BE je MySwitch+52h (0040d7e2)
0040D7C0 cmp dword ptr [ebp-4],2
0040D7C4 je MySwitch+70h (0040d800)
0040D7C6 jmp MySwitch+7Fh (0040d80f)
0040D7C8 cmp dword ptr [ebp-4],100h
0040D7CF je MySwitch+61h (0040d7f1)
0040D7D1 jmp MySwitch+7Fh (0040d80f)
反汇编分析二这里不难看出,此时的情形和case数量<=3的情况一样,都是采用了多次判断跳转,和if else本质并无差别
反汇编对比如果将前面的case 256改为case 255,则反汇编代码又为: 10: switch(x) {
0040D7A8 mov eax,dword ptr [ebp+8]
0040D7AB mov dword ptr [ebp-4],eax
0040D7AE mov ecx,dword ptr [ebp-4]
0040D7B1 sub ecx,1
0040D7B4 mov dword ptr [ebp-4],ecx
0040D7B7 cmp dword ptr [ebp-4],0FEh
0040D7BE ja $L539+0Fh (0040d80e)
0040D7C0 mov eax,dword ptr [ebp-4]
0040D7C3 xor edx,edx
0040D7C5 mov dl,byte ptr (0040d840)[eax]
0040D7CB jmp dword ptr [edx*4+40D82Ch]
小总结当case不连续时顺序也并不影响其反汇编代码的生成结果 当case中的最大差值大于等于FF时,汇编会转变为采用了多次判断跳转的方式,变得和if else没有实质性区别
总结总流程图通过前面的分析,就可以完善最开始Switch语句不同情况的结果了 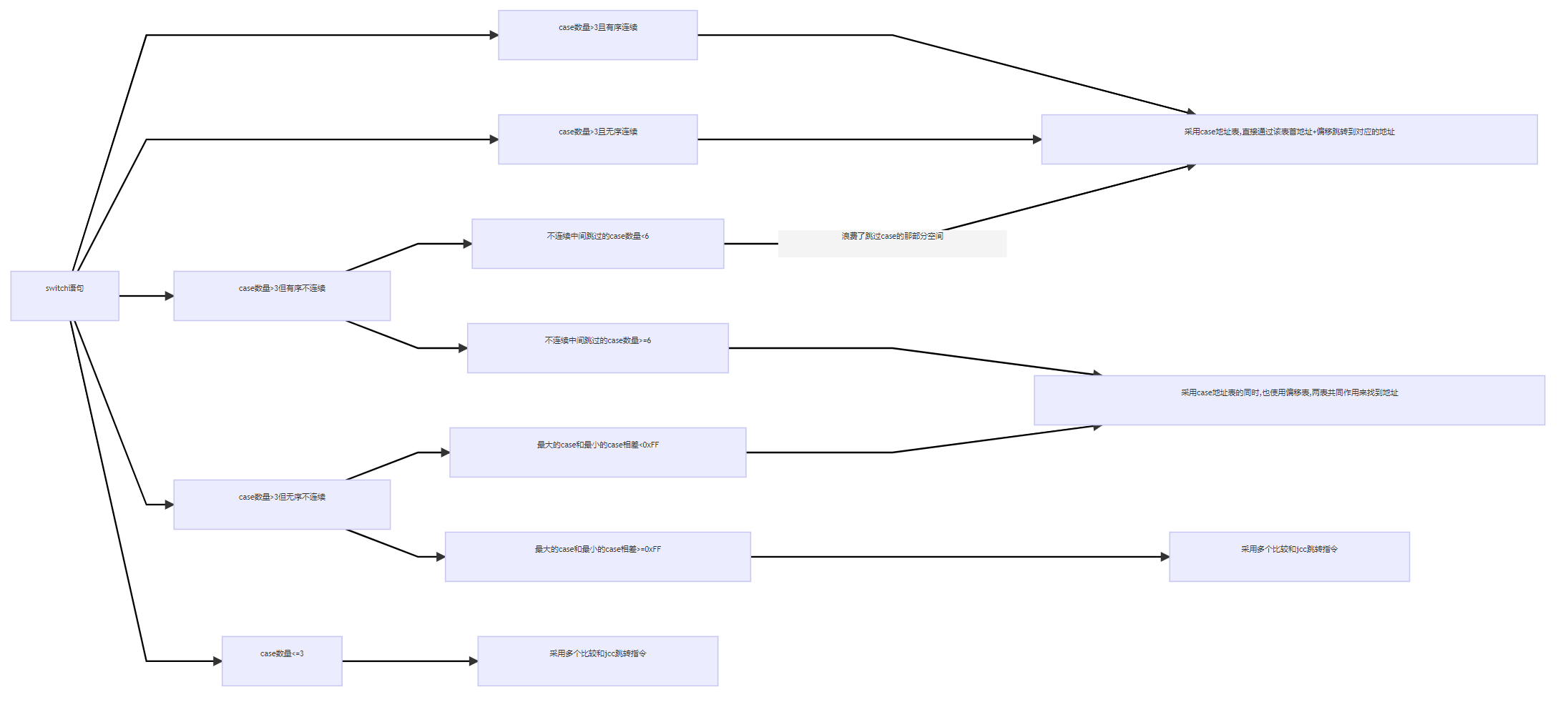
可以看到,虽然switch分的情况不少,但其反汇编的结果只有3种,无非是: - 采用多个比较和jcc跳转指令
- 采用case地址表,直接通过该表首地址+偏移跳转到对应的地址
- 采用case地址表的同时,也使用偏移表,两表共同作用来找到地址
汇总反汇编流程图采用多个比较和jcc跳转指令
采用case地址表
采用case地址表和偏移表
比较if else和switch case通过前面的分析可以得出结论: 当switch语句中的case数量≤3或case中的最大数值和最小数值相差≥6时,两种语句的效率几乎相同 其它情况下一般为switch语句的效率更高 当switch语句有序且连续且case数量>3时,其运行的效率最高,也解释了开发过程中为什么要使用连续的case
版权声明:本文由 lyl610abc 原创,欢迎分享本文,转载请保留出处
|
 发表于 2021-03-14 23:27
发表于 2021-03-14 23:27





 评分
评分 顶
顶 踩
踩 扫码赞助
扫码赞助